
Types of Seqeunce Model#
Create different types of seq-to-seq models to learn date conversion
This is based on Chapter 8 of Deep Learning 2: 用 Python 進行自然語言處理的基礎理論實作.
Implement Different Types of Sequence-to-Sequence Models
Simple Sequence-to-sequence (LSTM encoder and decoder)
Simple Sequence-to-sequence (GRU encoder and decoder)
Bidirectional Sequence-to-sequence
Peeky Directional Sequence-to-sequence
Sequence Model with Attention
Compare the performance and learning efficiencies of these models
This notebook uses two types of Attention layers:
The first type is the default
keras.layers.Attention(Luong attention) andkeras.layers.AdditiveAttention(Bahdanau attention). (But these layers have ONLY been implemented in Tensorflow-nightly.The second type is developed by Thushan.
Bahdanau Attention Layber developed in Thushan
Thushan Ganegedara’s Attention in Deep Networks with Keras
This notebook runs on Google Colab (It installs the nightly version of the Tensorflow becuase of the new implementation of Attention layers).
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
import os
os.chdir('/content/drive/My Drive/_MySyncDrive/Repository/python-notes/nlp')
%pwd
'/content/drive/My Drive/_MySyncDrive/Repository/python-notes/nlp'
!pip install tf-nightly
Requirement already satisfied: tf-nightly in /usr/local/lib/python3.6/dist-packages (2.5.0.dev20201103)
Requirement already satisfied: termcolor~=1.1.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.1.0)
Requirement already satisfied: h5py~=2.10.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.10.0)
Requirement already satisfied: absl-py~=0.10 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.10.0)
Requirement already satisfied: tb-nightly~=2.4.0.a in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.4.0a20201103)
Requirement already satisfied: google-pasta~=0.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.2.0)
Requirement already satisfied: grpcio~=1.32.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.32.0)
Requirement already satisfied: flatbuffers~=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.12)
Requirement already satisfied: opt-einsum~=3.3.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.3.0)
Requirement already satisfied: astunparse~=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.6.3)
Requirement already satisfied: six~=1.15.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.15.0)
Requirement already satisfied: keras-preprocessing~=1.1.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.1.2)
Requirement already satisfied: wheel~=0.35 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.35.1)
Requirement already satisfied: protobuf~=3.13.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.13.0)
Requirement already satisfied: typing-extensions~=3.7.4 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (3.7.4.3)
Requirement already satisfied: numpy~=1.19.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.19.4)
Requirement already satisfied: wrapt~=1.12.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (1.12.1)
Requirement already satisfied: tf-estimator-nightly~=2.4.0.dev in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (2.4.0.dev2020102301)
Requirement already satisfied: gast==0.3.3 in /usr/local/lib/python3.6/dist-packages (from tf-nightly) (0.3.3)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.7.0)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (0.4.1)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.0.1)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (50.3.2)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (3.3.2)
Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (2.23.0)
Requirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tb-nightly~=2.4.0.a->tf-nightly) (1.17.2)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tb-nightly~=2.4.0.a->tf-nightly) (1.3.0)
Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python3.6/dist-packages (from markdown>=2.6.8->tb-nightly~=2.4.0.a->tf-nightly) (2.0.0)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (2020.6.20)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tb-nightly~=2.4.0.a->tf-nightly) (1.24.3)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (4.1.1)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (0.2.8)
Requirement already satisfied: rsa<5,>=3.1.4; python_version >= "3" in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (4.6)
Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tb-nightly~=2.4.0.a->tf-nightly) (3.1.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata; python_version < "3.8"->markdown>=2.6.8->tb-nightly~=2.4.0.a->tf-nightly) (3.3.1)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.6/dist-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tb-nightly~=2.4.0.a->tf-nightly) (0.4.8)
import tensorflow, keras
print(tensorflow.__version__)
print(keras.__version__)
2.5.0-dev20201103
2.4.3
Functions#
Data Preparation#
import re
import keras
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import Input, LSTM, Dense, GRU, Bidirectional
from tensorflow.keras.layers import AdditiveAttention, Attention
import numpy as np
from random import randint
from numpy import array
from numpy import argmax
from numpy import array_equal
from keras import Model
from keras.models import Sequential
from keras.layers import LSTM, GRU, Concatenate
from keras.layers import Attention
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import RepeatVector
from keras import Input
from attention import AttentionLayer
from keras.utils import to_categorical, plot_model
# Path to the data txt file on disk.
def get_data(data_path, train_test = 0.9):
#data_path = '../../../RepositoryData/data/deep-learning-2/addition.txt'
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
enc_text=[l.split('_')[0] for l in lines]
dec_text=[l.split('_')[-1].strip() for l in lines]
dec_text = ['_' + sent + '_' for sent in dec_text]
np.random.seed(123)
inds = np.arange(len(enc_text))
np.random.shuffle(inds)
train_size = int(round(len(lines)*train_test))
train_inds = inds[:train_size]
test_inds = inds[train_size:]
tr_enc_text = [enc_text[ti] for ti in train_inds]
tr_dec_text = [dec_text[ti] for ti in train_inds]
ts_enc_text = [enc_text[ti] for ti in test_inds]
ts_dec_text = [dec_text[ti] for ti in test_inds]
return tr_enc_text, tr_dec_text, ts_enc_text, ts_dec_text
## when the max_len is known, use this func to convert text to seq
def sents2sequences(tokenizer, sentences, reverse=False, pad_length=None, padding_type='post'):
encoded_text = tokenizer.texts_to_sequences(sentences)
preproc_text = pad_sequences(encoded_text, padding=padding_type, maxlen=pad_length)
if reverse:
preproc_text = np.flip(preproc_text, axis=1)
return preproc_text
def preprocess_data(enc_tokenizer, dec_tokenizer, enc_text, dec_text):
enc_seq = enc_tokenizer.texts_to_sequences(tr_enc_text)
enc_timesteps = np.max([len(l) for l in enc_seq])
enc_seq = pad_sequences(enc_seq, padding='pre', maxlen = enc_timesteps)
dec_seq = dec_tokenizer.texts_to_sequences(tr_dec_text)
dec_timesteps = np.max([len(l) for l in dec_seq])
dec_seq = pad_sequences(dec_seq, padding='post', maxlen = dec_timesteps)
return enc_seq, dec_seq
Model Definition: Simple Seq-to-Seq (LSTM)#
def define_seq2seq_lstm(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a seq2seq model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder LSTM
encoder_lstm = LSTM(hidden_size, return_sequences=False, return_state=True, name='encoder_lstm')
encoder_out, encoder_h, encoder_c = encoder_lstm(encoder_inputs) # when `return_sequences=False`, the return output and state are the same
encoder_states = [encoder_h, encoder_c]
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_lstm = LSTM(hidden_size, return_sequences=True, return_state=True, name='decoder_lstm')
decoder_out, decoder_h, decoder_c = decoder_lstm(decoder_inputs, initial_state=encoder_states)
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
# decoder_pred = dense_time(decoder_concat_input)
decoder_pred = dense_time(decoder_out)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_h, encoder_inf_c = encoder_lstm(encoder_inf_inputs)
encoder_inf_states = [encoder_inf_h, encoder_inf_c]
encoder_model = Model(inputs=encoder_inf_inputs, outputs=encoder_inf_states)
## This simple seq2seq model would use only the encoder last-timestep output
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize), name='decoder_word_inputs')
decoder_inf_init_input_h = Input(shape=(hidden_size,))
decoder_inf_init_input_c = Input(shape=(hidden_size ,))
decoder_inf_init_state = [decoder_inf_init_input_h, decoder_inf_init_input_c]
decoder_inf_out, decoder_inf_f, decoder_inf_c = decoder_lstm(decoder_inf_inputs, initial_state=decoder_inf_init_state)
# decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_out)
decoder_model = Model(inputs=[decoder_inf_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred])
return full_model , encoder_model, decoder_model
def train_seq2seq_lstm(full_model, enc_seq, dec_seq, batch_size, n_epochs):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
# def infer_seq2seq_lstm(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
# """
# Infer logic
# :param encoder_model: keras.Model
# :param decoder_model: keras.Model
# :param test_en_seq: sequence of word ids
# :param en_vsize: int
# :param fr_vsize: int
# :return:
# """
# test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
# test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
# test_dec_onehot_seq = np.expand_dims(
# to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
# enc_last_state = encoder_model.predict(test_enc_onehot_seq)
# dec_state = enc_last_state
# attention_weights = []
# dec_text = ''
# for i in range(dec_timesteps):
# dec_out = decoder_model.predict(
# [dec_state, test_dec_onehot_seq])
# dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
# if dec_ind == 0:
# break
# test_dec_seq = sents2sequences(
# dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
# test_dec_onehot_seq = np.expand_dims(
# to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
# attention_weights.append((dec_ind, attention))
# dec_text += dec_index2word[dec_ind]
# return dec_text
Model Definition: Simple Seq-to-seq (GRU)#
def define_seq2seq(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a seq2seq model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder GRU
encoder_gru = GRU(hidden_size, return_sequences=False, return_state=True, name='encoder_gru')
encoder_out, encoder_state = encoder_gru(encoder_inputs) # when `return_sequences=False`, the return output and state are the same
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='decoder_gru')
decoder_out, decoder_state = decoder_gru(decoder_inputs, initial_state=encoder_state)
# # Attention layer
# # attn_layer = AttentionLayer(name='attention_layer')
# attn_layer = AdditiveAttention(name="attention_layer")
# ## The input for AdditiveAttention: query, key
# ## It returns a tensor of shape as query
# ## This is different from the AttentionLayer developed by Thushan
# # attn_out, attn_states = attn_layer([encoder_out, decoder_out])
# attn_out, attn_states = attn_layer([decoder_out,encoder_out],return_attention_scores=True)
# Concat attention input and decoder GRU output
# decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_out, attn_out])
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
# decoder_pred = dense_time(decoder_concat_input)
decoder_pred = dense_time(decoder_out)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_state = encoder_gru(encoder_inf_inputs)
encoder_model = Model(inputs=encoder_inf_inputs, outputs=encoder_inf_state)
## This simple seq2seq model would use only the encoder last-timestep output
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize), name='decoder_word_inputs')
#encoder_inf_states = Input(batch_shape=(batch_size, enc_timesteps, hidden_size), name='encoder_inf_states')
decoder_init_state = Input(batch_shape=(batch_size, hidden_size), name='decoder_init')
decoder_inf_out, decoder_inf_state = decoder_gru(decoder_inf_inputs, initial_state=decoder_init_state)
# attn_inf_out, attn_inf_states = attn_layer([encoder_inf_states, decoder_inf_out])
# attn_inf_out, attn_inf_states = attn_layer([decoder_inf_out, encoder_inf_states],return_attention_scores=True)
# decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_out)
decoder_model = Model(inputs=[decoder_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred])
return full_model, encoder_model, decoder_model
def train_seq2seq(full_model, enc_seq, dec_seq, batch_size, n_epochs):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
def infer_seq2seq(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
"""
Infer logic
:param encoder_model: keras.Model
:param decoder_model: keras.Model
:param test_en_seq: sequence of word ids
:param en_vsize: int
:param fr_vsize: int
:return:
"""
test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
enc_last_state = encoder_model.predict(test_enc_onehot_seq)
dec_state = enc_last_state
attention_weights = []
dec_text = ''
for i in range(dec_timesteps):
dec_out = decoder_model.predict(
[dec_state, test_dec_onehot_seq])
dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
if dec_ind == 0:
break
test_dec_seq = sents2sequences(
dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
attention_weights.append((dec_ind, attention))
dec_text += dec_index2word[dec_ind]
return dec_text
Model Definition: Birectional Seq-to-Seq#
def define_biseq2seq(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a seq2seq model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder GRU
encoder_gru = Bidirectional(GRU(hidden_size, return_sequences=False, return_state=True, name='encoder_gru'))
encoder_out,encoder_fwd_state,encoder_bwd_state = encoder_gru(encoder_inputs) # when `return_sequences=False`, the return output and state are the same
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_gru = GRU(hidden_size*2, return_sequences=True, return_state=True, name='decoder_gru')
## *2 because encoder output two sets of output states (forward and backward)
decoder_out, decoder_state = decoder_gru(decoder_inputs, initial_state=Concatenate(axis=-1)([encoder_fwd_state, encoder_bwd_state]))
# # Attention layer
# # attn_layer = AttentionLayer(name='attention_layer')
# attn_layer = AdditiveAttention(name="attention_layer")
# ## The input for AdditiveAttention: query, key
# ## It returns a tensor of shape as query
# ## This is different from the AttentionLayer developed by Thushan
# # attn_out, attn_states = attn_layer([encoder_out, decoder_out])
# attn_out, attn_states = attn_layer([decoder_out,encoder_out],return_attention_scores=True)
# Concat attention input and decoder GRU output
# decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_out, attn_out])
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
# decoder_pred = dense_time(decoder_concat_input)
decoder_pred = dense_time(decoder_out)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_fwd_state, encoder_inf_bwd_state = encoder_gru(encoder_inf_inputs)
encoder_model = Model(inputs=encoder_inf_inputs, outputs=[encoder_inf_fwd_state, encoder_inf_bwd_state])
## This simple seq2seq model would use only the encoder last-timestep output
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize), name='decoder_word_inputs')
#encoder_inf_states = Input(batch_shape=(batch_size, enc_timesteps, hidden_size), name='encoder_inf_states')
decoder_init_state = Input(batch_shape=(batch_size, 2*hidden_size), name='decoder_init') ## forward + backward output states
decoder_inf_out, decoder_inf_state = decoder_gru(decoder_inf_inputs, initial_state=decoder_init_state)
# attn_inf_out, attn_inf_states = attn_layer([encoder_inf_states, decoder_inf_out])
# attn_inf_out, attn_inf_states = attn_layer([decoder_inf_out, encoder_inf_states],return_attention_scores=True)
# decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_out)
decoder_model = Model(inputs=[decoder_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred])
return full_model, encoder_model, decoder_model
def train_biseq2seq(full_model, enc_seq, dec_seq, batch_size, n_epochs):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
def infer_biseq2seq(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
"""
Infer logic
:param encoder_model: keras.Model
:param decoder_model: keras.Model
:param test_en_seq: sequence of word ids
:param en_vsize: int
:param fr_vsize: int
:return:
"""
test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
enc_last_fwd_state, enc_last_bwd_state = encoder_model.predict(test_enc_onehot_seq)
dec_state = Concatenate(axis=-1)([enc_last_fwd_state, enc_last_bwd_state])
# attention_weights = []
dec_text = ''
for i in range(dec_timesteps):
dec_out = decoder_model.predict(
[dec_state, test_dec_onehot_seq])
dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
if dec_ind == 0:
break
test_dec_seq = sents2sequences(
dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
# attention_weights.append((dec_ind, attention))
dec_text += dec_index2word[dec_ind]
return dec_text
Model Definition: Peeky Bidirectional Seq-to-Seq#
Codes do not work yet. Don’t know how to add encoder output states to every time step in the decoder.
def define_peekybiseq2seq(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a seq2seq model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder GRU
encoder_gru = Bidirectional(GRU(hidden_size, return_sequences=False, return_state=True, name='encoder_gru'))
encoder_out, encoder_fwd_state, encoder_bwd_state = encoder_gru(encoder_inputs) # when `return_sequences=False`, the return output and state are the same
encoder_concat_states = Concatenate(axis=1)([encoder_fwd_state, encoder_bwd_state])
encoder_concat_states = RepeatVector(dec_timesteps-1)(encoder_concat_states)
# Concatenate encoder_concat_states with decode_inputs
decoder_inputs_concat = Concatenate(axis=2)([decoder_inputs, encoder_concat_states])
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='decoder_gru')
## *2 because encoder output two sets of output states (forward and backward)
# decoder_init_concat =[np.random.randn(dec_vsize), encoder_fwd_state, encoder_bwd_state]
# decoder_init_concat = np.repeat(deconder_init_concat, dec_timesteps, axis=0).reshape(dec_timesteps, dec_vsize+2*hidden_size)
decoder_out, decoder_state = decoder_gru(decoder_inputs_concat)
# Concat attention input and decoder GRU output
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
### In peeky, when decoding, make use of decoder_out as well as the original encoder_fwd_state and encoder_bwd_state
decoder_out_concat = Concatenate(axis=-1)([decoder_out,encoder_concat_states])
decoder_pred = dense_time(decoder_out_concat)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_fwd_state, encoder_inf_bwd_state = encoder_gru(encoder_inf_inputs)
encoder_model = Model(inputs=encoder_inf_inputs, outputs=[encoder_inf_fwd_state, encoder_inf_bwd_state])
## This simple seq2seq model would use only the encoder last-timestep output
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize+2*hidden_size), name='decoder_word_inputs')
decoder_inf_enc_state = Input(batch_shape=(batch_size,1, 2*hidden_size), name='decoder_inf_enc_state') ## forward + backward output states
decoder_inf_out, decoder_inf_state = decoder_gru(decoder_inf_inputs)#, initial_state=decoder_init_state)
decoder_inf_out_concat = Concatenate(axis=-1)([decoder_inf_out, decoder_inf_enc_state])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_out_concat) # decoding with out decoder_inf_out, and decoder_init_state `initial states`
decoder_model = Model(inputs=[decoder_inf_enc_state, decoder_inf_inputs],
outputs=[decoder_inf_pred])
return full_model , encoder_model, decoder_model
def train_peekybiseq2seq(full_model, enc_seq, dec_seq, batch_size, n_epochs):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
# def infer_peekybiseq2seq(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
# """
# Infer logic
# :param encoder_model: keras.Model
# :param decoder_model: keras.Model
# :param test_en_seq: sequence of word ids
# :param en_vsize: int
# :param fr_vsize: int
# :return:
# """
# test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
# test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
# test_dec_onehot_seq = np.expand_dims(
# to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
# enc_last_fwd_state, enc_last_bwd_state = encoder_model.predict(test_enc_onehot_seq)
# dec_state = Concatenate(axis=-1)([enc_last_fwd_state, enc_last_bwd_state])
# # attention_weights = []
# dec_text = ''
# for i in range(dec_timesteps):
# dec_out = decoder_model.predict(
# [dec_state, test_dec_onehot_seq])
# dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
# if dec_ind == 0:
# break
# test_dec_seq = sents2sequences(
# dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
# test_dec_onehot_seq = np.expand_dims(
# to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
# # attention_weights.append((dec_ind, attention))
# dec_text += dec_index2word[dec_ind]
# return dec_text
Model Definition: Seq-to-seq with Attention#
def define_nmt(hidden_size, batch_size, enc_timesteps, enc_vsize, dec_timesteps, dec_vsize):
""" Defining a NMT model """
# Define an input sequence and process it.
if batch_size:
encoder_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
encoder_inputs = Input(shape=(enc_timesteps, enc_vsize), name='encoder_inputs')
if fr_timesteps:
decoder_inputs = Input(shape=(dec_timesteps - 1, dec_vsize), name='decoder_inputs')
else:
decoder_inputs = Input(shape=(None, dec_vsize), name='decoder_inputs')
# Encoder GRU
encoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='encoder_gru')
encoder_out, encoder_state = encoder_gru(encoder_inputs)
# Set up the decoder GRU, using `encoder_states` as initial state.
decoder_gru = GRU(hidden_size, return_sequences=True, return_state=True, name='decoder_gru')
decoder_out, decoder_state = decoder_gru(decoder_inputs, initial_state=encoder_state)
# Attention layer
# attn_layer = AttentionLayer(name='attention_layer')
attn_layer = AdditiveAttention(name="attention_layer")
## The input for AdditiveAttention: query, key
## It returns a tensor of shape as query
## This is different from the AttentionLayer developed by Thushan
# attn_out, attn_states = attn_layer([encoder_out, decoder_out])
attn_out, attn_states = attn_layer([decoder_out,encoder_out],return_attention_scores=True)
# Concat attention input and decoder GRU output
decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_out, attn_out])
# Dense layer
dense = Dense(dec_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_concat_input)
# Full model
full_model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
full_model.summary()
""" Inference model """
batch_size = 1
""" Encoder (Inference) model """
encoder_inf_inputs = Input(batch_shape=(batch_size, enc_timesteps, enc_vsize), name='encoder_inf_inputs')
encoder_inf_out, encoder_inf_state = encoder_gru(encoder_inf_inputs)
encoder_model = Model(inputs=encoder_inf_inputs, outputs=[encoder_inf_out, encoder_inf_state])
""" Decoder (Inference) model """
decoder_inf_inputs = Input(batch_shape=(batch_size, 1, dec_vsize), name='decoder_word_inputs')
encoder_inf_states = Input(batch_shape=(batch_size, enc_timesteps, hidden_size), name='encoder_inf_states')
decoder_init_state = Input(batch_shape=(batch_size, hidden_size), name='decoder_init')
decoder_inf_out, decoder_inf_state = decoder_gru(decoder_inf_inputs, initial_state=decoder_init_state)
# attn_inf_out, attn_inf_states = attn_layer([encoder_inf_states, decoder_inf_out])
attn_inf_out, attn_inf_states = attn_layer([decoder_inf_out, encoder_inf_states],return_attention_scores=True)
decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
decoder_inf_pred = TimeDistributed(dense)(decoder_inf_concat)
decoder_model = Model(inputs=[encoder_inf_states, decoder_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred, attn_inf_states, decoder_inf_state])
return full_model, encoder_model, decoder_model
def train(full_model, enc_seq, dec_seq, batch_size, n_epochs=10):
""" Training the model """
loss_epoch = []
accuracy_epoch = []
for ep in range(n_epochs):
losses = []
accuracies = []
for bi in range(0, enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
full_model.train_on_batch(
[enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
if (ep + 1) % 1 == 0:
print("Loss/Accuracy in epoch {}: {}/{}".format(ep + 1, np.mean(losses), np.mean(accuracies)))
loss_epoch.append(np.mean(losses))
accuracy_epoch.append(np.mean(accuracies))
return loss_epoch, accuracy_epoch
def infer_nmt(encoder_model, decoder_model, test_enc_seq, enc_vsize, dec_vsize, dec_timesteps):
"""
Infer logic
:param encoder_model: keras.Model
:param decoder_model: keras.Model
:param test_en_seq: sequence of word ids
:param en_vsize: int
:param fr_vsize: int
:return:
"""
test_dec_seq = sents2sequences(dec_tokenizer, ['_'], dec_vsize)
test_enc_onehot_seq = to_categorical(test_enc_seq, num_classes=enc_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
enc_outs, enc_last_state = encoder_model.predict(test_enc_onehot_seq)
dec_state = enc_last_state
attention_weights = []
dec_text = ''
for i in range(dec_timesteps):
dec_out, attention, dec_state = decoder_model.predict(
[enc_outs, dec_state, test_dec_onehot_seq])
dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
if dec_ind == 0:
break
test_dec_seq = sents2sequences(
dec_tokenizer, [dec_index2word[dec_ind]], dec_vsize)
test_dec_onehot_seq = np.expand_dims(
to_categorical(test_dec_seq, num_classes=dec_vsize), 1)
attention_weights.append((dec_ind, attention))
dec_text += dec_index2word[dec_ind]
return dec_text, attention_weights
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=["PingFang HK"]
def plot_attention_weights(encoder_inputs, attention_weights, enc_id2word, dec_id2word, filename=None):
"""
Plots attention weights
:param encoder_inputs: Sequence of word ids (list/numpy.ndarray)
:param attention_weights: Sequence of (<word_id_at_decode_step_t>:<attention_weights_at_decode_step_t>)
:param en_id2word: dict
:param fr_id2word: dict
:return:
"""
if len(attention_weights) == 0:
print('Your attention weights was empty. No attention map saved to the disk. ' +
'\nPlease check if the decoder produced a proper translation')
return
mats = []
dec_inputs = []
for dec_ind, attn in attention_weights:
mats.append(attn.reshape(-1))
dec_inputs.append(dec_ind)
attention_mat = np.transpose(np.array(mats))
fig, ax = plt.subplots(figsize=(32, 32))
ax.imshow(attention_mat)
ax.set_xticks(np.arange(attention_mat.shape[1]))
ax.set_yticks(np.arange(attention_mat.shape[0]))
ax.set_xticklabels([dec_id2word[inp] if inp != 0 else "<Res>" for inp in dec_inputs])
ax.set_yticklabels([enc_id2word[inp] if inp != 0 else "<Res>" for inp in encoder_inputs.ravel()])
ax.tick_params(labelsize=32)
ax.tick_params(axis='x', labelrotation=90)
# if not os.path.exists(config.RESULTS_DIR):
# os.mkdir(config.RESULTS_DIR)
# if filename is None:
# plt.savefig( 'attention.png'))
# else:
# plt.savefig(os.path.join(config.RESULTS_DIR, '{}'.format(filename)))
Main Program#
Data Wrangling and Training#
#### hyperparameters
batch_size = 128
hidden_size = 256
n_epochs = 5
### Get data
tr_enc_text, tr_dec_text, ts_enc_text, ts_dec_text = get_data(data_path='../../../RepositoryData/data/deep-learning-2/date.txt')
# """ Defining tokenizers """
enc_tokenizer = keras.preprocessing.text.Tokenizer(oov_token='UNK', char_level=True)
enc_tokenizer.fit_on_texts(tr_enc_text)
dec_tokenizer = keras.preprocessing.text.Tokenizer(oov_token='UNK', char_level=True)
dec_tokenizer.fit_on_texts(tr_dec_text)
# ### Getting sequence integer data
enc_seq, dec_seq = preprocess_data(enc_tokenizer, dec_tokenizer, tr_enc_text, tr_dec_text)
# ### timestesps
enc_timesteps = enc_seq.shape[1]
dec_timesteps = dec_seq.shape[1]
# ### vocab size
enc_vsize = max(enc_tokenizer.index_word.keys()) + 1
dec_vsize = max(dec_tokenizer.index_word.keys()) + 1
""" Index2word """
enc_index2word = dict(
zip(enc_tokenizer.word_index.values(), enc_tokenizer.word_index.keys()))
dec_index2word = dict(
zip(dec_tokenizer.word_index.values(), dec_tokenizer.word_index.keys()))
print(enc_vsize)
print(dec_vsize)
print(tr_enc_text[:5])
print(tr_dec_text[:5])
print('Training Size: {}'.format(len(tr_enc_text)))
print('Testing Size: {}'.format(len(ts_enc_text)))
print('epoch: {}'.format(n_epochs))
37
14
['June 16, 2015 ', '12/16/83 ', 'SEPTEMBER 9, 1998 ', 'April 17, 2013 ', 'January 26, 1990 ']
['_2015-06-16_', '_1983-12-16_', '_1998-09-09_', '_2013-04-17_', '_1990-01-26_']
Training Size: 45001
Testing Size: 5000
epoch: 5
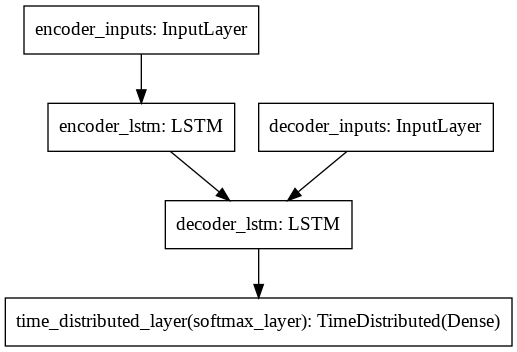
Training: Simple Seq-to-Seq (LSTM)#
###""" Defining the full model """
full_model_seq2seq_lstm, infer_enc_model_seq2seq_lstm, infer_dec_model_seq2seq_lstm = define_seq2seq_lstm(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
#
plot_model(full_model_seq2seq_lstm)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 29, 37)] 0
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 11, 14)] 0
__________________________________________________________________________________________________
encoder_lstm (LSTM) [(128, 256), (128, 2 301056 encoder_inputs[0][0]
__________________________________________________________________________________________________
decoder_lstm (LSTM) [(128, 11, 256), (12 277504 decoder_inputs[0][0]
encoder_lstm[0][1]
encoder_lstm[0][2]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 11, 14) 3598 decoder_lstm[0][0]
==================================================================================================
Total params: 582,158
Trainable params: 582,158
Non-trainable params: 0
__________________________________________________________________________________________________
%%time
loss_seq2seq_lstm, accuracy_seq2seq_lstm = train_seq2seq_lstm(full_model_seq2seq_lstm, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 1.0649111929782096/0.5779368201551953
Loss/Accuracy in epoch 2: 0.7323515359153095/0.6908589090377177
Loss/Accuracy in epoch 3: 0.532133874899981/0.7847363860518844
Loss/Accuracy in epoch 4: 0.24078542592688504/0.9195075753407601
Loss/Accuracy in epoch 5: 0.08896087344597887/0.9748567408985562
CPU times: user 17min 40s, sys: 47 s, total: 18min 27s
Wall time: 10min 40s
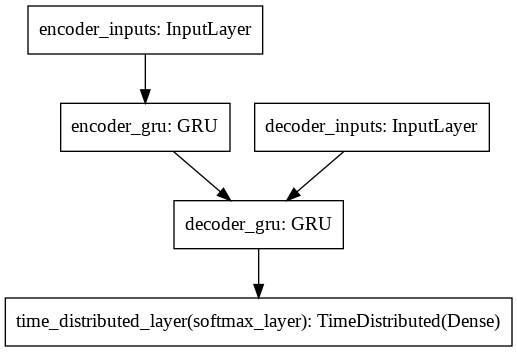
Training: Simple Seq-to-seq (GRU)#
###""" Defining the full model """
full_model_seq2seq, infer_enc_model_seq2seq, infer_dec_model_seq2seq = define_seq2seq(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
plot_model(full_model_seq2seq)
Model: "model_3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 29, 37)] 0
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 11, 14)] 0
__________________________________________________________________________________________________
encoder_gru (GRU) [(128, 256), (128, 2 226560 encoder_inputs[0][0]
__________________________________________________________________________________________________
decoder_gru (GRU) [(128, 11, 256), (12 208896 decoder_inputs[0][0]
encoder_gru[0][1]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 11, 14) 3598 decoder_gru[0][0]
==================================================================================================
Total params: 439,054
Trainable params: 439,054
Non-trainable params: 0
__________________________________________________________________________________________________
%%time
loss_seq2seq, accuracy_seq2seq = train_seq2seq(full_model_seq2seq, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 1.0656442564097566/0.578632883069522
Loss/Accuracy in epoch 2: 0.6253731366236326/0.7446439558284574
Loss/Accuracy in epoch 3: 0.24806450978133754/0.9102948554221042
Loss/Accuracy in epoch 4: 0.043125333107923/0.9935796248946774
Loss/Accuracy in epoch 5: 0.006605509582355067/0.9999777421652422
CPU times: user 13min 47s, sys: 37.6 s, total: 14min 24s
Wall time: 8min 20s
# def translate_seq2seq(infer_enc_model, infer_dec_model, test_enc_text,
# enc_vsize, dec_vsize, enc_timesteps, dec_timesteps,
# enc_tokenizer, dec_tokenizer):
# """ Inferring with trained model """
# test_enc = test_enc_text
# print('Translating: {}'.format(test_enc))
# test_enc_seq = sents2sequences(
# enc_tokenizer, [test_enc], pad_length=enc_timesteps)
# test_dec, attn_weights = infer_seq2seq(
# encoder_model=infer_enc_model, decoder_model=infer_dec_model,
# test_enc_seq=test_enc_seq, enc_vsize=enc_vsize, dec_vsize=dec_vsize, dec_timesteps = dec_timesteps)
# print('\tFrench: {}'.format(test_dec))
# return test_enc_seq, test_dec, attn_weights
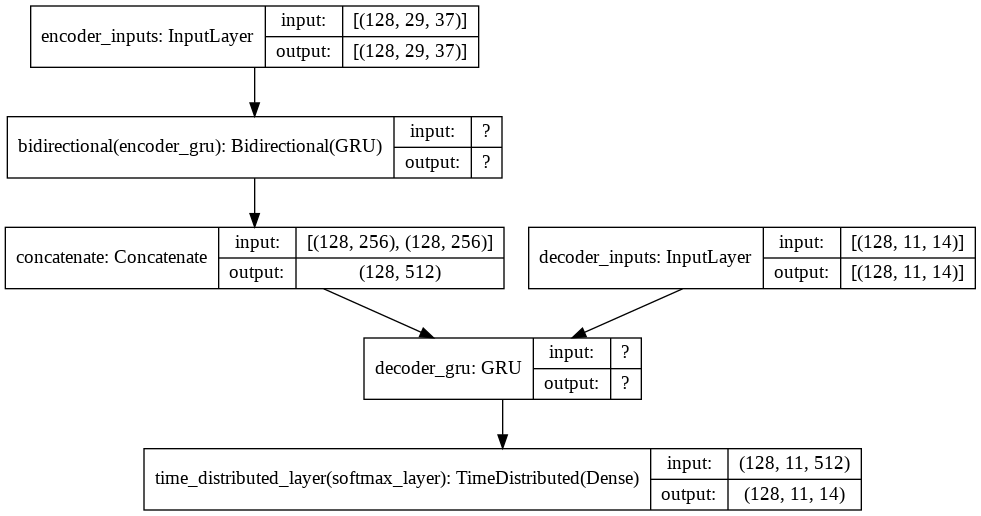
Training: Seq-to-seq Bidirectional#
##""" Defining the full model """
full_model_biseq2seq, infer_enc_model_biseq2seq, infer_dec_model_biseq2seq = define_biseq2seq(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
plot_model(full_model_biseq2seq, show_shapes=True)
Model: "model_6"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 29, 37)] 0
__________________________________________________________________________________________________
bidirectional (Bidirectional) [(128, 512), (128, 2 453120 encoder_inputs[0][0]
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 11, 14)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (128, 512) 0 bidirectional[0][1]
bidirectional[0][2]
__________________________________________________________________________________________________
decoder_gru (GRU) [(128, 11, 512), (12 811008 decoder_inputs[0][0]
concatenate[0][0]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 11, 14) 7182 decoder_gru[0][0]
==================================================================================================
Total params: 1,271,310
Trainable params: 1,271,310
Non-trainable params: 0
__________________________________________________________________________________________________
%%time
loss_biseq2seq, accuracy_biseq2seq = train_biseq2seq(full_model_biseq2seq, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 0.9139238283505128/0.6415315018250392
Loss/Accuracy in epoch 2: 0.29391230560011333/0.9017680823972761
Loss/Accuracy in epoch 3: 0.04556243142585384/0.9905363716970482
Loss/Accuracy in epoch 4: 0.004953260564025056/0.9999554839908568
Loss/Accuracy in epoch 5: 0.0017501141705505146/0.9999898828332581
CPU times: user 30min 21s, sys: 1min 11s, total: 31min 33s
Wall time: 17min 9s
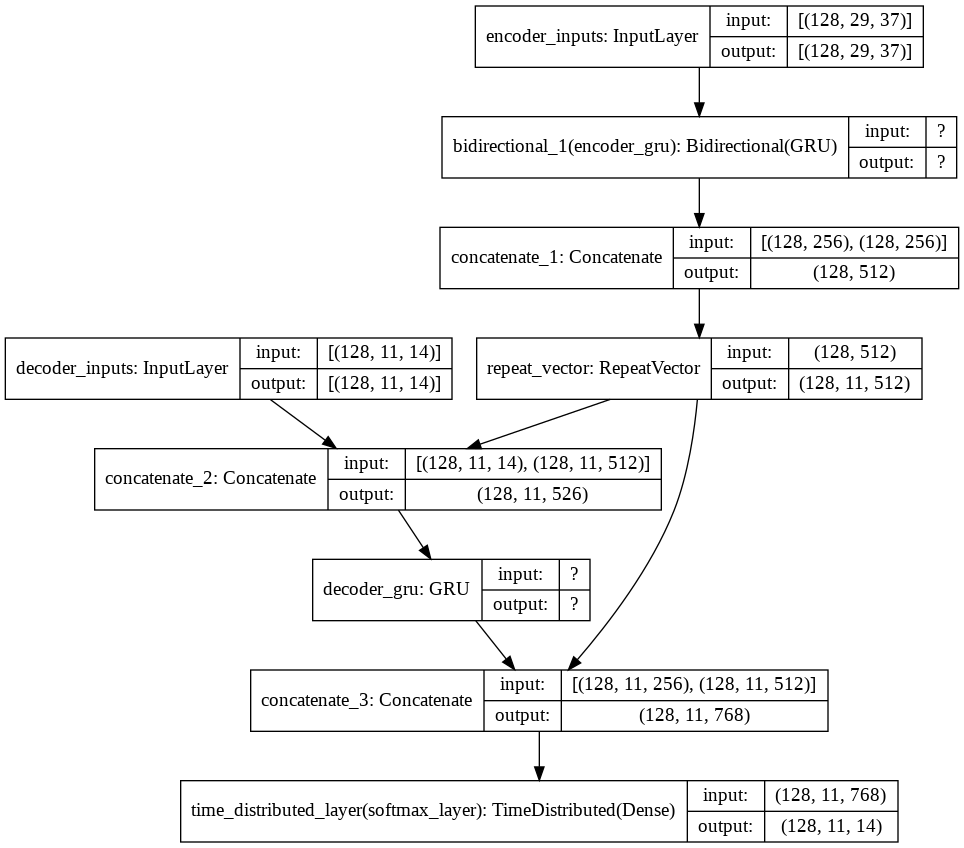
Training: Seq-to-Seq Peeky Bidirectional#
Codes do not work yet.
##""" Defining the full model """
full_model_peekybiseq2seq, infer_enc_model_peekybiseq2seq, infer_dec_model_peekybiseq2seq = define_peekybiseq2seq(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
plot_model(full_model_peekybiseq2seq, show_shapes=True)
Model: "model_9"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 29, 37)] 0
__________________________________________________________________________________________________
bidirectional_1 (Bidirectional) [(128, 512), (128, 2 453120 encoder_inputs[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (128, 512) 0 bidirectional_1[0][1]
bidirectional_1[0][2]
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 11, 14)] 0
__________________________________________________________________________________________________
repeat_vector (RepeatVector) (128, 11, 512) 0 concatenate_1[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (128, 11, 526) 0 decoder_inputs[0][0]
repeat_vector[0][0]
__________________________________________________________________________________________________
decoder_gru (GRU) [(128, 11, 256), (12 602112 concatenate_2[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (128, 11, 768) 0 decoder_gru[0][0]
repeat_vector[0][0]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 11, 14) 10766 concatenate_3[0][0]
==================================================================================================
Total params: 1,065,998
Trainable params: 1,065,998
Non-trainable params: 0
__________________________________________________________________________________________________
%%time
loss_peekybiseq2seq, accuracy_peekybiseq2seq = train_peekybiseq2seq(full_model_peekybiseq2seq, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 0.839231349124528/0.7072184180092608
Loss/Accuracy in epoch 2: 0.09685541687273232/0.9742962459892969
Loss/Accuracy in epoch 3: 0.006157726490541104/0.9999514366486812
Loss/Accuracy in epoch 4: 0.0018085484506371312/0.9999979764987261
Loss/Accuracy in epoch 5: 0.0009206719056403322/0.9999979764987261
CPU times: user 27min 40s, sys: 1min 12s, total: 28min 53s
Wall time: 15min 38s
Training: Seq-to-seq with Attention#
###""" Defining the full model """
full_model, infer_enc_model, infer_dec_model = define_nmt(
hidden_size=hidden_size,
batch_size=batch_size,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_vsize=enc_vsize,
dec_vsize=dec_vsize)
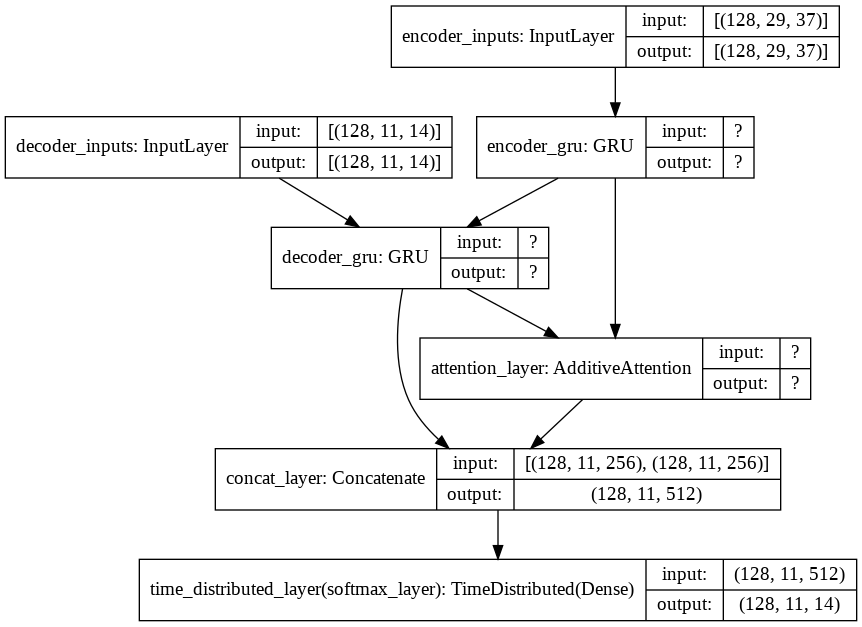
Model: "model_12"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(128, 29, 37)] 0
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(128, 11, 14)] 0
__________________________________________________________________________________________________
encoder_gru (GRU) [(128, 29, 256), (12 226560 encoder_inputs[0][0]
__________________________________________________________________________________________________
decoder_gru (GRU) [(128, 11, 256), (12 208896 decoder_inputs[0][0]
encoder_gru[0][1]
__________________________________________________________________________________________________
attention_layer (AdditiveAttent ((128, 11, 256), (12 256 decoder_gru[0][0]
encoder_gru[0][0]
__________________________________________________________________________________________________
concat_layer (Concatenate) (128, 11, 512) 0 decoder_gru[0][0]
attention_layer[0][0]
__________________________________________________________________________________________________
time_distributed_layer (TimeDis (128, 11, 14) 7182 concat_layer[0][0]
==================================================================================================
Total params: 442,894
Trainable params: 442,894
Non-trainable params: 0
__________________________________________________________________________________________________
plot_model(full_model, show_shapes=True)
%%time
loss, accuracy = train(full_model, enc_seq, dec_seq, batch_size, n_epochs)
Loss/Accuracy in epoch 1: 0.8956328547238624/0.6711222800688866
Loss/Accuracy in epoch 2: 0.11800523433420393/0.9678900386193539
Loss/Accuracy in epoch 3: 0.01371995177640025/0.998585610987454
Loss/Accuracy in epoch 4: 0.007064209757784005/0.998893177067792
Loss/Accuracy in epoch 5: 0.0017342517627376606/0.9999433426435856
CPU times: user 20min 48s, sys: 47.1 s, total: 21min 35s
Wall time: 12min 5s
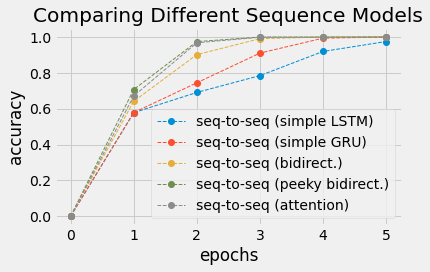
plt.style.use('fivethirtyeight')
plt.plot(range(len(accuracy_seq2seq_lstm)+1), [0]+accuracy_seq2seq_lstm,linestyle='--', marker='o', linewidth=1, label='seq-to-seq (simple LSTM)')
plt.plot(range(len(accuracy_seq2seq)+1), [0]+ accuracy_seq2seq, linestyle='--', marker='o', linewidth=1, label='seq-to-seq (simple GRU)')
plt.plot(range(len(accuracy_biseq2seq)+1), [0]+accuracy_biseq2seq,linestyle='--', marker='o', linewidth=1, label='seq-to-seq (bidirect.)')
plt.plot(range(len(accuracy_peekybiseq2seq)+1), [0]+accuracy_peekybiseq2seq,linestyle='--', marker='o', linewidth=1, label='seq-to-seq (peeky bidirect.)')
plt.plot(range(len(accuracy[:5])+1), [0]+accuracy[:5], linestyle='--', marker='o', linewidth=1, label='seq-to-seq (attention)')
plt.legend()
plt.title('Comparing Different Sequence Models')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.tight_layout()
plt.show()
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
Model Saving#
# full_model.save('../../../RepositoryData/output/seq2seq-attention-addition/full-model.h5')
# infer_enc_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-enc-model.h5')
# infer_dec_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-dec-model.h5')
full_model.save('../../../RepositoryData/output/seq2seq-attention-addition/full-model.h5')
infer_enc_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-enc-model.h5')
infer_dec_model.save('../../../RepositoryData/output/seq2seq-attention-addition/infer-dec-model.h5')
Prediction#
# full_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/full-model.h5')
# infer_enc_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/infer-enc-model.h5')
# infer_dec_model.load_weights('../../../RepositoryData/output/seq2seq-attention-addition/infer-dec-model.h5')
plot_model(infer_enc_model,show_shapes=True)
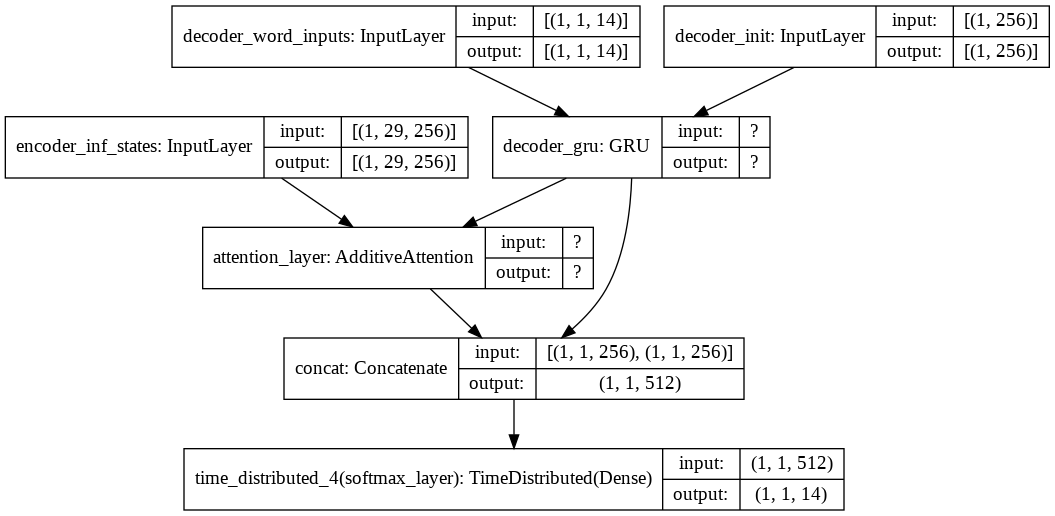
plot_model(infer_dec_model, show_shapes=True)
def translate(infer_enc_model, infer_dec_model, test_enc_text,
enc_vsize, dec_vsize, enc_timesteps, dec_timesteps,
enc_tokenizer, dec_tokenizer):
""" Inferring with trained model """
test_enc = test_enc_text
print('Translating: {}'.format(test_enc))
test_enc_seq = sents2sequences(
enc_tokenizer, [test_enc], pad_length=enc_timesteps)
test_dec, attn_weights = infer_nmt(
encoder_model=infer_enc_model, decoder_model=infer_dec_model,
test_enc_seq=test_enc_seq, enc_vsize=enc_vsize, dec_vsize=dec_vsize, dec_timesteps = dec_timesteps)
print('\tFrench: {}'.format(test_dec))
return test_enc_seq, test_dec, attn_weights
test_enc_seq, test_dec, attn_weights=translate(infer_enc_model=infer_enc_model,
infer_dec_model=infer_dec_model,
test_enc_text=ts_enc_text[120],
enc_vsize=enc_vsize,
dec_vsize=dec_vsize,
enc_timesteps=enc_timesteps,
dec_timesteps=dec_timesteps,
enc_tokenizer=enc_tokenizer,
dec_tokenizer=dec_tokenizer)
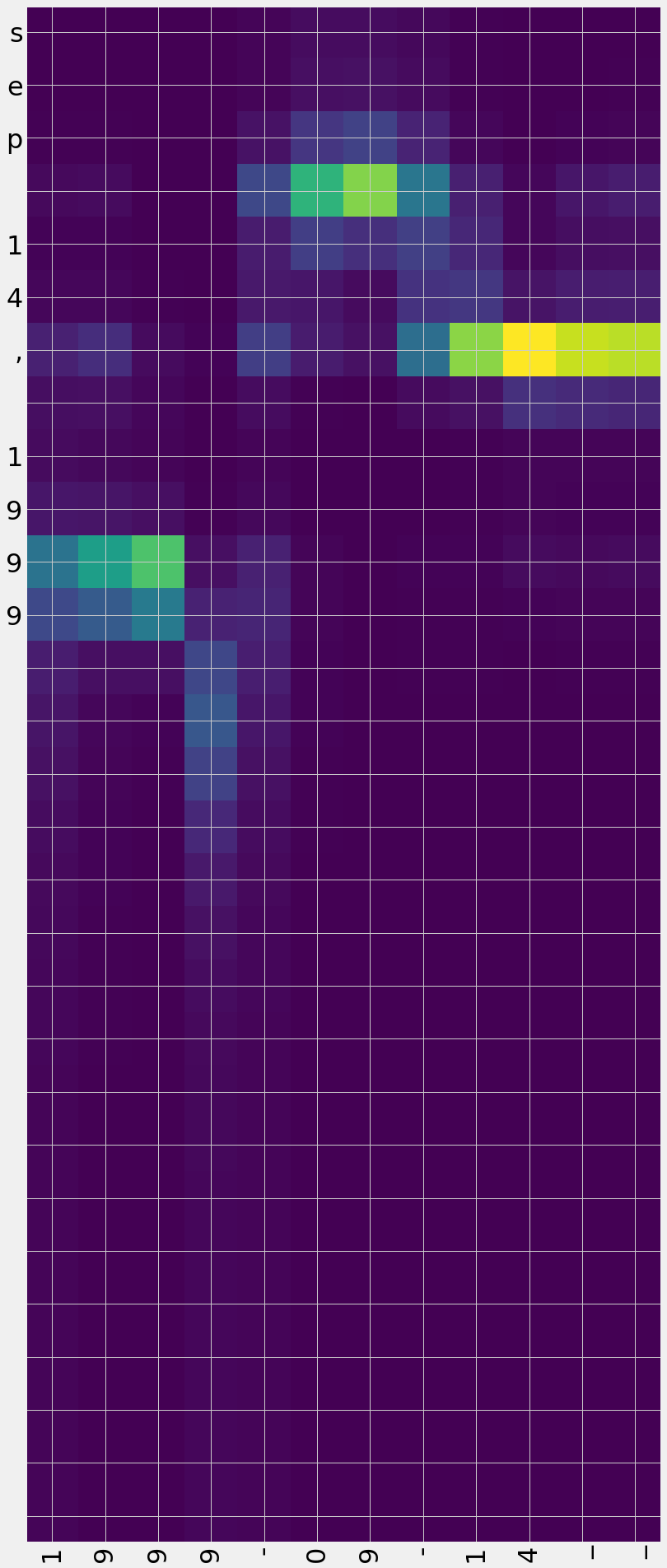
Translating: Sep 14, 1999
French: 1999-09-14__
""" Attention plotting """
plot_attention_weights(test_enc_seq, attn_weights,
enc_index2word, dec_index2word)
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
print(tr_enc_text[:5])
print(tr_dec_text[:5])
['June 16, 2015 ', '12/16/83 ', 'SEPTEMBER 9, 1998 ', 'April 17, 2013 ', 'January 26, 1990 ']
['_2015-06-16_', '_1983-12-16_', '_1998-09-09_', '_2013-04-17_', '_1990-01-26_']
Evaluation on Test Data#
%%time
def test(full_model, ts_enc_text, ts_dec_text, enc_tokenizer, dec_tokenizer, batch_size):
# ### Getting sequence integer data
ts_enc_seq, ts_dec_seq = preprocess_data(enc_tokenizer, dec_tokenizer, ts_enc_text, ts_dec_text)
losses = []
accuracies = []
for bi in range(0, ts_enc_seq.shape[0] - batch_size, batch_size):
enc_onehot_seq = to_categorical(
ts_enc_seq[bi:bi + batch_size, :], num_classes=enc_vsize)
dec_onehot_seq = to_categorical(
ts_dec_seq[bi:bi + batch_size, :], num_classes=dec_vsize)
# full_model.train_on_batch(
# [enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :])
l,a = full_model.evaluate([enc_onehot_seq, dec_onehot_seq[:, :-1, :]], dec_onehot_seq[:, 1:, :],
batch_size=batch_size, verbose=0)
losses.append(l)
accuracies.append(a)
print('Average Loss:{}'.format(np.mean(losses)))
print('Average Accuracy:{}'.format(np.mean(accuracies)))
test(full_model, ts_enc_text = ts_enc_text, ts_dec_text = ts_dec_text,
enc_tokenizer = enc_tokenizer, dec_tokenizer = dec_tokenizer, batch_size = batch_size)
Average Loss:0.0012862230989381543
Average Accuracy:0.9999595304839631
CPU times: user 1min 12s, sys: 2.37 s, total: 1min 15s
Wall time: 47.1 s