
Sentiment Analysis Using BERT#
This notebook runs on Google Colab
Using
ktrainfor modelingThe ktrain library is a lightweight wrapper for tf.keras in TensorFlow 2, which is “designed to make deep learning and AI more accessible and easier to apply for beginners and domain experts”.
Easy to implement BERT-like pre-trained language models
This notebook works on sentiment analysis of Chinese movie reviews, which is a small dataset. I would like to see to what extent the transformers are effective when dealing with relatively smaller training set. This in turn shows us the powerful advantages of transfer learning.
Installing ktrain#
!pip install ktrain
Collecting ktrain
?25l Downloading https://files.pythonhosted.org/packages/f2/d5/a366ea331fc951b8ec2c9e7811cd101acfcac3a5d045f9d9320e74ea5f70/ktrain-0.21.4.tar.gz (25.3MB)
|████████████████████████████████| 25.3MB 129kB/s
?25hRequirement already satisfied: scikit-learn>=0.21.3 in /usr/local/lib/python3.6/dist-packages (from ktrain) (0.22.2.post1)
Requirement already satisfied: matplotlib>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from ktrain) (3.2.2)
Requirement already satisfied: pandas>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from ktrain) (1.1.2)
Requirement already satisfied: fastprogress>=0.1.21 in /usr/local/lib/python3.6/dist-packages (from ktrain) (1.0.0)
Collecting keras_bert>=0.86.0
Downloading https://files.pythonhosted.org/packages/e2/7f/95fabd29f4502924fa3f09ff6538c5a7d290dfef2c2fe076d3d1a16e08f0/keras-bert-0.86.0.tar.gz
Requirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from ktrain) (2.23.0)
Requirement already satisfied: joblib in /usr/local/lib/python3.6/dist-packages (from ktrain) (0.16.0)
Collecting langdetect
?25l Downloading https://files.pythonhosted.org/packages/56/a3/8407c1e62d5980188b4acc45ef3d94b933d14a2ebc9ef3505f22cf772570/langdetect-1.0.8.tar.gz (981kB)
|████████████████████████████████| 983kB 48.9MB/s
?25hRequirement already satisfied: jieba in /usr/local/lib/python3.6/dist-packages (from ktrain) (0.42.1)
Collecting cchardet
?25l Downloading https://files.pythonhosted.org/packages/1e/c5/7e1a0d7b4afd83d6f8de794fce82820ec4c5136c6d52e14000822681a842/cchardet-2.1.6-cp36-cp36m-manylinux2010_x86_64.whl (241kB)
|████████████████████████████████| 245kB 49.5MB/s
?25hRequirement already satisfied: networkx>=2.3 in /usr/local/lib/python3.6/dist-packages (from ktrain) (2.5)
Requirement already satisfied: bokeh in /usr/local/lib/python3.6/dist-packages (from ktrain) (2.1.1)
Collecting seqeval
Downloading https://files.pythonhosted.org/packages/d8/9d/89d9ac5d6506f8368ba5ae53b054cf26bf796935eff6a1945431c7a5d485/seqeval-0.0.17.tar.gz
Requirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from ktrain) (20.4)
Collecting transformers>=3.1.0
?25l Downloading https://files.pythonhosted.org/packages/19/22/aff234f4a841f8999e68a7a94bdd4b60b4cebcfeca5d67d61cd08c9179de/transformers-3.3.1-py3-none-any.whl (1.1MB)
|████████████████████████████████| 1.1MB 49.2MB/s
?25hRequirement already satisfied: ipython in /usr/local/lib/python3.6/dist-packages (from ktrain) (5.5.0)
Collecting syntok
Downloading https://files.pythonhosted.org/packages/8c/76/a49e73a04b3e3a14ce232e8e28a1587f8108baa665644fe8c40e307e792e/syntok-1.3.1.tar.gz
Collecting whoosh
?25l Downloading https://files.pythonhosted.org/packages/ba/19/24d0f1f454a2c1eb689ca28d2f178db81e5024f42d82729a4ff6771155cf/Whoosh-2.7.4-py2.py3-none-any.whl (468kB)
|████████████████████████████████| 471kB 49.2MB/s
?25hRequirement already satisfied: numpy>=1.11.0 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.21.3->ktrain) (1.18.5)
Requirement already satisfied: scipy>=0.17.0 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.21.3->ktrain) (1.4.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0.0->ktrain) (1.2.0)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0.0->ktrain) (2.8.1)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0.0->ktrain) (2.4.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0.0->ktrain) (0.10.0)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=1.0.1->ktrain) (2018.9)
Requirement already satisfied: Keras>=2.4.3 in /usr/local/lib/python3.6/dist-packages (from keras_bert>=0.86.0->ktrain) (2.4.3)
Collecting keras-transformer>=0.38.0
Downloading https://files.pythonhosted.org/packages/89/6c/d6f0c164f4cc16fbc0d0fea85f5526e87a7d2df7b077809e422a7e626150/keras-transformer-0.38.0.tar.gz
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->ktrain) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->ktrain) (2020.6.20)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->ktrain) (1.24.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->ktrain) (3.0.4)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from langdetect->ktrain) (1.15.0)
Requirement already satisfied: decorator>=4.3.0 in /usr/local/lib/python3.6/dist-packages (from networkx>=2.3->ktrain) (4.4.2)
Requirement already satisfied: tornado>=5.1 in /usr/local/lib/python3.6/dist-packages (from bokeh->ktrain) (5.1.1)
Requirement already satisfied: Jinja2>=2.7 in /usr/local/lib/python3.6/dist-packages (from bokeh->ktrain) (2.11.2)
Requirement already satisfied: PyYAML>=3.10 in /usr/local/lib/python3.6/dist-packages (from bokeh->ktrain) (3.13)
Requirement already satisfied: pillow>=4.0 in /usr/local/lib/python3.6/dist-packages (from bokeh->ktrain) (7.0.0)
Requirement already satisfied: typing-extensions>=3.7.4 in /usr/local/lib/python3.6/dist-packages (from bokeh->ktrain) (3.7.4.3)
Collecting sentencepiece!=0.1.92
?25l Downloading https://files.pythonhosted.org/packages/d4/a4/d0a884c4300004a78cca907a6ff9a5e9fe4f090f5d95ab341c53d28cbc58/sentencepiece-0.1.91-cp36-cp36m-manylinux1_x86_64.whl (1.1MB)
|████████████████████████████████| 1.1MB 49.9MB/s
?25hCollecting sacremoses
?25l Downloading https://files.pythonhosted.org/packages/7d/34/09d19aff26edcc8eb2a01bed8e98f13a1537005d31e95233fd48216eed10/sacremoses-0.0.43.tar.gz (883kB)
|████████████████████████████████| 890kB 43.0MB/s
?25hRequirement already satisfied: filelock in /usr/local/lib/python3.6/dist-packages (from transformers>=3.1.0->ktrain) (3.0.12)
Requirement already satisfied: dataclasses; python_version < "3.7" in /usr/local/lib/python3.6/dist-packages (from transformers>=3.1.0->ktrain) (0.7)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.6/dist-packages (from transformers>=3.1.0->ktrain) (4.41.1)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.6/dist-packages (from transformers>=3.1.0->ktrain) (2019.12.20)
Collecting tokenizers==0.8.1.rc2
?25l Downloading https://files.pythonhosted.org/packages/80/83/8b9fccb9e48eeb575ee19179e2bdde0ee9a1904f97de5f02d19016b8804f/tokenizers-0.8.1rc2-cp36-cp36m-manylinux1_x86_64.whl (3.0MB)
|████████████████████████████████| 3.0MB 45.9MB/s
?25hRequirement already satisfied: setuptools>=18.5 in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (50.3.0)
Requirement already satisfied: pickleshare in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (0.7.5)
Requirement already satisfied: pexpect; sys_platform != "win32" in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (4.8.0)
Requirement already satisfied: prompt-toolkit<2.0.0,>=1.0.4 in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (1.0.18)
Requirement already satisfied: simplegeneric>0.8 in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (0.8.1)
Requirement already satisfied: pygments in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (2.6.1)
Requirement already satisfied: traitlets>=4.2 in /usr/local/lib/python3.6/dist-packages (from ipython->ktrain) (4.3.3)
Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from Keras>=2.4.3->keras_bert>=0.86.0->ktrain) (2.10.0)
Collecting keras-pos-embd>=0.11.0
Downloading https://files.pythonhosted.org/packages/09/70/b63ed8fc660da2bb6ae29b9895401c628da5740c048c190b5d7107cadd02/keras-pos-embd-0.11.0.tar.gz
Collecting keras-multi-head>=0.27.0
Downloading https://files.pythonhosted.org/packages/e6/32/45adf2549450aca7867deccfa04af80a0ab1ca139af44b16bc669e0e09cd/keras-multi-head-0.27.0.tar.gz
Collecting keras-layer-normalization>=0.14.0
Downloading https://files.pythonhosted.org/packages/a4/0e/d1078df0494bac9ce1a67954e5380b6e7569668f0f3b50a9531c62c1fc4a/keras-layer-normalization-0.14.0.tar.gz
Collecting keras-position-wise-feed-forward>=0.6.0
Downloading https://files.pythonhosted.org/packages/e3/59/f0faa1037c033059e7e9e7758e6c23b4d1c0772cd48de14c4b6fd4033ad5/keras-position-wise-feed-forward-0.6.0.tar.gz
Collecting keras-embed-sim>=0.8.0
Downloading https://files.pythonhosted.org/packages/57/ef/61a1e39082c9e1834a2d09261d4a0b69f7c818b359216d4e1912b20b1c86/keras-embed-sim-0.8.0.tar.gz
Requirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.6/dist-packages (from Jinja2>=2.7->bokeh->ktrain) (1.1.1)
Requirement already satisfied: click in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers>=3.1.0->ktrain) (7.1.2)
Requirement already satisfied: ptyprocess>=0.5 in /usr/local/lib/python3.6/dist-packages (from pexpect; sys_platform != "win32"->ipython->ktrain) (0.6.0)
Requirement already satisfied: wcwidth in /usr/local/lib/python3.6/dist-packages (from prompt-toolkit<2.0.0,>=1.0.4->ipython->ktrain) (0.2.5)
Requirement already satisfied: ipython-genutils in /usr/local/lib/python3.6/dist-packages (from traitlets>=4.2->ipython->ktrain) (0.2.0)
Collecting keras-self-attention==0.46.0
Downloading https://files.pythonhosted.org/packages/15/6b/c804924a056955fa1f3ff767945187103cfc851ba9bd0fc5a6c6bc18e2eb/keras-self-attention-0.46.0.tar.gz
Building wheels for collected packages: ktrain, keras-bert, langdetect, seqeval, syntok, keras-transformer, sacremoses, keras-pos-embd, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-self-attention
Building wheel for ktrain (setup.py) ... ?25l?25hdone
Created wheel for ktrain: filename=ktrain-0.21.4-cp36-none-any.whl size=25270024 sha256=b5d94e83dd30dc5e0cee64f8d9c476a22db5eb7da93af886e3743f20c68b6869
Stored in directory: /root/.cache/pip/wheels/e8/b6/c2/a730bb7727f9402827eb9cdd277a527a4a88acb2b0d22f06f0
Building wheel for keras-bert (setup.py) ... ?25l?25hdone
Created wheel for keras-bert: filename=keras_bert-0.86.0-cp36-none-any.whl size=34145 sha256=9ce5dfdb69ba2a17597d4aae36c73c2833fd192bf5584923776ea4db072b4d93
Stored in directory: /root/.cache/pip/wheels/66/f0/b1/748128b58562fc9e31b907bb5e2ab6a35eb37695e83911236b
Building wheel for langdetect (setup.py) ... ?25l?25hdone
Created wheel for langdetect: filename=langdetect-1.0.8-cp36-none-any.whl size=993195 sha256=452921aad7f0fa71a0a675f05753c83733eec8219da2b0852d2fee1c54a5a8bc
Stored in directory: /root/.cache/pip/wheels/8d/b3/aa/6d99de9f3841d7d3d40a60ea06e6d669e8e5012e6c8b947a57
Building wheel for seqeval (setup.py) ... ?25l?25hdone
Created wheel for seqeval: filename=seqeval-0.0.17-cp36-none-any.whl size=7640 sha256=418a9c8700c05dc4b7c179bcb8fb565e38c2327549228ebbb6616c3b536e0d12
Stored in directory: /root/.cache/pip/wheels/6a/c8/cf/7b9d5d52984c08ce4d27d6f858a682ef74a3738f43f489166a
Building wheel for syntok (setup.py) ... ?25l?25hdone
Created wheel for syntok: filename=syntok-1.3.1-cp36-none-any.whl size=20919 sha256=4756adcf1e33d309eb576663e9c4e35e9555afdfea473cc9a5ed157fff27799c
Stored in directory: /root/.cache/pip/wheels/51/c6/a4/be1920586c49469846bcd2888200bdecfe109ec421dab9be2d
Building wheel for keras-transformer (setup.py) ... ?25l?25hdone
Created wheel for keras-transformer: filename=keras_transformer-0.38.0-cp36-none-any.whl size=12942 sha256=5696a99ee4c1ecb7bd072d5a53192bc7f68c34461f847144283aa4034374d4df
Stored in directory: /root/.cache/pip/wheels/e5/fb/3a/37b2b9326c799aa010ae46a04ddb04f320d8c77c0b7e837f4e
Building wheel for sacremoses (setup.py) ... ?25l?25hdone
Created wheel for sacremoses: filename=sacremoses-0.0.43-cp36-none-any.whl size=893257 sha256=104b0c76271fe04e394fac7fa6369ed52b59d4785fb3b740d958408e0f746e73
Stored in directory: /root/.cache/pip/wheels/29/3c/fd/7ce5c3f0666dab31a50123635e6fb5e19ceb42ce38d4e58f45
Building wheel for keras-pos-embd (setup.py) ... ?25l?25hdone
Created wheel for keras-pos-embd: filename=keras_pos_embd-0.11.0-cp36-none-any.whl size=7554 sha256=32149186fe9e8f532c9104c6cfe4e57b691ee1ffb7b869a671a5d8e809c2189e
Stored in directory: /root/.cache/pip/wheels/5b/a1/a0/ce6b1d49ba1a9a76f592e70cf297b05c96bc9f418146761032
Building wheel for keras-multi-head (setup.py) ... ?25l?25hdone
Created wheel for keras-multi-head: filename=keras_multi_head-0.27.0-cp36-none-any.whl size=15612 sha256=7431cbd7f7986a478fd7a642aea0da819d545be18ed58a6720b3d525ecfa537c
Stored in directory: /root/.cache/pip/wheels/b5/b4/49/0a0c27dcb93c13af02fea254ff51d1a43a924dd4e5b7a7164d
Building wheel for keras-layer-normalization (setup.py) ... ?25l?25hdone
Created wheel for keras-layer-normalization: filename=keras_layer_normalization-0.14.0-cp36-none-any.whl size=5268 sha256=3e568ac688b36f04d28da603f68057323022326cd8f7861e60662a95a54fcccd
Stored in directory: /root/.cache/pip/wheels/54/80/22/a638a7d406fd155e507aa33d703e3fa2612b9eb7bb4f4fe667
Building wheel for keras-position-wise-feed-forward (setup.py) ... ?25l?25hdone
Created wheel for keras-position-wise-feed-forward: filename=keras_position_wise_feed_forward-0.6.0-cp36-none-any.whl size=5626 sha256=2c28f4658965e0022710fa59b0b86b5b03f237fba1ee6516187d604b7ec01642
Stored in directory: /root/.cache/pip/wheels/39/e2/e2/3514fef126a00574b13bc0b9e23891800158df3a3c19c96e3b
Building wheel for keras-embed-sim (setup.py) ... ?25l?25hdone
Created wheel for keras-embed-sim: filename=keras_embed_sim-0.8.0-cp36-none-any.whl size=4559 sha256=513d09467bfe96fd2840e11fa4b551770093fb302ec935ebe144ef1243e7cf21
Stored in directory: /root/.cache/pip/wheels/49/45/8b/c111f6cc8bec253e984677de73a6f4f5d2f1649f42aac191c8
Building wheel for keras-self-attention (setup.py) ... ?25l?25hdone
Created wheel for keras-self-attention: filename=keras_self_attention-0.46.0-cp36-none-any.whl size=17278 sha256=8993ebf2cf413a379708893d0494b85498b3c2aec2cc582b538faf6c573573d2
Stored in directory: /root/.cache/pip/wheels/d2/2e/80/fec4c05eb23c8e13b790e26d207d6e0ffe8013fad8c6bdd4d2
Successfully built ktrain keras-bert langdetect seqeval syntok keras-transformer sacremoses keras-pos-embd keras-multi-head keras-layer-normalization keras-position-wise-feed-forward keras-embed-sim keras-self-attention
Installing collected packages: keras-pos-embd, keras-self-attention, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-transformer, keras-bert, langdetect, cchardet, seqeval, sentencepiece, sacremoses, tokenizers, transformers, syntok, whoosh, ktrain
Successfully installed cchardet-2.1.6 keras-bert-0.86.0 keras-embed-sim-0.8.0 keras-layer-normalization-0.14.0 keras-multi-head-0.27.0 keras-pos-embd-0.11.0 keras-position-wise-feed-forward-0.6.0 keras-self-attention-0.46.0 keras-transformer-0.38.0 ktrain-0.21.4 langdetect-1.0.8 sacremoses-0.0.43 sentencepiece-0.1.91 seqeval-0.0.17 syntok-1.3.1 tokenizers-0.8.1rc2 transformers-3.3.1 whoosh-2.7.4
Importing Libraries#
import tensorflow as tf
import pandas as pd
import numpy as np
import ktrain
from ktrain import text
import tensorflow as tf
tf.__version__
'2.3.0'
Clone Git Repository for Data#
## Will need this if data is available on GitHub
# !git clone https://github.com/laxmimerit/IMDB-Movie-Reviews-Large-Dataset-50k.git
Cloning into 'IMDB-Movie-Reviews-Large-Dataset-50k'...
remote: Enumerating objects: 10, done.
remote: Counting objects: 100% (10/10), done.
remote: Compressing objects: 100% (8/8), done.
remote: Total 10 (delta 1), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (10/10), done.
Data Preparation#
Mount the Google Drive first (manually via the tabs on the left of Google Colab
The default path of the input data csv file is:
GOOGLE_DRIVE_ROOT/ColabData/marc_movie_review_metadata.csv
In BERT, there is no need to do word segmentation. The model takes in the raw reviews as the input.
## loading the train dataset
## change the path if necessary
data = pd.read_csv('/content/drive/My Drive/ColabData/marc_movie_review_metadata.csv', dtype= str)[['reviews','rating']]
data = data.rename(columns={'reviews':'Reviews', 'rating':'Sentiment'})
data.head()
| Reviews | Sentiment | |
|---|---|---|
| 0 | 唉,踩雷了,浪費時間,不推 唉,踩雷了,浪費時間,不推 | negative |
| 1 | 片長三個小時,只有最後半小時能看,前面真的鋪陳太久,我旁邊的都看到打呼 | negative |
| 2 | 史上之最,劇情拖太長,邊看邊想睡覺...... 1.浩克竟然學會跟旁人一起合照。 2.索爾... | negative |
| 3 | 難看死ㄌ 難看死了 難看死ㄌ 看到睡著 拖戲拖很長 爛到爆 | negative |
| 4 | 連續三度睡著,真的演的太好睡了 | negative |
from sklearn.model_selection import train_test_split
data_train, data_test = train_test_split(data, test_size=0.1)
## dimension of the dataset
print("Size of train dataset: ",data_train.shape)
print("Size of test dataset: ",data_test.shape)
#printing last rows of train dataset
data_train.tail()
#printing head rows of test dataset
data_test.head()
Size of train dataset: (2880, 2)
Size of test dataset: (320, 2)
| Reviews | Sentiment | |
|---|---|---|
| 2430 | 刻劃深刻的一部片,會讓人有心痛的感覺。亞瑟雖然有精神疾病,卻也希望用自己的方法帶來歡笑,可惜... | positive |
| 1584 | 看過一次就夠了 如果不是做影評的 何必浪費錢 這就是一部刻意燒腦的電影 沒那麼偉大。 | negative |
| 769 | 給五星的是怎麼回事?純粹政治認同給的分數嗎?純粹以電影評論而已真的不好看,不合邏輯的地方太多... | negative |
| 1631 | 雖然看似輕鬆詼諧劇情\r\n但深刻的撼動內心\r\n推薦給所有韓粉們 | positive |
| 2247 | 很刺激好看超爽!\r\n推薦去電影院看! | positive |
Train-Test Split#
Models supported by transformers library for tensorflow 2:
BERT: bert-base-uncased, bert-large-uncased,bert-base-multilingual-uncased, and others.
DistilBERT: distilbert-base-uncased distilbert-base-multilingual-cased, distilbert-base-german-cased, and others
ALBERT: albert-base-v2, albert-large-v2, and others
RoBERTa: roberta-base, roberta-large, roberta-large-mnli
XLM: xlm-mlm-xnli15–1024, xlm-mlm-100–1280, and others
XLNet: xlnet-base-cased, xlnet-large-cased
# text.texts_from_df return two tuples
# maxlen means it is considering that much words and rest are getting trucated
# preprocess_mode means tokenizing, embedding and transformation of text corpus(here it is considering BERT model)
(X_train, y_train), (X_test, y_test), preproc = text.texts_from_df(train_df=data_train,
text_column = 'Reviews',
label_columns = 'Sentiment',
val_df = data_test,
maxlen = 250,
lang = 'zh-*',
preprocess_mode = 'bert') # or distilbert
downloading pretrained BERT model (chinese_L-12_H-768_A-12.zip)...
[██████████████████████████████████████████████████]
extracting pretrained BERT model...
done.
cleanup downloaded zip...
done.
preprocessing train...
language: zh-*
Is Multi-Label? False
preprocessing test...
language: zh-*
## size of data
print(X_train[0].shape, y_train.shape)
print(X_test[0].shape, y_test.shape)
(2880, 250) (2880, 2)
(320, 250) (320, 2)
Define Model#
## use 'distilbert' if you want
model = text.text_classifier(name = 'bert', # or distilbert
train_data = (X_train, y_train),
preproc = preproc)
Is Multi-Label? False
maxlen is 250
done.
Define Learner#
#here we have taken batch size as 6 as from the documentation it is recommend to use this with maxlen as 500
learner = ktrain.get_learner(model=model, train_data=(X_train, y_train),
val_data = (X_test, y_test),
batch_size = 6)
Estimate Learning Rate (Optional)#
A nice artilce on how to interpret learning rate plots. See Keras Learning Rate Finder.
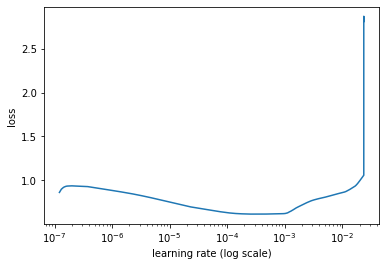
learner.lr_find(show_plot=True, max_epochs=2)
simulating training for different learning rates... this may take a few moments...
Epoch 1/2
480/480 [==============================] - 234s 488ms/step - loss: 0.6287 - accuracy: 0.6681
Epoch 2/2
480/480 [==============================] - 235s 489ms/step - loss: 2.7506 - accuracy: 0.4878
done.
Visually inspect loss plot and select learning rate associated with falling loss
Fit and Save Model#
#Essentially fit is a very basic training loop, whereas fit one cycle uses the one cycle policy callback
learner.fit_onecycle(lr = 2e-5, epochs = 1)
predictor = ktrain.get_predictor(learner.model, preproc)
predictor.save('/content/drive/My Drive/ColabData/bert-ch-marc')
begin training using onecycle policy with max lr of 2e-05...
480/480 [==============================] - 249s 520ms/step - loss: 0.3143 - accuracy: 0.8639 - val_loss: 0.1878 - val_accuracy: 0.9406
Evaluation#
y_pred=predictor.predict(data_test['Reviews'].values)
# classification report
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred))
precision recall f1-score support
negative 0.92 0.95 0.94 145
positive 0.96 0.93 0.94 175
accuracy 0.94 320
macro avg 0.94 0.94 0.94 320
weighted avg 0.94 0.94 0.94 320
y_true = data_test['Sentiment'].values
# Confusion Matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
array([[138, 7],
[ 12, 163]])
# Accuracy
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
0.940625
# Recall
from sklearn.metrics import recall_score
recall_score(y_true, y_pred, average=None)
array([0.95172414, 0.93142857])
# Precision
from sklearn.metrics import precision_score
precision_score(y_true, y_pred, average=None)
# F1
from sklearn.metrics import f1_score
f1_score(y_test, y_pred, average=None)
## AUC-ROC Curve
y_pred_proba = predictor.predict(data_test['Reviews'].values, return_proba=True)
print(predictor.get_classes()) # probability of each class
print(y_pred_proba[:5,])
['negative', 'positive']
[[0.00750571 0.9924942 ]
[0.97774005 0.02225988]
[0.97982943 0.02017057]
[0.00750882 0.9924912 ]
[0.00296137 0.9970386 ]]
y_true_binary = [1 if label=='positive' else 0 for label in y_true]
y_pred_proba_positive = y_pred_proba[:,1]
y_pred_proba_negative = y_pred_proba[:,0]
import numpy as np
from sklearn import metrics
from sklearn.metrics import roc_auc_score
# y_true = np.array([0, 0, 1, 1])
# y_scores = np.array([0.1, 0.4, 0.35, 0.8])
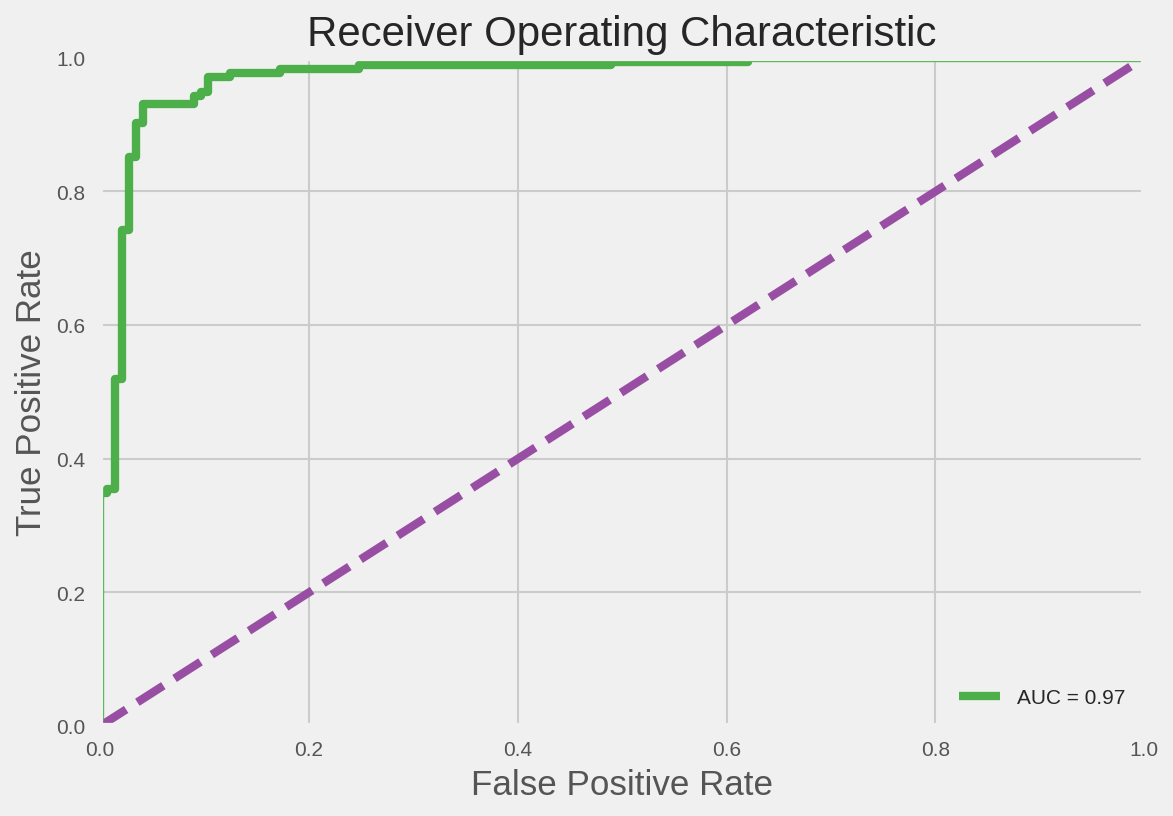
roc_auc_score(y_true_binary, y_pred_proba_positive)
# import sklearn.metrics as metrics
# # calculate the fpr and tpr for all thresholds of the classification
# probs = model.predict_proba(X_test)
# preds = probs[:,1] #
fpr, tpr, threshold = metrics.roc_curve(y_true_binary, y_pred_proba_positive)
roc_auc = metrics.auc(fpr, tpr)
# method I: plt
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
palette = plt.get_cmap('Set1')
print(palette)
plt.figure(dpi=150)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc, color=palette(2))
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--', color=palette(3))
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
<matplotlib.colors.ListedColormap object at 0x7ff18b3b9898>
# ## ggplot2 version
# ## prettier?
## Add label for color aesthetic setting
f = pd.DataFrame(dict(fpr = fpr, tpr = tpr))
f['label']= ['X' for i in range(f.shape[0])]
from plotnine import *
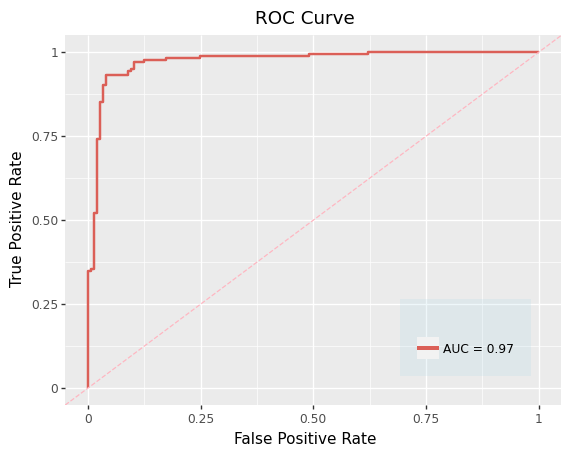
g = (
ggplot(f, aes('fpr', 'tpr', color='label'))
+ geom_line( size=1)
+ geom_abline(linetype='dashed', color="lightpink")
+ labs(x = 'False Positive Rate',
y = 'True Positive Rate',
title="ROC Curve")
+ scale_color_discrete(labels=['AUC = %0.2f' % roc_auc],name = ' ')
+ theme(legend_position = (.75,.25),
legend_background = element_rect(fill='lightblue',
alpha=0.2,
size=0.5, linetype="solid",
colour = None)))
g
<ggplot: (-9223363245528407871)>
# g.save('/content/drive/My Drive/ColabData/ggplot-roc.png', width=12, height=10, dpi=300)
Prediction and Deployment#
#sample dataset to test on
data = ['前面好笑看到後面真的很好哭!推薦!',
'也太浪費錢了,劇情普普,新鮮度可以再加強',
'人生一定要走一遭電影院',
'不推',
'帶六歲孩子看,大人覺得小孩看可以,小孩也覺得好看',
'我想看兩人如何化解對方的防線,成為彼此的救贖;在人生旅途中,留下最深刻的回憶。',
'這部新恐龍是有史以來最好看的哆啦電影版,50週年紀念作當之無愧,真的太感人了,並且彩蛋多到數不完,這部電影不僅講述了勇氣、友誼與努力不懈的精神,也以大雄的視角來看父母的心情,不管是劇情、畫面都是一流,另外配樂非常到位,全程都不會無聊,非常推薦大人、小孩、父母去電影院看,絕對值得。',
'看完之後覺得新不如舊,還是大雄的恐龍好看,不管是劇情還是做畫,都是大雄的恐龍好,而且大雄的新恐龍做畫有點崩壞,是有沒有好好審查啊!以一部50周年慶的電影來說有點丟臉,自從藤子不二雄過世後,哆啦A夢的電影就一直表現平平,沒有以前的那份感動。']
predictor.predict(data)
['positive',
'negative',
'positive',
'negative',
'positive',
'positive',
'positive',
'negative']
#return_proba = True means it will give the prediction probabilty for each class
predictor.predict(data, return_proba=True)
array([[0.00433748, 0.9956625 ],
[0.98725605, 0.01274392],
[0.27484193, 0.72515804],
[0.9657716 , 0.0342284 ],
[0.43184906, 0.56815094],
[0.00549422, 0.9945057 ],
[0.00446275, 0.9955373 ],
[0.96282476, 0.03717517]], dtype=float32)
#classes available
predictor.get_classes()
['negative', 'positive']
## zip for furture deployment
# !zip -r /content/bert.zip /content/bert
Deploy Model#
# #loading the model
predictor_load = ktrain.load_predictor('/content/drive/My Drive/ColabData/bert-ch-marc')
# #predicting the data
predictor_load.predict(data)
['positive', 'negative', 'positive']