
Text Generation#
Deep-learning Language model
Generative model
Based on Chp 8 Deep Learning with Python
Character-based text generative model (using LSTM)
import keras
import numpy as np
## Download texts
path = keras.utils.get_file('nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open(path).read().lower()
print('Corpus Length:', len(text))
Corpus Length: 600893
## Creating sequences for training
maxlen = 60 # 60 characters as one sequence at a time
step = 3 # sample new sequence every 3 characters, shift size
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen]) # context
next_chars.append(text[i + maxlen]) # target word
print('Number of sequences:', len(sentences))
Number of sequences: 200278
## Creating char mapping dictionary
chars = sorted(list(set(text))) # dict of chars
print('Unique characters:', len(chars))
# create a map of each character and its corresponding numeric index in `chars`
char_indices = dict((char, chars.index(char)) for char in chars)
Unique characters: 57
## Vectorizing sequences
print('Vectorization...')
## one-hot encoding for all characters
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]]=1 # i-th sentence, t-th character, one-hot position
y[i, char_indices[next_chars[i]]]=1 # i-th sentence, the target word one-hot position
Vectorization...
# ## Building Network
# from keras import layers
# model = keras.models.Sequential()
# model.add(layers.LSTM(128, input_shape=(maxlen, len(chars))))
# model.add(layers.Dense(len(chars), activation='softmax'))
# ## Model configuration
# optimizer = keras.optimizers.RMSprop(lr=0.001)
# model.compile(loss='categorical_crossentropy', optimizer=optimizer)
## After the training, a function to sample the next char given the model prediction
def sample(preds, temperature = 1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds)/temperature
exp_preds = np.exp(preds)
preds = exp_preds/np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
## Model Training
# history = model.fit(x, y, batch_size=128, epochs = 60)
## Save model
# model.save('../data/text-gen-lstm-nietzsche.h5')
# print(history.history.keys())
# loss_values = history.history['loss']
# epochs = range(1, len(loss_values)+1)
import seaborn as sns
import pandas as pd
import pickle
%matplotlib inline
## load previous saved df
pickle_in = open("../data/text-gen-lstm-nietzschet-history.pickle","rb")
hist_df = pickle.load(pickle_in)
#hist_df=pd.DataFrame(list(zip(epochs, loss_values)), columns=['epochs','loss_values'])
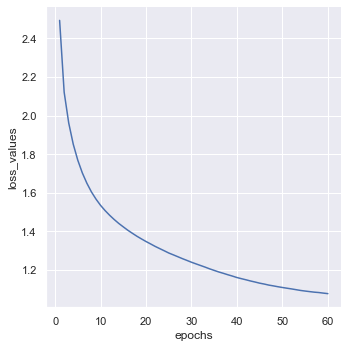
sns.set(style='darkgrid')
sns.relplot(data=hist_df,x='epochs', y='loss_values', kind='line')
<seaborn.axisgrid.FacetGrid at 0x7fe0ed3eead0>
# import pickle
# pickle_out = open("../data/text-gen-lstm-nietzschet-history.pickle","wb")
# pickle.dump(hist_df, pickle_out)
# pickle_out.close()
## Load Saved Model
## No need to create and compile the model first?
model = keras.models.load_model('../data/text-gen-lstm-nietzsche.h5')
## Generating Texts
import random
import sys
start_index = random.randint(0, len(text)-maxlen-1)
generated_text = text[start_index:start_index+maxlen]
print('--Generating with seed: "'+ generated_text + '"')
for temperature in [0.2, 0.5, 1.0, 1.2]:
print('----- temperature:', temperature)
sys.stdout.write(generated_text)
# generate 400 chars after the seed text
for i in range(200):
# one-hot encoding seed text
sampled = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated_text):
sampled[0, t, char_indices[char]]=1 # given the sample text, t-th char, one-hot position
preds = model.predict(sampled, verbose=0)[0] # get output prob distribution
next_index = sample(preds, temperature) # choose the char based on temperature
next_char = chars[next_index]
generated_text += next_char # append the new char
generated_text = generated_text[1:] # get rid of the first char
sys.stdout.write(next_char)
--Generating with seed: " everything that has heretofore made metaphysical assumption"
----- temperature: 0.2
everything that has heretofore made metaphysical assumption of the
same spirit, the present deeply before a his spirit as i succing of the existence from the
intellectual condition to be a profound in the fact of a religion of the
soul modern cause of the sam----- temperature: 0.5
n the fact of a religion of the
soul modern cause of the same will be attained to be souch to have been to
dut about, also a mester it is a point, in the end of the spirit,
which such an indispreneded, and for the subtle meass of a man who induder
be believed ----- temperature: 1.0
, and for the subtle meass of a man who induder
be believed toble itself is rearly developidly inexistencelizes by
lake always themselves just acqusowhed has not the german himselop. the
hownelighing elogence by the world with of a comp" with and more
morality----- temperature: 1.2
elogence by the world with of a comp" with and more
morality, the proseemy no adabl. the even and find now besing,
succtraborions.--swas do the past of his own lory as samethicas of puriops from the "xh"-gove
and "trad the love of lifered higherble, in which w