
Seqeunce Model with Attention for Addition Learning#
Use seq-to-seq model to learn mathematical addition based on data
This is based on Chapter 7 of Deep Learning 2用 Python 進行自然語言處理的基礎理論實作.
This notebook uses two types of Attention layers:
The first type is the default
keras.layers.Attention(Luong attention) andkeras.layers.AdditiveAttention(Bahdanau attention). (But these layers have ONLY been implemented in Tensorflow-nightly.The second type is developed by Thushan.
Bahdanau Attention Layber developed in Thushan
Thushan Ganegedara’s Attention in Deep Networks with Keras
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
import os
os.chdir('/content/drive/My Drive/_MySyncDrive/Repository/python-notes/nlp')
%pwd
'/content/drive/My Drive/_MySyncDrive/Repository/python-notes/nlp'
!pip install tf-nightly
Requirement already satisfied: tf-nightly in /usr/local/lib/python3.6/dist-packages (2.5.0.dev20201029)
Requirement already satisfied: flatbuffers~=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.12)
Requirement already satisfied: typing-extensions~=3.7.4 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.7.4.3)
Requirement already satisfied: six~=1.15.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.15.0)
Requirement already satisfied: tb-nightly~=2.4.0.a in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.4.0a20201102)
Requirement already satisfied: tf-estimator-nightly~=2.4.0.dev in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.4.0.dev2020102301)
Requirement already satisfied: opt-einsum~=3.3.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.3.0)
Requirement already satisfied: absl-py~=0.10 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.10.0)
Requirement already satisfied: wheel~=0.35 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.35.1)
Requirement already satisfied: wrapt~=1.12.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.12.1)
Requirement already satisfied: grpcio~=1.32.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.32.0)
Requirement already satisfied: protobuf~=3.13.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.13.0)
Requirement already satisfied: numpy~=1.19.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.19.4)
Requirement already satisfied: google-pasta~=0.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.2.0)
Requirement already satisfied: astunparse~=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.6.3)
Requirement already satisfied: gast==0.3.3 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.3.3)
Requirement already satisfied: keras-preprocessing~=1.1.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.1.2)
Requirement already satisfied: termcolor~=1.1.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.1.0)
Requirement already satisfied: h5py~=2.10.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.10.0)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.0.1)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (0.4.1)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (3.3.2)
Requirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.17.2)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.7.0)
Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (2.23.0)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (50.3.2)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tb-nightly~=2.4.0.a->tf-nightly) (1.3.0)
Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python3.6/dist-packages (from markdown>=2.6.8->tb-nightly~=2.4.0.a->tf-nightly) (2.0.0)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (4.1.1)
Requirement already satisfied: rsa<5,>=3.1.4; python_version >= "3" in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (4.6)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (0.2.8)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (2020.6.20)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (2.10)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (1.24.3)
Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tb-nightly~=2.4.0.a->tf-nightly) (3.1.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata; python_version < "3.8"->markdown>=2.6.8->tb-nightly~=2.4.0.a->tf-nightly) (3.3.1)
Requirement already satisfied: pyasn1>=0.1.3 in /usr/local/lib/python3.6/dist-packages (from rsa<5,>=3.1.4; python_version >= "3"->google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (0.4.8)
import tensorflow, keras
print(tensorflow.__version__)
print(keras.__version__)
2.5.0-dev20201029
2.4.3
Functions#
import re
import keras
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import Input, LSTM, Dense, GRU
from tensorflow.keras.layers import AdditiveAttention, Attention
import numpy as np
from random import randint
from numpy import array
from numpy import argmax
from numpy import array_equal
from keras import Model
from keras.models import Sequential
from keras.layers import LSTM, GRU, Concatenate
from keras.layers import Attention
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import RepeatVector
from keras import Input
from attention import AttentionLayer
from keras.utils import to_categorical
# Path to the data txt file on disk.
def get_data(data_path, train_test = 0.9):
data_path = '../../../RepositoryData/data/deep-learning-2/addition.txt'
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
enc_text=[l.split('_')[0] for l in lines]
dec_text=[l.split('_')[-1].strip() for l in lines]
dec_text = ['_' + sent + '_' for sent in dec_text]
np.random.seed(123)
inds = np.arange(len(enc_text))
np.random.shuffle(inds)
train_size = int(round(len(lines)*train_test))
train_inds = inds[:train_size]
test_inds = inds[train_size:]
tr_enc_text = [enc_text[ti] for ti in train_inds]
tr_dec_text = [dec_text[ti] for ti in train_inds]
ts_enc_text = [enc_text[ti] for ti in test_inds]
ts_dec_text = [dec_text[ti] for ti in test_inds]
return tr_enc_text, tr_dec_text, ts_enc_text, ts_dec_text
## when the max_len is known, use this func to convert text to seq
def sents2sequences(tokenizer, sentences, reverse=False, pad_length=None, padding_type='post'):
encoded_text = tokenizer.texts_to_sequences(sentences)
preproc_text = pad_sequences(encoded_text, padding=padding_type, maxlen=pad_length)
if reverse:
preproc_text = np.flip(preproc_text, axis=1)
return preproc_text
def preprocess_data(enc_tokenizer, dec_tokenizer, enc_text, dec_text):
enc_seq = enc_tokenizer.texts_to_sequences(tr_enc_text)
enc_timesteps = np.max([len(l) for l in enc_seq])
enc_seq = pad_sequences(enc_seq, padding='post', maxlen = enc_timesteps)
dec_seq = dec_tokenizer.texts_to_sequences(tr_dec_text)
dec_timesteps = np.max([len(l) for l in dec_seq])
dec_seq = pad_sequences(dec_seq, padding='post', maxlen = dec_timesteps)
return enc_seq, dec_seq
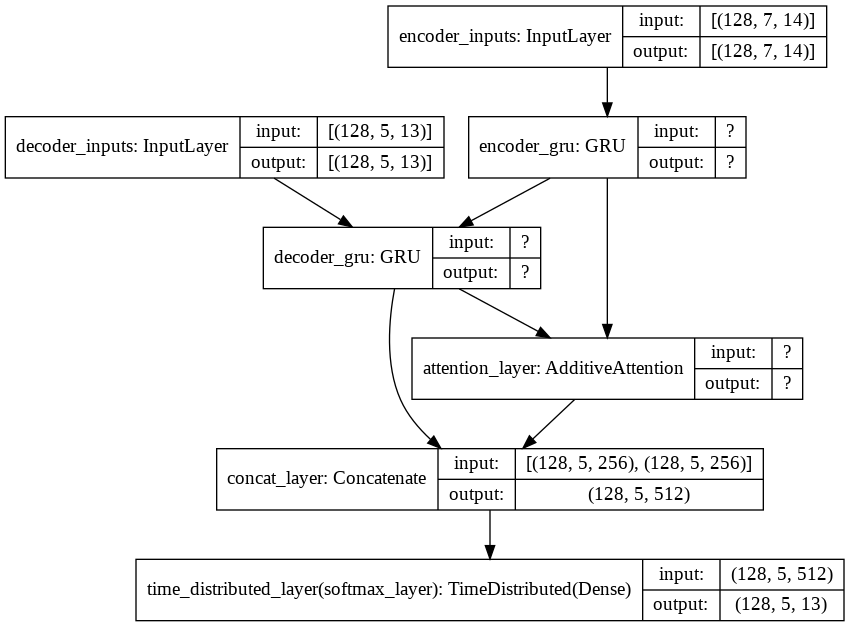
def define_nmt(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a NMT model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder GRU
encoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='encoder_gru')
encoder_out, encoder_state = encoder_gru(encoder_inputs)
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='decoder_gru')
decoder_out, decoder_state = decoder_gru(decoder_inputs, initial_state=encoder_state)
# Attention layer
# attn_layer = AttentionLayer(name='attention_layer')
attn_layer = AdditiveAttention(name="attention_layer")
## The input for AdditiveAttention: query, key
## It returns a tensor of shape as query
## This is different from the AttentionLayer developed by Thushan
# attn_out, attn_states = attn_layer([encoder_out, decoder_out])
attn_out, attn_states = attn_layer([decoder_out,encoder_out],return_attention_scores=True)
# Concat attention input and decoder GRU output
decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_out, attn_out])
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_concat_input)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
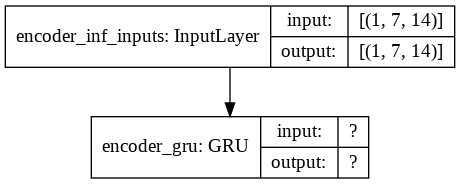
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_state = encoder_gru(encoder_inf_inputs)
encoder_model = Model(inputs=encoder_inf_inputs, outputs=[encoder_inf_out, encoder_inf_state])
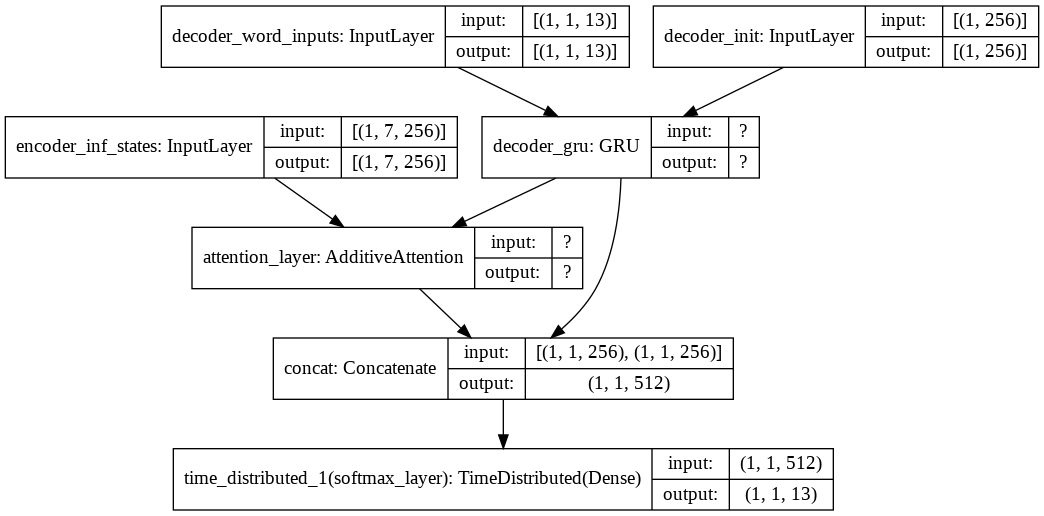
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize), name='decoder_word_inputs')
encoder_inf_states = Input(batch_shape=(batch_size, enc_timesteps, hidden_size), name='encoder_inf_states')
decoder_init_state = Input(batch_shape=(batch_size, hidden_size), name='decoder_init')
decoder_inf_out, decoder_inf_state = decoder_gru(decoder_inf_inputs, initial_state=decoder_init_state)
# attn_inf_out, attn_inf_states = attn_layer([encoder_inf_states, decoder_inf_out])
attn_inf_out, attn_inf_states = attn_layer([decoder_inf_out, encoder_inf_states],return_attention_scores=True)
decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_concat)
decoder_model = Model(inputs=[encoder_inf_states, decoder_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred, attn_inf_states, decoder_inf_state])
return full_model, encoder_model, decoder_model
def train(full_model, enc_seq, dec_seq, batch_size, n_epochs=10):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
def infer_nmt(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
"""
Infer logic
:param encoder_model: keras.Model
:param decoder_model: keras.Model
:param test_en_seq: sequence of word ids
:param en_vsize: int
:param fr_vsize: int
:return:
"""
test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
enc_outs, enc_last_state = encoder_model.predict(test_enc_onehot_seq)
dec_state = enc_last_state
attention_weights = []
dec_text = ''
for i in range(dec_timesteps):
dec_out, attention, dec_state = decoder_model.predict(
[enc_outs, dec_state, test_dec_onehot_seq])
dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
if dec_ind == 0:
break
test_dec_seq = sents2sequences(
dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
attention_weights.append((dec_ind, attention))
dec_text += dec_index2word[dec_ind]
return dec_text, attention_weights
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=["PingFang HK"]
def plot_attention_weights(encoder_inputs, attention_weights, enc_id2word, dec_id2word, filename=None):
"""
Plots attention weights
:param encoder_inputs: Sequence of word ids (list/numpy.ndarray)
:param attention_weights: Sequence of (<word_id_at_decode_step_t>:<attention_weights_at_decode_step_t>)
:param en_id2word: dict
:param fr_id2word: dict
:return:
"""
if len(attention_weights) == 0:
print('Your attention weights was empty. No attention map saved to the disk. ' +
'\nPlease check if the decoder produced a proper translation')
return
mats = []
dec_inputs = []
for dec_ind, attn in attention_weights:
mats.append(attn.reshape(-1))
dec_inputs.append(dec_ind)
attention_mat = np.transpose(np.array(mats))
fig, ax = plt.subplots(figsize=(32, 32))
ax.imshow(attention_mat)
ax.set_xticks(np.arange(attention_mat.shape[1]))
ax.set_yticks(np.arange(attention_mat.shape[0]))
ax.set_xticklabels([dec_id2word[inp] if inp != 0 else "<Res>" for inp in dec_inputs])
ax.set_yticklabels([enc_id2word[inp] if inp != 0 else "<Res>" for inp in encoder_inputs.ravel()])
ax.tick_params(labelsize=32)
ax.tick_params(axis='x', labelrotation=90)
# if not os.path.exists(config.RESULTS_DIR):
# os.mkdir(config.RESULTS_DIR)
# if filename is None:
# plt.savefig( 'attention.png'))
# else:
# plt.savefig(os.path.join(config.RESULTS_DIR, '{}'.format(filename)))
Main Program#
Data Wrangling and Training#
#### hyperparameters
batch_size = 128
hidden_size = 256
n_epochs = 50
### Get data
tr_enc_text, tr_dec_text, ts_enc_text, ts_dec_text = get_data(data_path='../../../RepositoryData/data/deep-learning-2/addition.txt')
# """ Defining tokenizers """
enc_tokenizer = keras.preprocessing.text.Tokenizer(oov_token='UNK', char_level=True)
enc_tokenizer.fit_on_texts(tr_enc_text)
dec_tokenizer = keras.preprocessing.text.Tokenizer(oov_token='UNK', char_level=True)
dec_tokenizer.fit_on_texts(tr_dec_text)
# ### Getting sequence integer data
enc_seq, dec_seq = preprocess_data(enc_tokenizer, dec_tokenizer, tr_enc_text, tr_dec_text)
# ### timestesps
enc_timesteps = enc_seq.shape[1]
dec_timesteps = dec_seq.shape[1]
# ### vocab size
enc_vsize = max(enc_tokenizer.index_word.keys()) + 1
dec_vsize = max(dec_tokenizer.index_word.keys()) + 1
print(enc_vsize)
print(dec_vsize)
print(tr_enc_text[:5])
print(tr_dec_text[:5])
14
13
['27+673 ', '153+27 ', '93+901 ', '243+678', '269+46 ']
['_700_', '_180_', '_994_', '_921_', '_315_']
###""" Defining the full model """
full_model, infer_enc_model, infer_dec_model = define_nmt(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
Model: "model_3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 7, 14)] 0
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 5, 13)] 0
__________________________________________________________________________________________________
encoder_gru (GRU) [(128, 7, 256), (128 208896 encoder_inputs[0][0]
__________________________________________________________________________________________________
decoder_gru (GRU) [(128, 5, 256), (128 208128 decoder_inputs[0][0]
encoder_gru[0][1]
__________________________________________________________________________________________________
attention_layer (AdditiveAttent ((128, 5, 256), (128 256 decoder_gru[0][0]
encoder_gru[0][0]
__________________________________________________________________________________________________
concat_layer (Concatenate) (128, 5, 512) 0 decoder_gru[0][0]
attention_layer[0][0]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 5, 13) 6669 concat_layer[0][0]
==================================================================================================
Total params: 423,949
Trainable params: 423,949
Non-trainable params: 0
__________________________________________________________________________________________________
from keras.utils import plot_model
plot_model(full_model, show_shapes=True)
%%time
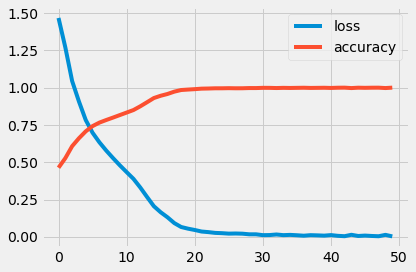
loss, accuracy = train(full_model, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 1.466877539952596/0.4631009607912808
Loss/Accuracy in epoch 2: 1.2697382407989937/0.5272079769023124
Loss/Accuracy in epoch 3: 1.044164922332492/0.6073628906850461
Loss/Accuracy in epoch 4: 0.9069581612562522/0.660710469949619
Loss/Accuracy in epoch 5: 0.7824556773204749/0.707051280217293
Loss/Accuracy in epoch 6: 0.6974543691360713/0.7420272439972967
Loss/Accuracy in epoch 7: 0.6336102271691347/0.7654691960057641
Loss/Accuracy in epoch 8: 0.5783972347903455/0.7827590814343205
Loss/Accuracy in epoch 9: 0.5278063926771496/0.799149751663208
Loss/Accuracy in epoch 10: 0.4793944070991288/0.8159989307069371
Loss/Accuracy in epoch 11: 0.4336995489237315/0.8327946934604916
Loss/Accuracy in epoch 12: 0.38870076491282535/0.8496527773702246
Loss/Accuracy in epoch 13: 0.33074596914810334/0.8746616797909098
Loss/Accuracy in epoch 14: 0.2669906813194949/0.9021768145411783
Loss/Accuracy in epoch 15: 0.20507387239539046/0.9301415607120916
Loss/Accuracy in epoch 16: 0.16458575024224414/0.9454727558328895
Loss/Accuracy in epoch 17: 0.13092277069546898/0.9573851496066124
Loss/Accuracy in epoch 18: 0.09199842031609978/0.9730279550932751
Loss/Accuracy in epoch 19: 0.06590711166206588/0.9839075873380373
Loss/Accuracy in epoch 20: 0.05472505392979013/0.9869747160167096
Loss/Accuracy in epoch 21: 0.04579046688591822/0.9896857195090704
Loss/Accuracy in epoch 22: 0.035458232331861794/0.9930689103922613
Loss/Accuracy in epoch 23: 0.03149520015168903/0.9940393517839263
Loss/Accuracy in epoch 24: 0.02630004143220322/0.9954460472123235
Loss/Accuracy in epoch 25: 0.024424095444402463/0.9954994682572845
Loss/Accuracy in epoch 26: 0.021367484719580054/0.9962829438030211
Loss/Accuracy in epoch 27: 0.022244544561814378/0.9955484357654539
Loss/Accuracy in epoch 28: 0.020996267488093627/0.9957487554292054
Loss/Accuracy in epoch 29: 0.016814602118388793/0.9970753247242028
Loss/Accuracy in epoch 30: 0.01679201596190999/0.9969595830325048
Loss/Accuracy in epoch 31: 0.011167272943950276/0.9985443450446821
Loss/Accuracy in epoch 32: 0.01185952270525558/0.9983573771609879
Loss/Accuracy in epoch 33: 0.015559469848510376/0.9971465497275024
Loss/Accuracy in epoch 34: 0.01123865023441082/0.998450861187742
Loss/Accuracy in epoch 35: 0.012896456733144332/0.9977074501521227
Loss/Accuracy in epoch 36: 0.010563542923102012/0.9984107958285557
Loss/Accuracy in epoch 37: 0.007418496470548149/0.9991319497086724
Loss/Accuracy in epoch 38: 0.011061391351410212/0.9979478326278535
Loss/Accuracy in epoch 39: 0.009776254030650328/0.9984018928305036
Loss/Accuracy in epoch 40: 0.007885117380298737/0.999002854538779
Loss/Accuracy in epoch 41: 0.011514589942705173/0.9977786748157946
Loss/Accuracy in epoch 42: 0.006666279525265225/0.9992699488955006
Loss/Accuracy in epoch 43: 0.0041240223662190115/0.9997284580499698
Loss/Accuracy in epoch 44: 0.013560339155078911/0.9969506793551974
Loss/Accuracy in epoch 45: 0.005581353744624601/0.9994524608650098
Loss/Accuracy in epoch 46: 0.008251662561776079/0.9985666010114882
Loss/Accuracy in epoch 47: 0.005656291492896266/0.9993856880399916
Loss/Accuracy in epoch 48: 0.0038713078051699364/0.9995949105319814
Loss/Accuracy in epoch 49: 0.013122531853382744/0.9970664217261507
Loss/Accuracy in epoch 50: 0.00293226670832015/0.9998620033603788
CPU times: user 57min 21s, sys: 2min 50s, total: 1h 12s
Wall time: 37min 44s
plt.style.use('fivethirtyeight')
plt.plot(range(len(loss)), loss, label='loss')
plt.plot(range(len(accuracy)), accuracy, label='accuracy')
plt.legend()
plt.tight_layout()
plt.show()
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
Model Saving#
# full_model.save('../../../RepositoryData/output/seq2seq-attention-addition/full-model.h5')
# infer_enc_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-enc-model.h5')
# infer_dec_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-dec-model.h5')
Prediction#
full_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/full-model.h5')
infer_enc_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/infer-enc-model.h5')
infer_dec_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/infer-dec-model.h5')
plot_model(infer_enc_model,show_shapes=True)
plot_model(infer_dec_model, show_shapes=True)
""" Index2word """
enc_index2word = dict(
zip(enc_tokenizer.word_index.values(), enc_tokenizer.word_index.keys()))
dec_index2word = dict(
zip(dec_tokenizer.word_index.values(), dec_tokenizer.word_index.keys()))
def translate(infer_enc_model, infer_dec_model, test_enc_text,
enc_vsize, dec_vsize, enc_timesteps, dec_timesteps,
enc_tokenizer, dec_tokenizer):
""" Inferring with trained model """
test_enc = test_enc_text
print('Translating: {}'.format(test_enc))
test_enc_seq = sents2sequences(
enc_tokenizer, [test_enc], pad_length=enc_timesteps)
test_dec, attn_weights = infer_nmt(
encoder_model=infer_enc_model, decoder_model=infer_dec_model,
test_enc_seq=test_enc_seq, enc_vsize=enc_vsize, dec_vsize=dec_vsize, dec_timesteps = dec_timesteps)
print('\tFrench: {}'.format(test_dec))
return test_enc_seq, test_dec, attn_weights
test_enc_seq, test_dec, attn_weights=translate(infer_enc_model=infer_enc_model,
infer_dec_model=infer_dec_model,
test_enc_text=ts_enc_text[120],
enc_vsize=enc_vsize,
dec_vsize=dec_vsize,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_tokenizer=enc_tokenizer,
dec_tokenizer=dec_tokenizer)
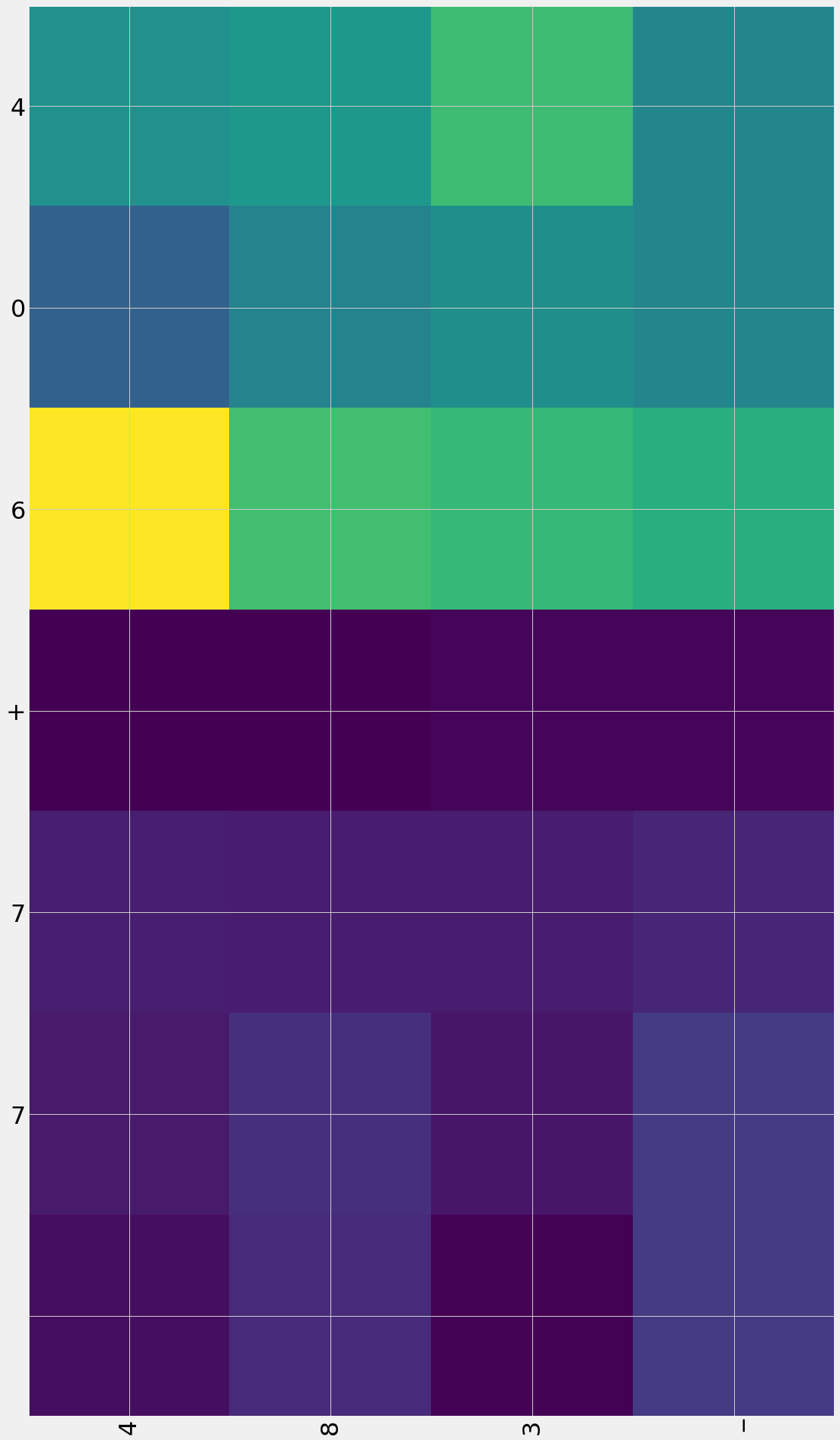
Translating: 406+77
French: 483_
""" Attention plotting """
plot_attention_weights(test_enc_seq, attn_weights,
enc_index2word, dec_index2word)
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
print(tr_enc_text[:5])
print(tr_dec_text[:5])
['27+673 ', '153+27 ', '93+901 ', '243+678', '269+46 ']
['_700_', '_180_', '_994_', '_921_', '_315_']
Evaluation on Test Data#
def test(full_model, ts_enc_text, ts_dec_text, enc_tokenizer, dec_tokenizer, batch_size):
# ### Getting sequence integer data
ts_enc_seq, ts_dec_seq = preprocess_data(enc_tokenizer, dec_tokenizer, ts_enc_text, ts_dec_text)
losses = []
accuracies = []
for bi in range(0, ts_enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
ts_enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
ts_dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
# full_model.train_on_batch(
# [enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
print('Average Loss:{}'.format(np.mean(losses)))
print('Average Accuracy:{}'.format(np.mean(accuracies)))
test(full_model, ts_enc_text = ts_enc_text, ts_dec_text = ts_dec_text,
enc_tokenizer = enc_tokenizer, dec_tokenizer = dec_tokenizer, batch_size = batch_size)
Average Loss:0.0022864048634562905
Average Accuracy:0.9996527823967132