Midterm Exam#
Instructions#
The midterm consists of THREE main questions. Please choose TWO out of the three main questions to work on.
For each question, you need to accomplish one ultimate goal using the datasets from
demo_data/midterm. Each question is further divided into two sub-questions to help you accomplish the goal step by step.If you fail to produce the output from the previous question, and its output is the input for the subsequent question, you can use the sample output files provided in
demo_data/midtermto start the sub-questions. For example, you can use the sample output of Question 1-1 for the task of Question 1-2.As with previous assignments, please submit both your notebook (
*.ipynb) and the HTML output (*.html).Deadline for Midterm Submission: 12:10 (noon), Friday, April 19, via Moodle.
Contents
Tip
If you have any questions regarding the descriptions of the tasks, please send me an email message. I will response ASAP.
Question One (50%)#
Question 1-1#
Please download the dataset from demo_data/midterm/jay/, which is a directory including lyric text files of songs by Jay Chou (周杰倫). Please load the entire corpus into a data frame, preprocess the raw lyrics, and save them in another column of the data frame. A sample data frame is provided below.
When preprocesssing the raw lyrics, please pay attention to the following issues:
Remove symbols and punctuations in the lyrics
Remove (English) alphabetic characters (including full-width alphabets, e.g.
t)Remove digits (e.g.,
01234)
A complete output csv file is also available in demo_data/midterm/question1-1-output-jay.csv. You can compare your result with this sample csv.
A data frame including both the title (filename), raw lyrics, and preprocessed lyrics of each song:
Show code cell source
jay.head()
| title | lyric | lyric_pre | |
|---|---|---|---|
| 0 | 我是如此相信 | 鳥群離開了森林 整座天空很灰心\n蝴蝶不再被吸引 玫瑰盛開的很安靜\n遠方的風雨不停 城市蒼白而孤寂\n徘徊無助的人群 焦慮著何時放晴\n故事裡能毀壞的只有風景\n誰也摧毀不了我們的夢境\n弦月旁的流星劃過了天際\n我許下的願望該向誰去說明\n隕石在浩瀚的宇宙間旅行\n璀璨的夜空裡漫天的水晶\n我的禱告終於有了回音\n我是如此相信 在背後支撐的是你\n一直與我並肩而行 仰望等太陽升起\n聽... | 鳥群離開了森林 整座天空很灰心\n蝴蝶不再被吸引 玫瑰盛開的很安靜\n遠方的風雨不停 城市蒼白而孤寂\n徘徊無助的人群 焦慮著何時放晴\n故事裡能毀壞的只有風景\n誰也摧毀不了我們的夢境\n弦月旁的流星劃過了天際\n我許下的願望該向誰去說明\n隕石在浩瀚的宇宙間旅行\n璀璨的夜空裡漫天的水晶\n我的禱告終於有了回音\n我是如此相信 在背後支撐的是你\n一直與我並肩而行 仰望等太陽升起\n聽... |
| 1 | 英雄 | 人生不是ㄧ個人的遊戲\nㄧ起奮鬥ㄧ起超越ㄧ起殺吧sup兄弟\n好戰好勝戰勝逆命\n管他天賦夠不夠我們都還需要再努力\n你的劍就是我的劍\n艾希的箭可不可以準ㄧ點 嘿\n你打野我來控兵線\n不要隨便慌張就交閃現\n旋轉跳躍你閉著眼\n卡特轉完會讓你閉上眼\n悟空蓋倫也轉圈圈\n盲僧李先生ㄧ腳把你 踢回老家\n擊殺 雙殺 三殺 Penta kill\n扛塔 偷拆 插眼讓我傳送\n... | 人生不是ㄧ個人的遊戲\nㄧ起奮鬥ㄧ起超越ㄧ起殺吧 兄弟\n好戰好勝戰勝逆命\n管他天賦夠不夠我們都還需要再努力\n你的劍就是我的劍\n艾希的箭可不可以準ㄧ點 嘿\n你打野我來控兵線\n不要隨便慌張就交閃現\n旋轉跳躍你閉著眼\n卡特轉完會讓你閉上眼\n悟空蓋倫也轉圈圈\n盲僧李先生ㄧ腳把你 踢回老家\n擊殺 雙殺 三殺\n扛塔 偷拆 插眼讓我傳送\n擊殺 雙殺 三殺\n迎接 勝利 最後讓我... |
| 2 | 雙截棍 | 岩燒店的煙味瀰漫 隔壁是國術館\n店裡面的媽媽桑 茶道 有三段\n教拳腳武術的老板 練鐵沙掌 耍楊家槍\n硬底子功夫最擅長 還會金鐘罩鐵布衫\n他們兒子我習慣 從小就耳濡目染\n什麼刀槍跟棍棒 我都耍的有模有樣\n什麼兵器最喜歡 雙截棍柔中帶剛\n想要去河南嵩山 學少林跟武當\n幹什麼(客) 幹什麼(客) 呼吸吐納心自在\n幹什麼(客) 幹什麼(客) 氣沉丹田手... | 岩燒店的煙味瀰漫 隔壁是國術館\n店裡面的媽媽桑 茶道 有三段\n教拳腳武術的老板 練鐵沙掌 耍楊家槍\n硬底子功夫最擅長 還會金鐘罩鐵布衫\n他們兒子我習慣 從小就耳濡目染\n什麼刀槍跟棍棒 我都耍的有模有樣\n什麼兵器最喜歡 雙截棍柔中帶剛\n想要去河南嵩山 學少林跟武當\n幹什麼 客 幹什麼 客 呼吸吐納心自在\n幹什麼 客 幹什麼 客 氣沉丹田手心開\n幹什麼 客 幹什麼 客 日行... |
| 3 | 開不了口 | 才離開沒多久就開始 擔心今天的妳過得好不好\n整個畫面是妳 想妳想的睡不著\n嘴嘟嘟那可愛的模樣 還有在妳身上香香的味道\n我的快樂是妳 想妳想的都會笑\n沒有妳在我有多難熬(沒有妳在我有多難熬多煩惱)\n沒有妳煩我有多煩惱(沒有妳煩我有多煩惱多難熬)\n穿過雲層 我試著努力向妳奔跑\n愛才送到 妳卻已在別人懷抱\n就是開不了口 讓她知道\n我一定會呵護著妳 也逗妳笑\n妳... | 才離開沒多久就開始 擔心今天的妳過得好不好\n整個畫面是妳 想妳想的睡不著\n嘴嘟嘟那可愛的模樣 還有在妳身上香香的味道\n我的快樂是妳 想妳想的都會笑\n沒有妳在我有多難熬 沒有妳在我有多難熬多煩惱\n沒有妳煩我有多煩惱 沒有妳煩我有多煩惱多難熬\n穿過雲層 我試著努力向妳奔跑\n愛才送到 妳卻已在別人懷抱\n就是開不了口 讓她知道\n我一定會呵護著妳 也逗妳笑\n妳對我有多重要 我後悔... |
| 4 | 床邊故事 | 從前從前有隻貓頭鷹 牠站在屋頂\n屋頂後面一遍森林 森林很安靜\n安靜的鋼琴在大廳 閣樓裡 仔細聽\n仔細聽 叮叮叮 什麼聲音\n乖乖睡 不要怕 聽我說\n乖乖睡 醒來就 吃蘋果\n不睡覺 的時候 有傳說\n會有人 咬你的 小指頭\n這故事 繼續翻頁 再翻頁\n你繼續 不想睡 我卻想睡\n然後我準備 去打開衣櫃\n去看看 躲著誰 去看看 躲著誰\... | 從前從前有隻貓頭鷹 牠站在屋頂\n屋頂後面一遍森林 森林很安靜\n安靜的鋼琴在大廳 閣樓裡 仔細聽\n仔細聽 叮叮叮 什麼聲音\n乖乖睡 不要怕 聽我說\n乖乖睡 醒來就 吃蘋果\n不睡覺 的時候 有傳說\n會有人 咬你的 小指頭\n這故事 繼續翻頁 再翻頁\n你繼續 不想睡 我卻想睡\n然後我準備 去打開衣櫃\n去看看 躲著誰 去看看 躲著誰\n紙上的 城堡卡片 發光的 立體呈現\n奇幻... |
When removing symbols, please make sure that the characters before and after the symbol are still properly separated (as shown below):
Show code cell source
print("Song Title:", jay.title[100])
print("[Raw Lyrics]:")
print(jay.lyric[100])
print("="*50)
print("[Preprocessed Version]:")
print(jay.lyric_pre[100])
Song Title: 斷了的弦
[Raw Lyrics]:
斷了的弦再怎麼練 我的感覺你已聽不見
你的轉變像斷掉的弦 再怎麼接音都不對 你的改變我能夠分辨
*我沉默 你的話也不多 我們之間少了什麼 不說
哎唷~微笑後表情終於有點難過(握著你的手) 問你決定了再走
我突然釋懷的笑 笑聲盤旋半山腰
隨風在飄搖啊搖 來到你的面前繞
你淚水往下的掉 說會記住我的好 我也彎起了嘴角笑
你的美已經給了誰 追了又追我要不回
我瞭解離開樹的葉 屬於地上的世界凋謝
斷了的弦再彈一遍 我的世界你不在裏面
我的指尖已經彈出繭 還是無法留你在我身邊
△斷了的弦再怎麼練 我的感覺你已聽不見
你的轉變像斷掉的弦 再怎麼接音都不對 你的改變我能夠分辨
Repeat *~△
==================================================
[Preprocessed Version]:
斷了的弦再怎麼練 我的感覺你已聽不見
你的轉變像斷掉的弦 再怎麼接音都不對 你的改變我能夠分辨
我沉默 你的話也不多 我們之間少了什麼 不說
哎唷 微笑後表情終於有點難過 握著你的手 問你決定了再走
我突然釋懷的笑 笑聲盤旋半山腰
隨風在飄搖啊搖 來到你的面前繞
你淚水往下的掉 說會記住我的好 我也彎起了嘴角笑
你的美已經給了誰 追了又追我要不回
我瞭解離開樹的葉 屬於地上的世界凋謝
斷了的弦再彈一遍 我的世界你不在裏面
我的指尖已經彈出繭 還是無法留你在我身邊
斷了的弦再怎麼練 我的感覺你已聽不見
你的轉變像斷掉的弦 再怎麼接音都不對 你的改變我能夠分辨
Also, when removing the alphabets, make sure that the alphabets in full-width forms are removed as well, as shown below (e.g.,
tone):
Show code cell source
print("Song Title:", jay.title[200])
print("[Raw Lyrics]:")
print(jay.lyric[200])
print("="*50)
print("[Preprocessed Version]:")
print(jay.lyric_pre[200])
Song Title: 你怎麼連話都說不清楚
[Raw Lyrics]:
這首歌沒有唱過.但是是我寫的.然後.寫給一個好朋友的歌
那.我自己重新來唱.我覺得應該.版本真的也不錯
想別的 可是在你眼中察覺什麼一閃而過
怎是像是寂寞 於是我會更沉默
沒說的 可是在你眼中察覺什麼一閃而過
而我看她笑著走開 於是我裝做不懂 怎麼能拆穿你的不同
偏偏 這地球 這麼擠 這麼小 這麼瘦 太陽刻意曬得那麼兇
記得離別在拆散一點以後
你怎麼連話都說不清楚 那溫柔的tone我聽得清楚
他站在我的身邊 你站在我的面前 怎麼這樣心裡會難過
你怎麼連話都說不清楚 那溫柔的痛我聽得清楚
你站在我的身邊 他經過我的面前 怎麼這樣心裡又難過 為什麼
想別的 可是我忽然察覺什麼一閃而過
於是像是寂寞 於是我會更沉默
沒說的 可是在你眼中察覺什麼一閃而過
於是像是寂寞 怎麼能拆穿不同 怎麼能拆穿你的不同
偏偏 這地球 這麼擠 這麼小 這麼瘦 太陽刻意曬得那麼兇
為什麼你出現在他出現以後
你怎麼連話都說不清楚 那溫柔的tone我聽得清楚
我站在他的身邊 你站在我的面前 怎麼這樣心裡會難過
你怎麼連話都說不清楚 那溫柔的痛我記得清楚
他站在我的面前 你經過我的身邊 忽然之間心裡又難過 為什麼
經由他處經過 為甚麼你卻又聽的清楚
你站在我的面前 他站在我的身邊 忽然之間心裡又難過
為什麼
感謝
DJGhost
修正歌詞
==================================================
[Preprocessed Version]:
這首歌沒有唱過 但是是我寫的 然後 寫給一個好朋友的歌
那 我自己重新來唱 我覺得應該 版本真的也不錯
想別的 可是在你眼中察覺什麼一閃而過
怎是像是寂寞 於是我會更沉默
沒說的 可是在你眼中察覺什麼一閃而過
而我看她笑著走開 於是我裝做不懂 怎麼能拆穿你的不同
偏偏 這地球 這麼擠 這麼小 這麼瘦 太陽刻意曬得那麼兇
記得離別在拆散一點以後
你怎麼連話都說不清楚 那溫柔的 我聽得清楚
他站在我的身邊 你站在我的面前 怎麼這樣心裡會難過
你怎麼連話都說不清楚 那溫柔的痛我聽得清楚
你站在我的身邊 他經過我的面前 怎麼這樣心裡又難過 為什麼
想別的 可是我忽然察覺什麼一閃而過
於是像是寂寞 於是我會更沉默
沒說的 可是在你眼中察覺什麼一閃而過
於是像是寂寞 怎麼能拆穿不同 怎麼能拆穿你的不同
偏偏 這地球 這麼擠 這麼小 這麼瘦 太陽刻意曬得那麼兇
為什麼你出現在他出現以後
你怎麼連話都說不清楚 那溫柔的 我聽得清楚
我站在他的身邊 你站在我的面前 怎麼這樣心裡會難過
你怎麼連話都說不清楚 那溫柔的痛我記得清楚
他站在我的面前 你經過我的身邊 忽然之間心裡又難過 為什麼
經由他處經過 為甚麼你卻又聽的清楚
你站在我的面前 他站在我的身邊 忽然之間心裡又難過
為什麼
感謝
修正歌詞
Question 1-2#
Following the previous question, create a cluster analysis on all Jay’s songs and find out the similarities in-between Jay’s songs. Please pay attention to the following issues:
Use
ckip-transformerto word-seg the lyrics into word tokens.Please use TF-IDF weighted version of the bag-of-words representations for clustering.
Please include in the bag-of-word vectorization:
(a) words whose minimum document frequency = 2;
(b) words which have at least two characters (i.e., removing all one-character word tokens);
(c) words whose parts-of-speech tags indicate they are either NOUNS or VERBS. However, for nouns, please EXCLUDE words that are pronouns (e.g., 你 我 她) or numerals (e.g., 一 二 三). Specifically, include words whose POS tags start with
NorV, but exclude words tagged asNh(i.e., pronouns) orNeu(i.e., numerals).
Your output should be a dendrogram as shown below. A complete jpeg file of the dendrogram is also available in demo_data/midterm/question1-2-output-dendrogram.jpeg.
The Shape of the
CountVectorizerMatrix After Filtering: (Number_of_Songs,Number_of_Features)
Show code cell source
jay_bow_df.shape
(212, 2031)
Sample of the
CountVectorizerMatrix After Filtering:
Show code cell source
jay_bow_df
| 一下 | 一些 | 一切 | 一半 | 一幕幕 | 一樣 | 一次次 | 一生 | 一統 | 一行行 | ... | 默劇 | 默契 | 默片 | 點亮 | 點心 | 點頭 | 鼓勵 | 鼓掌 | 鼻子 | 龍捲風 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 我是如此相信 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 英雄 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 雙截棍 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 開不了口 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 床邊故事 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 大頭貼 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 不知不覺愛上你 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 熊貓人 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 哇靠 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 默 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
212 rows × 2031 columns
The Shape of the
TfidfVectorizerMatrix After Filtering: (Number_of_Songs,Number_of_Features)
Show code cell source
tv_matrix.shape
(212, 2031)
Sample of the
TfidfVectorizerMatrix After Filtering (Please use this weighted TF-IDF matrix for clustering):
Show code cell source
jay_tv_df.round(2)
| 一下 | 一些 | 一切 | 一半 | 一幕幕 | 一樣 | 一次次 | 一生 | 一統 | 一行行 | ... | 默劇 | 默契 | 默片 | 點亮 | 點心 | 點頭 | 鼓勵 | 鼓掌 | 鼻子 | 龍捲風 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 我是如此相信 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 英雄 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.13 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 雙截棍 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 開不了口 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 床邊故事 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 大頭貼 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 不知不覺愛上你 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 熊貓人 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 哇靠 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 默 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
212 rows × 2031 columns
The Pairwise Similarity Matrix of All Songs
Show code cell source
similarity_doc_df.round(2)
| 我是如此相信 | 英雄 | 雙截棍 | 開不了口 | 床邊故事 | 夜曲 + 竊愛 | 以父之名 | 美人魚 | 我要夏天 | 我的時代 | ... | 對不起 | 伊斯坦堡 | 反方向的鐘 | 情畫 | 兩個寂寞 | 大頭貼 | 不知不覺愛上你 | 熊貓人 | 哇靠 | 默 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 我是如此相信 | 1.00 | 0.00 | 0.00 | 0.01 | 0.10 | 0.09 | 0.08 | 0.01 | 0.02 | 0.02 | ... | 0.00 | 0.03 | 0.02 | 0.07 | 0.00 | 0.01 | 0.00 | 0.01 | 0.03 | 0.06 |
| 英雄 | 0.00 | 1.00 | 0.00 | 0.02 | 0.07 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | ... | 0.04 | 0.00 | 0.01 | 0.00 | 0.00 | 0.03 | 0.00 | 0.01 | 0.03 | 0.00 |
| 雙截棍 | 0.00 | 0.00 | 1.00 | 0.00 | 0.01 | 0.01 | 0.00 | 0.01 | 0.02 | 0.01 | ... | 0.00 | 0.03 | 0.00 | 0.01 | 0.02 | 0.01 | 0.03 | 0.12 | 0.01 | 0.00 |
| 開不了口 | 0.01 | 0.02 | 0.00 | 1.00 | 0.02 | 0.02 | 0.07 | 0.00 | 0.02 | 0.05 | ... | 0.03 | 0.05 | 0.03 | 0.02 | 0.02 | 0.03 | 0.00 | 0.05 | 0.04 | 0.00 |
| 床邊故事 | 0.10 | 0.07 | 0.01 | 0.02 | 1.00 | 0.04 | 0.03 | 0.01 | 0.09 | 0.01 | ... | 0.02 | 0.04 | 0.02 | 0.00 | 0.05 | 0.04 | 0.00 | 0.02 | 0.03 | 0.01 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 大頭貼 | 0.01 | 0.03 | 0.01 | 0.03 | 0.04 | 0.00 | 0.01 | 0.01 | 0.00 | 0.02 | ... | 0.03 | 0.03 | 0.00 | 0.00 | 0.03 | 1.00 | 0.00 | 0.00 | 0.02 | 0.00 |
| 不知不覺愛上你 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.02 | 0.00 | 0.04 | 0.00 | 0.06 | ... | 0.00 | 0.00 | 0.02 | 0.03 | 0.04 | 0.00 | 1.00 | 0.00 | 0.01 | 0.00 |
| 熊貓人 | 0.01 | 0.01 | 0.12 | 0.05 | 0.02 | 0.00 | 0.05 | 0.03 | 0.02 | 0.03 | ... | 0.03 | 0.03 | 0.02 | 0.00 | 0.02 | 0.00 | 0.00 | 1.00 | 0.06 | 0.00 |
| 哇靠 | 0.03 | 0.03 | 0.01 | 0.04 | 0.03 | 0.01 | 0.06 | 0.09 | 0.02 | 0.02 | ... | 0.02 | 0.03 | 0.05 | 0.01 | 0.02 | 0.02 | 0.01 | 0.06 | 1.00 | 0.02 |
| 默 | 0.06 | 0.00 | 0.00 | 0.00 | 0.01 | 0.03 | 0.00 | 0.00 | 0.00 | 0.03 | ... | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 1.00 |
212 rows × 212 columns
The Dendrogram of Songs
Question Two (50%)#
Question 2-1#
Use the datasets, demo_data/midterm/chinese_name_gender_train.txt (training set) and demo_data/midterm/chinese_name_gender_test.txt (testing set), to build a classifier to determine the gender of a Chinese name based on the bag-of-words model. The training set text file includes around 480,000 Chinese names and their gender labels (around 240,000 for each gender). All names have exactly three characters and they have been randomized.
The first step to the building of the classifier is text/name vectorization. Please create a NAME-by-FEATURE matrix using bag-of-words model. However, do not include all characters. Please include in the bag-of-words model only the following features:
Any Chinese characters that appear in the second position of the name (e.g., the
英in 蔡英文)Any Chinese characters that appear in the third position of the name (e.g., the
文in 蔡英文)Any Chinese character bigrams that appear in the second and the third characters of the name (i.e., the given name, e.g.,
英文in 蔡英文)
For all the above features, they will be included as classifying features only when they appear in at least 100 different names (i.e., the minimum document frequency threshold).
The expected output of Question 2-1 is the bag-of-word representation of all the names in the training set following the above filtering guidelines. A sample has been provided below.
A complete sample output of the name-by-feature matrix for the training set is also available in demo_data/midterm/question2-1-output-tv-matrix.csv. (It is stored as a data frame with the Chinese names as the index and feature names as the columns.)
For training data, the shape of the NOUN-by-FEATURE matrix is as follows: (
Number_of_Names_in_the_Training_Set,Number_of_Features)
Show code cell source
X_train_bow.shape
(480000, 975)
A Sample of the NOUN-by-FEATURE matrix (Training Set):
Show code cell source
X_train_bow_df.head()
| 一 | 丁 | 三 | 世 | 丙 | 中 | 丹 | 丹丹 | 乃 | 久 | ... | 麗萍 | 麗霞 | 麗麗 | 麟 | 黎 | 黎黎 | 鼎 | 齊 | 齡 | 龍 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 孫遠光 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 吳昌財 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 張俊達 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 馬豔蘭 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 宋燕敏 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 975 columns
In particular, bigrams that passed the minimum document frequency include (there are 287 bigrams):
Show code cell source
X_train_bow_df[[col for col in X_train_bow_df.columns if len(col)>1]].head()
| 丹丹 | 云云 | 亞娟 | 亞楠 | 亞男 | 亞萍 | 亞麗 | 亭亭 | 亮亮 | 佩佩 | ... | 麗珍 | 麗琴 | 麗紅 | 麗芳 | 麗英 | 麗華 | 麗萍 | 麗霞 | 麗麗 | 黎黎 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 孫遠光 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 吳昌財 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 張俊達 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 馬豔蘭 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 宋燕敏 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 287 columns
For testing data, the shape of the NOUN-by-FEATURE matrix is as follows : (
Number_of_Names_in_the_Testing_Set,Number_of_Features)Please note that the feature number should be exactly the same as the number of the vectorized matrix of the training set.
X_test_bow.shape
(120000, 975)
Question 2-2#
Following the previous question, please use the NAME-by-FEATURE matrix for classifier training (I used the Count-based version, i.e., CountVectorizer()). In order to find the best-performing classifier, please work on the following steps:
Try two ML algorithms,
sklearn.naive_bayes.GaussianNBandsklearn.linear_model.LogisticRegressionand determine which algorithm performs better using k-fold cross validation (k = 10). Report the average accuracies of cross-validation for each ML method.After cross-validation, you would see that Logistic Regression performs a lot better. In Logistic Regression, there is one hyperparameter
Cand different initial values of C may yield different performances as well. Use Grid Search to fine-tune this parameter from these values: C = [1, 5, 10]. (You may refer to sklearn’s Logistic Regression Documentation for more detail onC.)After determining the ML algorithm and hyperparameter tuning, evaluate your final model with the testing set, i.e.,
demo_data/midterm/chinese_name_gender_test.txt. Report the confusion matrix plot of the results as shown below.Present LIME explanations of your model on the gender prediction of the following four names:
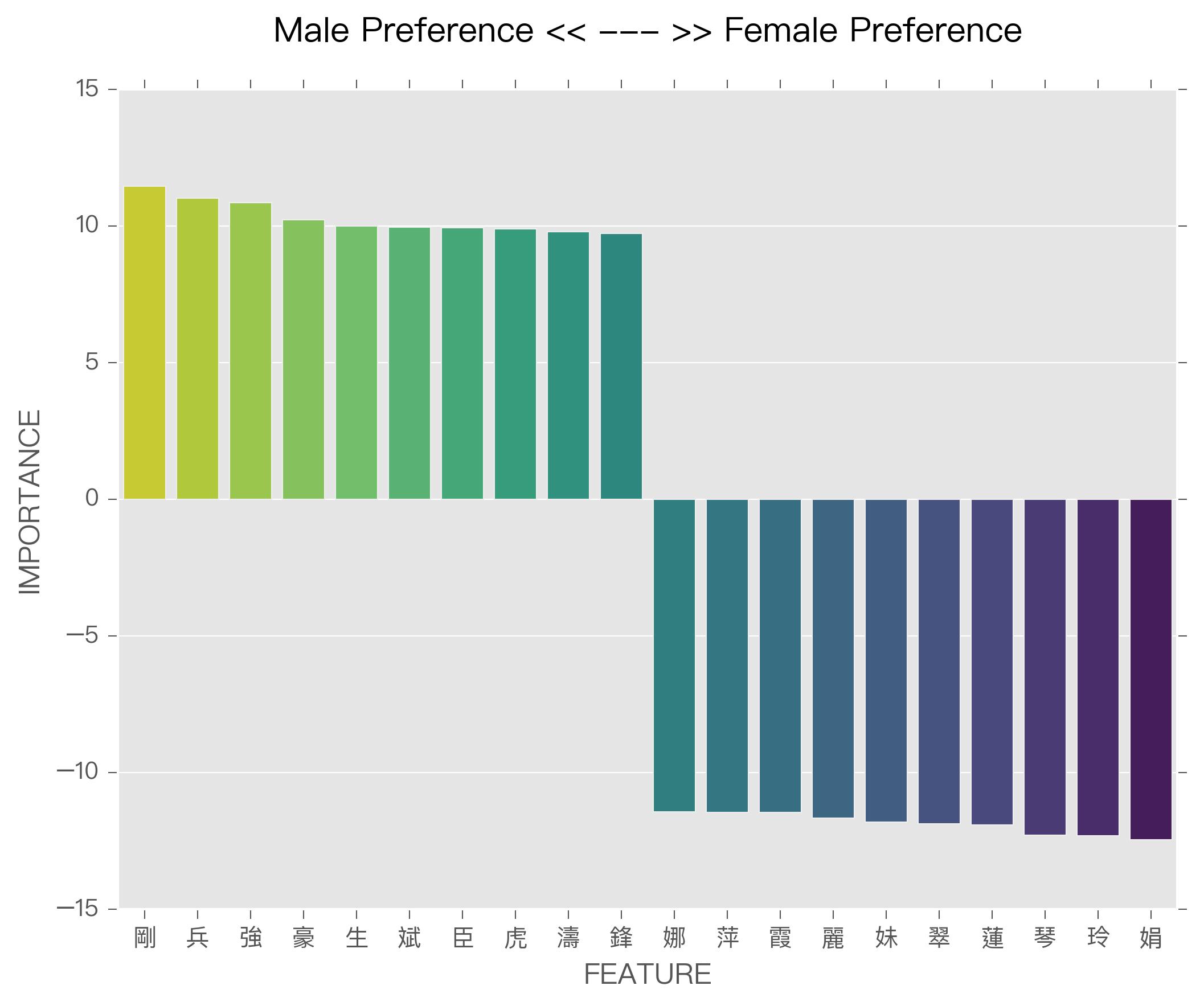
'王貴瑜','林育恩','張純映','陳英雲'.Finally, perform a post-hoc analysis of the feature importances by looking at the top 10 features of the largest coefficient values for each gender prediction (see below).
Cross Validation Results
Show code cell source
print("Mean Accuracy of Naive Bayes Model: ", model_gnb_acc.mean())
print("Mean Accuracy of Logistic Regression Model:", model_lg_acc.mean())
Mean Accuracy of Naive Bayes Model: 0.8543645833333334
Mean Accuracy of Logistic Regression Model: 0.9804437500000001
Best Hyperparameter for Logistic Regression from Grid Search:
Show code cell source
clf.best_params_
{'C': 10}
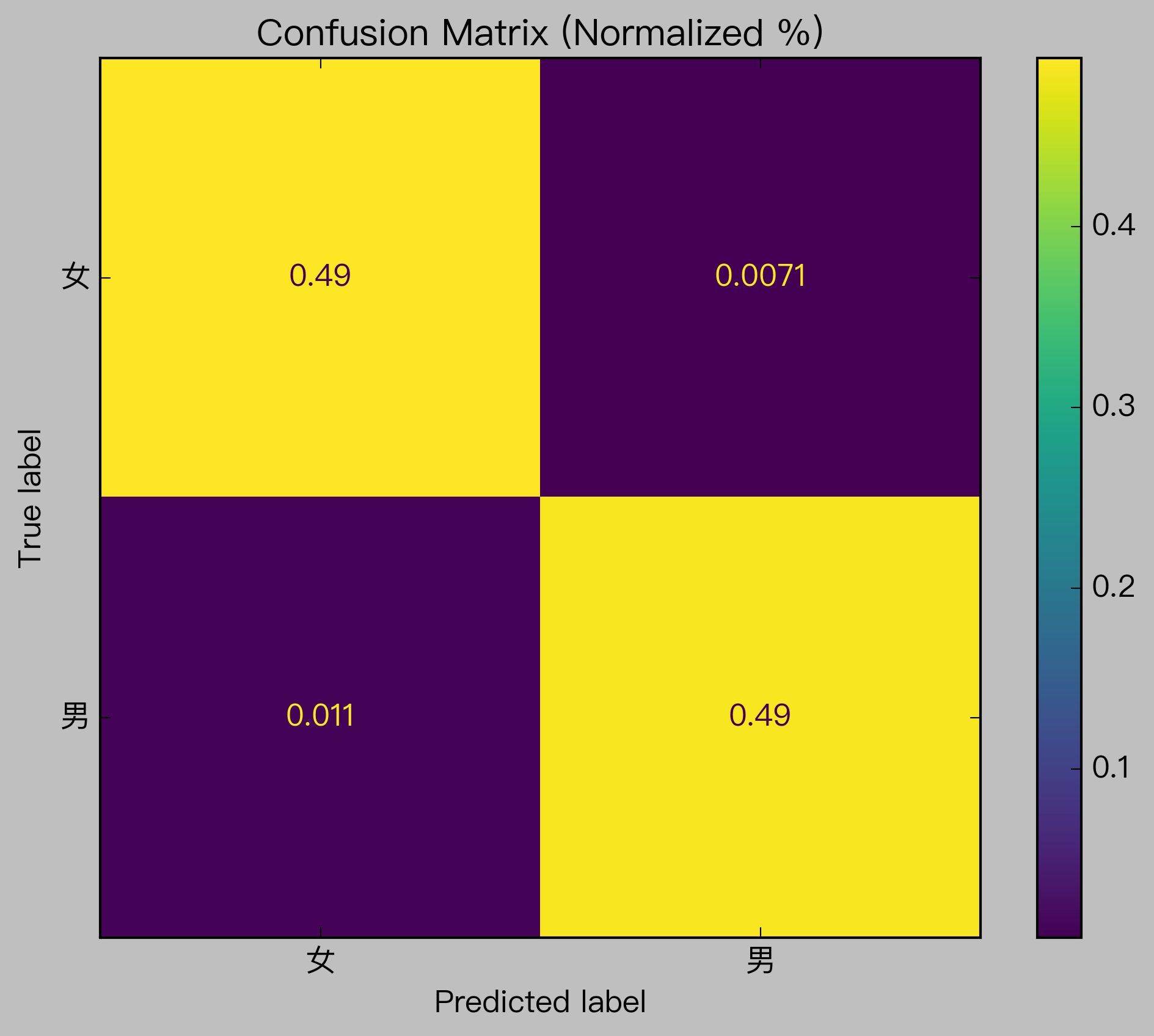
Confusion Matrix of the Final Model on Testing Set (Normalized):
Show code cell source
ConfusionMatrixDisplay.from_estimator(clf, X_test_bow, y_test, normalize='all')
#plot_confusion_matrix(clf, X_test_bow, y_test, normalize='all')
plt.title("Confusion Matrix (Normalized %)")
Text(0.5, 1.0, 'Confusion Matrix (Normalized %)')
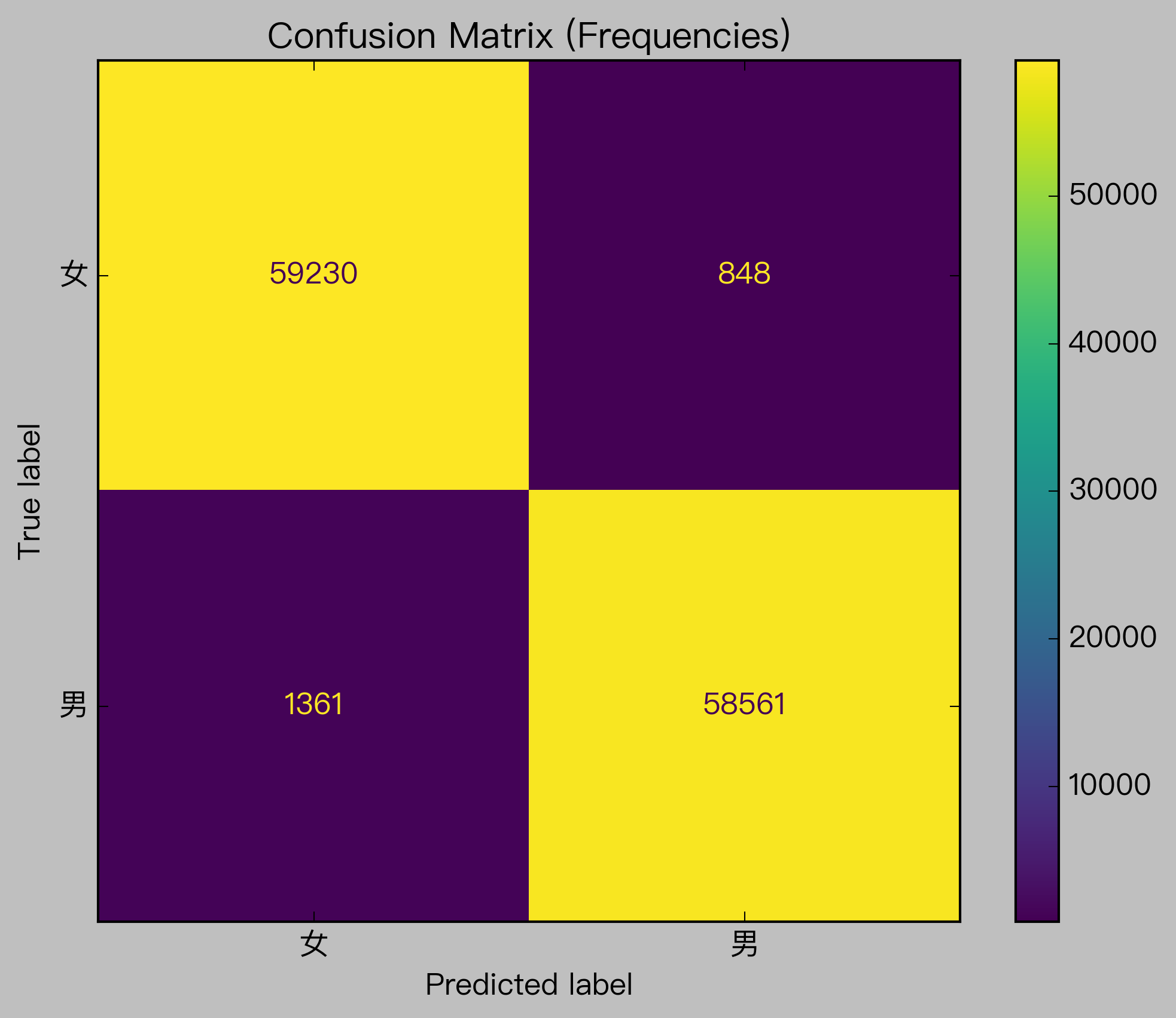
Show code cell source
ConfusionMatrixDisplay.from_estimator(clf, X_test_bow, y_test, normalize=None)
plt.title("Confusion Matrix (Frequencies)")
Text(0.5, 1.0, 'Confusion Matrix (Frequencies)')
LIME Explanations of Names:
Show code cell source
explanations[0].show_in_notebook(text=True)
Show code cell source
explanations[1].show_in_notebook(text=True)
Show code cell source
explanations[2].show_in_notebook(text=True)
Show code cell source
explanations[3].show_in_notebook(text=True)
Feature Coefficients Analysis of Logistic Regression Model (Note: The number of coefficients should be the same as the number of features used in training.)
Question Three (50%)#
Question 3-1#
This exercise requires the dataset, demo_data/midterm/apple5000.csv, which includes 5000 news articles from Apple Daily. Please use spacy and its pre-trained language model to extract word pairs of the dependency relation of amod. For example, in the following sequence:
"陸軍542旅下士洪仲丘關禁閉被操死,該旅副旅長何江忠昨遭軍高檢向最高軍事法院聲押獲准。何江忠的前同事說:「他(何江忠)只能用『陰險』兩字形容,得罪他都沒好下場。」還說他常用官威逼部下,「仗勢欺人、人神共憤,大家都不喜歡他。」被他帶過的阿兵哥說,懲處到了何手上都會加重,簡直是「大魔頭」。"
spacy identifies three token pairs showing a amod dependency relation, namely:
amod dep: 高 head: 軍事
amod dep: 前 head: 同事
amod dep: 大 head: 魔頭
Please note that the head and the dependent are NOT necessarily adjacent to each other. For example, in a sentence like:
"這是一個漂亮且美麗的作品,明亮的窗戶,房子很大。"
spacy identifies two token pairs showing a amod dependency relation, namely:
amod dep: 漂亮 head: 作品
amod dep: 明亮 head: 窗戶
With the apple5000.csv corpus, your job is to extract all word-pairs that show a amod dependency relation using spacy dependency parser. (These two word tokens may or may not be adjacent to each other.)
Please follow the following instructions for the analysis.
Preprocess each news article by removing symbols, punctuations, digits, and English alphabets (see the sample data frame below).
Parse all the articles using
spacyand extract word pairs showing theamoddependency relation.In
spacy, you can choose to use either the more efficient language modelzh_core_web_smor the more accurate modelzh_core_web_trf, depending on your hardware available. The sample results below are based onzh_core_web_trf.In your final report, please include only word pairs where the nouns are of AT LEAST two syllables/characters. Your final report is a frequency list of these word pairs (see the sample data frame below for the top 50 frequent pairs).
A sample output csv is provided in
demo_data/midterm/question3-1-output-modnounfreq.csv.Please note that your results may vary due to the selection of the pretrained language models in spacy. This is OK.
Examples of Raw Texts and Preprocessed Texts
Show code cell source
apple_df.head()
| doc_id | text | text_pre | |
|---|---|---|---|
| 0 | 1 | 【鄧玉瑩╱台中報導】台中市警二分局育才派出所爆發疑似集體索賄案,台中地檢署檢察官指揮調查局中部機動組查出,轄區警員柯文山利用職權之便,向轄區飯店、色情業者索賄,昨天深夜向地院聲請羈押獲准。派出所隨即表示,將對柯某撤職查辦、從嚴處分。\n\n\n台中地檢署檢察官吳祚延指揮調查局中機組幹員,搜索台中市警二分局育才派出所,帶回警員柯文山,進行偵訊。檢調同時到台中市「合利太」飯店大樓展開搜索,除帶... | 鄧玉瑩 台中報導 台中市警二分局育才派出所爆發疑似集體索賄案 台中地檢署檢察官指揮調查局中部機動組查出 轄區警員柯文山利用職權之便 向轄區飯店 色情業者索賄 昨天深夜向地院聲請羈押獲准 派出所隨即表示 將對柯某撤職查辦 從嚴處分\n台中地檢署檢察官吳祚延指揮調查局中機組幹員 搜索台中市警二分局育才派出所 帶回警員柯文山 進行偵訊 檢調同時到台中市 合利太 飯店大樓展開搜索 除帶回帳冊 飯店... |
| 1 | 2 | 陸軍542旅下士洪仲丘關禁閉被操死,該旅副旅長何江忠昨遭軍高檢向最高軍事法院聲押獲准。何江忠的前同事說:「他(何江忠)只能用『陰險』兩字形容,得罪他都沒好下場。」還說他常用官威逼部下,「仗勢欺人、人神共憤,大家都不喜歡他。」被他帶過的阿兵哥說,懲處到了何手上都會加重,簡直是「大魔頭」。\n曾與何江忠共事1年的軍官昨向《蘋果》爆料,前年何江忠還在馬祖東引擔任副指揮官時,遇到年度本職學能鑑測,... | 陸軍 旅下士洪仲丘關禁閉被操死 該旅副旅長何江忠昨遭軍高檢向最高軍事法院聲押獲准 何江忠的前同事說 他 何江忠 只能用 陰險 兩字形容 得罪他都沒好下場 還說他常用官威逼部下 仗勢欺人 人神共憤 大家都不喜歡他 被他帶過的阿兵哥說 懲處到了何手上都會加重 簡直是 大魔頭\n曾與何江忠共事 年的軍官昨向 蘋果 爆料 前年何江忠還在馬祖東引擔任副指揮官時 遇到年度本職學能鑑測 他卻要步兵學校裁... |
| 2 | 3 | 終於拿到冠軍,感覺真是棒,尤其是從蔣宸豑的手上搶過來,算是報了一箭之仇。其實我今天的推桿感覺真的很不好,有好幾次3呎內的短推都錯過,不然也不會打得這麼累。」今年第3次參賽,前兩次分別在第1輪及8強賽輸給蔣宸豑。\n\n\n年齡:17歲身高:181公分體重:80公斤就讀學校:啟英高中二年級球齡:6年\n\n\n \n | 終於拿到冠軍 感覺真是棒 尤其是從蔣宸豑的手上搶過來 算是報了一箭之仇 其實我今天的推桿感覺真的很不好 有好幾次 呎內的短推都錯過 不然也不會打得這麼累 今年第 次參賽 前兩次分別在第 輪及 強賽輸給蔣宸豑\n年齡 歲身高 公分體重 公斤就讀學校 啟英高中二年級球齡 年\n\n |
| 3 | 4 | 【陳毓婷╱台北報導】過去業績不甚理想的中國人壽(2823),今年初找來南山人壽的專業經理人王銘陽擔任總經理後,不但保費收入大幅成長,而且獲利也出現轉機,今年上年已經轉虧為盈,小賺667萬元,擺脫今年第一季虧損近1.6億元的陰霾。\n\n\n中壽今年上半年的保費收入達155.7億元,較去年同期的96.6億元成長62%,與國內壽險業今年上半年保費收入比較,中壽首度擠進前五名。通常壽險公司在衝刺... | 陳毓婷 台北報導 過去業績不甚理想的中國人壽 今年初找來南山人壽的專業經理人王銘陽擔任總經理後 不但保費收入大幅成長 而且獲利也出現轉機 今年上年已經轉虧為盈 小賺 萬元 擺脫今年第一季虧損近 億元的陰霾\n中壽今年上半年的保費收入達 億元 較去年同期的 億元成長 與國內壽險業今年上半年保費收入比較 中壽首度擠進前五名 通常壽險公司在衝刺新契約保單的情況下 成本支出會墊高 中壽今年第 季就... |
| 4 | 5 | 台灣國際語文教育協會假借中央機關指導名義,招攬學員參加該機構舉辦的觀光研習營,活動宣稱「參加滿三梯次可退費」,實際上卻任意改期、提高收費。學員幾經爭執、《蘋果》追查發現真相後,業者同意學員的退費要求。攝影.報導╱褚明達\n台中市徐先生說,去年10月下旬,他看到台灣國際語文教育協會(以下簡稱台協)招攬「台灣觀光親善大使甄選研習營」學員的網路廣告,因內容豐富,他立即報名參加。台協在廣告上註明將... | 台灣國際語文教育協會假借中央機關指導名義 招攬學員參加該機構舉辦的觀光研習營 活動宣稱 參加滿三梯次可退費 實際上卻任意改期 提高收費 學員幾經爭執 蘋果 追查發現真相後 業者同意學員的退費要求 攝影 報導 褚明達\n台中市徐先生說 去年 月下旬 他看到台灣國際語文教育協會 以下簡稱台協 招攬 台灣觀光親善大使甄選研習營 學員的網路廣告 因內容豐富 他立即報名參加 台協在廣告上註明將請 外... |
Number of MOD-NOUN Types:
Show code cell source
len(mod_head_df)
28496
Top 50 Frequent MOD-NOUN Showing
amoddependency relation in Apple News:
Show code cell source
mod_head_df.sort_values(['Frequency'],ascending=[False]).head(50)
| MOD-NOUN | Frequency | |
|---|---|---|
| 223 | 新_台幣 | 108 |
| 750 | 女_主角 | 81 |
| 641 | 綜合_報導 | 76 |
| 86 | 月_營收 | 71 |
| 258 | 數位_相機 | 48 |
| 30 | 大_股東 | 44 |
| 471 | 主治_醫師 | 43 |
| 1054 | 男_主角 | 39 |
| 234 | 新_產品 | 38 |
| 96 | 稅後_純益 | 37 |
| 170 | 好_朋友 | 37 |
| 34 | 最高_法院 | 36 |
| 193 | 新_專輯 | 36 |
| 635 | 相關_資訊 | 35 |
| 91 | 稅前_盈餘 | 35 |
| 1231 | 前_女友 | 33 |
| 308 | 智慧型_手機 | 32 |
| 130 | 相關_單位 | 32 |
| 342 | 前_總統 | 32 |
| 1489 | 高速_公路 | 31 |
| 10021 | 聚酯_纖維 | 31 |
| 1831 | 筆記型_電腦 | 31 |
| 98 | 前_盈餘 | 31 |
| 291 | 大_聯盟 | 30 |
| 324 | 快速_道路 | 29 |
| 2336 | 小_女孩 | 29 |
| 2759 | 大_台北 | 29 |
| 978 | 前_男友 | 28 |
| 463 | 新_政府 | 26 |
| 315 | 國立_大學 | 26 |
| 1305 | 有限_公司 | 26 |
| 200 | 先發_投手 | 26 |
| 314 | 助理_教授 | 26 |
| 580 | 女_學生 | 25 |
| 1159 | 大_尺寸 | 24 |
| 207 | 發_投手 | 24 |
| 3087 | 基本_工資 | 24 |
| 1883 | 中小_企業 | 23 |
| 2912 | 附設_醫院 | 23 |
| 1776 | 大_公司 | 22 |
| 2371 | 知名_品牌 | 22 |
| 888 | 市立_醫院 | 21 |
| 2290 | 不_動產 | 21 |
| 1592 | 同性_婚姻 | 21 |
| 708 | 高等_法院 | 20 |
| 1468 | 地下_錢莊 | 20 |
| 607 | 小_黃瓜 | 19 |
| 5935 | 突發_中心 | 19 |
| 572 | 實際_價格 | 19 |
| 778 | 加護_病房 | 18 |
Question 3-2#
Following the previous question, with the extracted MODIFIER-NOUN word pairs, please create a NOUN-by-MODIFIER co-occurrence table, showing the co-occurring frequencies of a particular noun (i.e., the row) and a particular modifier (i.e., the column) (see the sample data frame below).
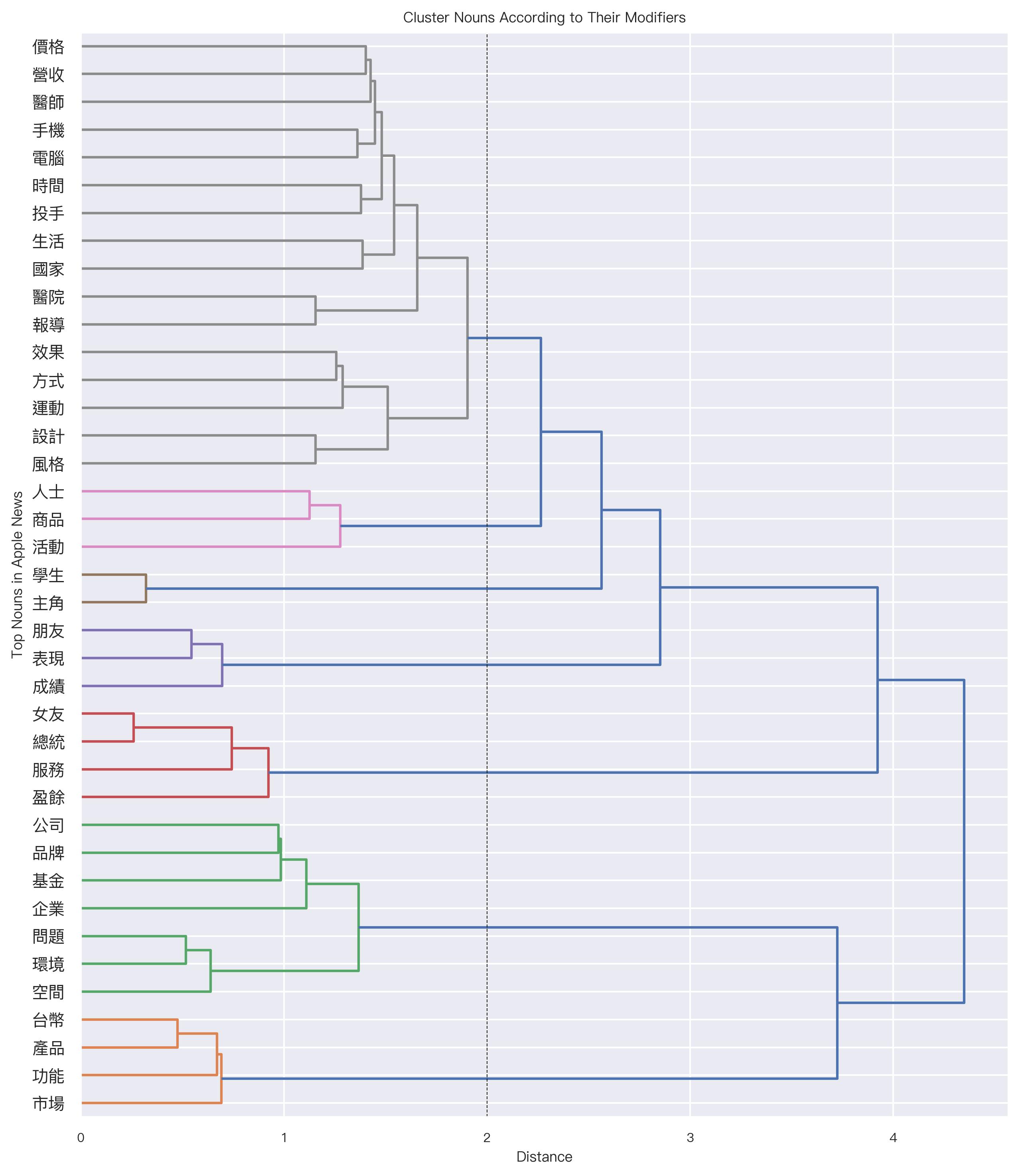
In addition, with a co-occurrence matrix like this, we can cluster the NOUNS according their co-occurring patterns with different modifiers. That is, please perform a cluster analysis on the NOUNS, using their co-occurring frequencies with the MODIFIERS as the features. In particular, among all these modifier-noun pairs:
please include nouns whose total frequencies are > 70 (i.e., given the NOUN-by-MODIFIER matrix, you need to include only rows whose row sums are > 70)
please include modifiers whose total frequencies are > 10 (i.e., given the NOUN-by-MODIFIER matrix, you need to include only columns whose column sums are > 10)
perform the cluster analysis using the default settings used in the lecture notes (i.e., cosine similarity, linkage of ward’s method).
Important
In case you fail to create the output from Question 3-1, you can use the sample output csv, demo_data/midterm/question3-1-output-modnounfreq.csv, as your starting point for this exercise.
The csv file is the expected output from Question 3-1, including all the MODIFIER-NOUN pairs identified by spacy and their frequency counts in the corpus. (As specified in Question 3-1, bigrams with one-syllable nouns have been removed from the list.)
Before filtering, the shape of the NOUN-by-MODIFIER co-occurrence matrix should be as follows: (
Number_of_Noun_Types,Number_of_Modifier_Types)
Show code cell source
print(noun_by_mod.shape)
(11718, 9243)
Noun-by-Modifier Co-occurrence Matrix After Filtering
Show code cell source
noun_by_mod_filtered_df
| 進一步 | 世界 | 下列 | 親密 | 免費 | 單親 | 彩色 | 甜美 | 暢銷 | 優惠 | ... | 以下 | 歲 | 地 | 冷 | 極大 | 難得 | 自由 | 有趣 | 原 | 淡淡 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 企業 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 設計 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 價格 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 5.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 時間 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 運動 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 4.00 | 0.00 | 0.00 | 0.00 |
| 報導 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 台幣 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 活動 | 0.00 | 0.00 | 0.00 | 0.00 | 3.00 | 0.00 | 0.00 | 0.00 | 0.00 | 4.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 手機 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 盈餘 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 女友 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 醫師 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 |
| 產品 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 |
| 成績 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 基金 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 風格 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 朋友 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 方式 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ... | 14.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 |
| 公司 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 學生 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 國家 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 環境 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 功能 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 醫院 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 主角 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 問題 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 營收 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 空間 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 品牌 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 投手 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 表現 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 市場 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.00 | 0.00 | 0.00 | 0.00 |
| 商品 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.00 | 3.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 服務 | 0.00 | 0.00 | 0.00 | 0.00 | 4.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 電腦 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 效果 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 人士 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 總統 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 生活 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
39 rows × 587 columns
After filtering, the shape of the NOUN-by-MODIFIER co-occurrence matrix should be as follows: (
Number_of_Noun_Types,Number_of_Modifier_Types)
Show code cell source
noun_by_mod_filtered_df.shape
(39, 587)
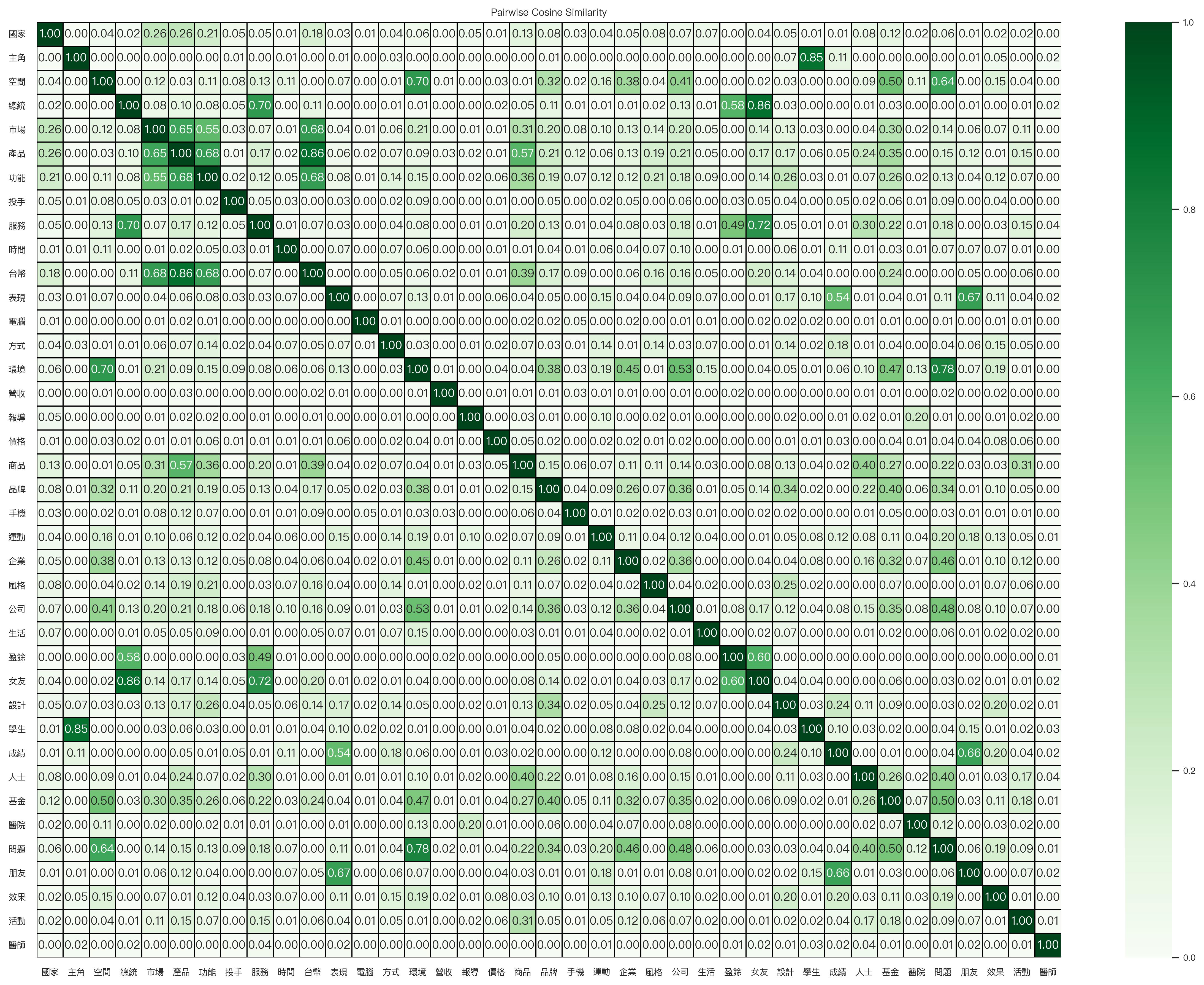
Pairwise Cosine Similarity Matrix for Nouns Whose Frequency > 70
The Cluster Result, the Dengrogram: