
Tokenization#
This notebook covers the basics of text tokenization. Tokenization is a method of breaking up a piece of text into smaller chunks, such as paragraphs, sentences, words, segments. It is usually the first step for computational text analytics as well as corpus analyses.
In this notebook, we focus on English tokenization. Chinese may require an additional step, i.e., the word segmentation, which can be dealt with in later notebooks.
Loading libraries#
The nltk provides many useful tools for natural language processing and text analytics. In particular, it is a comprehensive library including many state-of-art ready-made tokenizers for use.
Sentence Tokenization#
from nltk.tokenize import sent_tokenize
para = '''There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, “Oh dear! Oh dear! I shall be late!” (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge.'''
for s in sent_tokenize(para):
print(s+'\n')
There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, “Oh dear!
Oh dear!
I shall be late!” (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge.
The sent_tokenize() function uses an instance of PunktSentenceTokenizer from the ntlk.tokenize.punkt module.
To process large amount of data, it is recommended to load the pre-trained PunktSentenceTokenizer once, and call its tokenizer() method for the task.
import nltk.data
tokenizer = nltk.data.load('tokenizers/punkt/PY3/english.pickle')
tokenizer.tokenize(para)
['There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, “Oh dear!',
'Oh dear!',
'I shall be late!” (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge.']
The nltk also provides many pre-trained PunktSentenceTokenizer for other European languages.
!ls /Users/alvinchen/nltk_data/tokenizers/punkt/PY3
ls: /Users/alvinchen/nltk_data/tokenizers/punkt/PY3: No such file or directory
Word Tokenization#
Similarly, the word_tokenize() function is a wrapper function that calls the tokenize() method on a instance of TreebankWordTokenizer class.
from nltk.tokenize import word_tokenize
word_tokenize(para)
['There',
'was',
'nothing',
'so',
'very',
'remarkable',
'in',
'that',
';',
'nor',
'did',
'Alice',
'think',
'it',
'so',
'very',
'much',
'out',
'of',
'the',
'way',
'to',
'hear',
'the',
'Rabbit',
'say',
'to',
'itself',
',',
'“',
'Oh',
'dear',
'!',
'Oh',
'dear',
'!',
'I',
'shall',
'be',
'late',
'!',
'”',
'(',
'when',
'she',
'thought',
'it',
'over',
'afterwards',
',',
'it',
'occurred',
'to',
'her',
'that',
'she',
'ought',
'to',
'have',
'wondered',
'at',
'this',
',',
'but',
'at',
'the',
'time',
'it',
'all',
'seemed',
'quite',
'natural',
')',
';',
'but',
'when',
'the',
'Rabbit',
'actually',
'took',
'a',
'watch',
'out',
'of',
'its',
'waistcoat-pocket',
',',
'and',
'looked',
'at',
'it',
',',
'and',
'then',
'hurried',
'on',
',',
'Alice',
'started',
'to',
'her',
'feet',
',',
'for',
'it',
'flashed',
'across',
'her',
'mind',
'that',
'she',
'had',
'never',
'before',
'seen',
'a',
'rabbit',
'with',
'either',
'a',
'waistcoat-pocket',
',',
'or',
'a',
'watch',
'to',
'take',
'out',
'of',
'it',
',',
'and',
'burning',
'with',
'curiosity',
',',
'she',
'ran',
'across',
'the',
'field',
'after',
'it',
',',
'and',
'fortunately',
'was',
'just',
'in',
'time',
'to',
'see',
'it',
'pop',
'down',
'a',
'large',
'rabbit-hole',
'under',
'the',
'hedge',
'.']
To process large amount of data, please create an instance of TreebankWordTokenizer and call its tokenize() method for more efficient processing.
We will get the same results with the following codes as above.
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
tokenizer.tokenize(para)
['There',
'was',
'nothing',
'so',
'very',
'remarkable',
'in',
'that',
';',
'nor',
'did',
'Alice',
'think',
'it',
'so',
'very',
'much',
'out',
'of',
'the',
'way',
'to',
'hear',
'the',
'Rabbit',
'say',
'to',
'itself',
',',
'“',
'Oh',
'dear',
'!',
'Oh',
'dear',
'!',
'I',
'shall',
'be',
'late',
'!',
'”',
'(',
'when',
'she',
'thought',
'it',
'over',
'afterwards',
',',
'it',
'occurred',
'to',
'her',
'that',
'she',
'ought',
'to',
'have',
'wondered',
'at',
'this',
',',
'but',
'at',
'the',
'time',
'it',
'all',
'seemed',
'quite',
'natural',
')',
';',
'but',
'when',
'the',
'Rabbit',
'actually',
'took',
'a',
'watch',
'out',
'of',
'its',
'waistcoat-pocket',
',',
'and',
'looked',
'at',
'it',
',',
'and',
'then',
'hurried',
'on',
',',
'Alice',
'started',
'to',
'her',
'feet',
',',
'for',
'it',
'flashed',
'across',
'her',
'mind',
'that',
'she',
'had',
'never',
'before',
'seen',
'a',
'rabbit',
'with',
'either',
'a',
'waistcoat-pocket',
',',
'or',
'a',
'watch',
'to',
'take',
'out',
'of',
'it',
',',
'and',
'burning',
'with',
'curiosity',
',',
'she',
'ran',
'across',
'the',
'field',
'after',
'it',
',',
'and',
'fortunately',
'was',
'just',
'in',
'time',
'to',
'see',
'it',
'pop',
'down',
'a',
'large',
'rabbit-hole',
'under',
'the',
'hedge',
'.']
The nltk module has implemented other more task-oriented word tokenizers, which differ in terms of their specific handling of the punctuations and contractions.
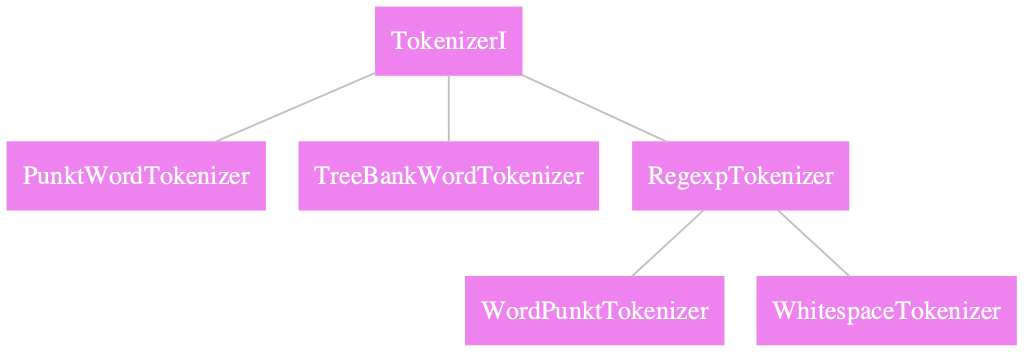
Comparing different word tokenizers#
TreebankWordTokenizerfollows the Penn Treebank conventions for word tokenization.WordPunctTokenizersplits all punctuations into separate tokens.
from nltk.tokenize import WordPunctTokenizer
wpt = WordPunctTokenizer()
tbwt = TreebankWordTokenizer()
sent = "Isn't this great? I can't tell!"
wpt.tokenize(sent)
['Isn', "'", 't', 'this', 'great', '?', 'I', 'can', "'", 't', 'tell', '!']
tbwt.tokenize(sent)
['Is', "n't", 'this', 'great', '?', 'I', 'ca', "n't", 'tell', '!']
Tokenization using regular expressions#
The nltk also provides another flexible way for text tokenization based on regular expression.
The RegexTokenizer class allows for text tokenization based on the self-defined regular expression patterns.
The regular expression can be created/defined for either the token or the delimiter.
from nltk.tokenize import RegexpTokenizer
retok1 = RegexpTokenizer(pattern= "[a-zA-Z_'-]+")
retok2 = RegexpTokenizer(pattern= "[a-zA-Z_-]+")
retok3 = RegexpTokenizer(pattern= "\s+", gaps=True)
print(retok1.tokenize(sent))
["Isn't", 'this', 'great', 'I', "can't", 'tell']
See how this tokenizer deals with the apostrophe?
print(retok2.tokenize(sent))
['Isn', 't', 'this', 'great', 'I', 'can', 't', 'tell']
print(retok3.tokenize(sent))
["Isn't", 'this', 'great?', 'I', "can't", 'tell!']