Deep Learning: Sentiment Analysis#
In this unit, we will build a deep-learning-based sentiment classifier on the movie reviews from
ntlk.
Contents
Prepare Data#
import numpy as np
import nltk
from nltk.corpus import movie_reviews
import random
## Colab Only
nltk.download('movie_reviews')
nltk.download('stopwords')
[nltk_data] Downloading package movie_reviews to /root/nltk_data...
[nltk_data] Unzipping corpora/movie_reviews.zip.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
True
documents = [(' '.join(list(movie_reviews.words(fileid))), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
documents = [(text, 1) if label == "pos" else (text, 0)
for (text, label) in documents]
random.shuffle(documents)
documents[1]
('there is nothing like american history x in theaters or on video . no other feature film takes such a cold hard look at the lure , the culture , and the brotherhood of white supremacy . nice guy ed norton jr . ( who sang in everyone says i love you ) plays derek , a twenty - year old skinhead . dad \' s subtle racism grew large in derek , after gang members killed his father . dad was fighting a fire when they shot him . now derek keeps his head shaved and has a giant swastika tattooed over his heart . derek is more interested in the ideas of white supremacy than in its culture of violence . at a basketball court , black and white tempers flare . derek channels the aggression into a game , black versus white , for ownership of the courts . when the choice presents itself , derek goes for game point instead of the sucker - punch . cameron ( stacy keach ) steps in to derek \' s life as a surrogate father . he takes derek under his wing and nurtures his racist feelings . keeping his own criminal record spotless , he uses derek as a leader and organizer for high - visibility racial intimidation . derek obliges by leading his younger and dumber friends in race - motivated mob crimes . at the bottom of the chain , derek \' s younger brother danny ( edward furlong , made famous in terminator 2 ) joins the skinheads not for ideological or intellectual reasons , but because he admires his brother and he wants to belong . one night three black youths break into derek \' s truck , which is exactly what derek has been waiting for . outside in his shorts and his tattoo , he shoots them all . the third would - be thief , unarmed , is only wounded . in the key scene of the film , derek commands the kid into a position where he can be killed with one glorious , enraptured , awful stomp . ( the fun - spoiling nc - 17 of orgazmo seems even more inappropriate , considering american history x was rated r . what sort of country is this that says sex comedies are a bigger threat to our youth than brutal , ecstatic violence ? ) the police arrive just as derek kills the last thief . derek does not resist the cops , and as they spin him around to cuff him , the film slows down . derek raises his eyebrows and smiles at his little brother in a chilling , sadistic , satisfied grin . now in prison , derek faces new challenges . as the black man in the laundry tells him , " in the joint , you the nigra , not me . " there is a clique of swastika - wearing skinheads , but they are not interested in the ideology of white supremacy . they only use the symbols as a means of intimidation . derek finds himself truly alone , truly in danger , and truly afraid . when derek finally gets out of prison , he finds that his friends from the gang have also changed . without derek \' s leadership , they have shunned the white supremacist ideology for the white supremacist culture . it is the final factor that makes him realize how badly he \' s screwed up . in the end , he spends quality time with is brother trying to undo the respect and admiration he had earlier inspired in danny . the film ends a little too deliberately , too neatly after the unchained emotion and violent glee of the rest of the film , but it barely detracts from the overall experience . edward norton gives an oscar - worthy performance . although some of his dialogue seemed to be written without enough conviction , norton \' s performance compensated . ( an example that comes to mind is his pep talk before looting the store . ) he also captured the essence of an older brother . he took his responsibility as a role model to his younger brother very seriously , very lovingly , both before and after his change of heart . though clearly not for all tastes , this film is bold and daring . the subject matter is ugly , cruel , and at times hard to look at . nevertheless its subjects are part of humanity \' s great face . kaye gives us a good look at this fascinating , if distasteful , american subculture .',
1)
Train-Test Split#
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(documents,
test_size=0.1,
random_state=42)
print(len(train_set), len(test_set))
1800 200
Prepare Input and Output Tensors#
For text vectorization, we will implement two alternatives:
Texts to Matrix: One-hot encoding of texts (similar to bag-of-words model)
Texts to Sequences: Integer encoding of all word tokens in texts and we will learn token embeddings along with the networks
Important Steps:
Split data into X (texts) and y (sentiment labels)
Initialize
TokenizerUse the
Tokenizerfortext_to_sequences()ortext_to_matrix()Padding the sequences to uniform lengths if needed (this can be either the max length of the sequences or any arbitrary length)
## Dependencies
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras import layers, Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, LSTM, Embedding
from tensorflow.keras.layers import Bidirectional, Concatenate
from tensorflow.keras.layers import Attention
from tensorflow.keras.layers import GlobalAveragePooling1D
## Split data into X (texts) and y (labels)
texts = [n for (n, l) in train_set]
labels = [l for (n, l) in train_set]
print(len(texts))
print(len(labels))
1800
1800
Tokenizer#
Important Notes:
We set the
num_wordsat 10000, meaning that theTokenizerwill automatically include only the most frequent 10000 words in the later text vectorization.In other words, when we perform
text_to_sequences()later, theTokenizerwill automatically remove words that are NOT in the top 10000 words.However, the
tokenizerstill keeps the integer indices of all the words in the training texts (i.e.,tokenizer.word_index)
NUM_WORDS = 10000
tokenizer = Tokenizer(num_words=NUM_WORDS)
tokenizer.fit_on_texts(texts)
Vocabulary#
When computing the vocabulary size, the plus 1 is due to the addition of the padding token.
If
oov_tokenis specified, then the vocabulary size needs to be added one more.When
oov_tokenis specified, the unknown word tokens (i.e., words that are not in the top 10000 words) will be replaced with thisoov_tokentoken, instead of being removed from the texts.
# determine the vocabulary size
# vocab_size = len(tokenizer.word_index) + 1
vocab_size = tokenizer.num_words + 1
print('Vocabulary Size: %d' % vocab_size)
Vocabulary Size: 10001
list(tokenizer.word_index.items())[:20]
[('the', 1),
('a', 2),
('and', 3),
('of', 4),
('to', 5),
("'", 6),
('is', 7),
('in', 8),
('s', 9),
('it', 10),
('that', 11),
('as', 12),
('with', 13),
('for', 14),
('this', 15),
('film', 16),
('his', 17),
('i', 18),
('he', 19),
('but', 20)]
len(tokenizer.word_index)
37775
Define X and Y (Text Vectorization)#
Method 1: Text to Sequences#
Text to sequences (integers)
Pad sequences
Text to Sequences#
texts_ints = tokenizer.texts_to_sequences(texts)
print(len(texts[1000].split(' '))) ## original text word number
print(len(texts_ints[1000])) ## sequence token number
514
425
Padding#
When dealing with texts and documents, padding each text to the maximum length may not be ideal.
For example, for sentiment classification, it is usually the case that authors would more clearly reveal/highlight his/her sentiment at the end of the text.
Therefore, we can specify an arbitrary
max_lenin padding the sequences to (a) reduce the risk of including too much noise in our model, and (b) speed up the training steps.
## Check the text len distribution
texts_lens = [len(n) for n in texts_ints]
texts_lens
import seaborn as sns
sns.displot(texts_lens)
/Users/alvinchen/anaconda3/envs/python-notes/lib/python3.9/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
<seaborn.axisgrid.FacetGrid at 0x331d56940>
## Find the maxlen of the texts
max_len = texts_lens[np.argmax(texts_lens)]
max_len
2339
In this tutorial, we consider only the final 400 tokens of each text, using the following parameters for
pad_sequences().We keep the final 400 tokens from the text (
truncating='pre').If the text is shorter than 400 tokens, we pad the text to 400 tokens at the beginning of the text (
padding='pre').
## Padding
max_len = 400
texts_ints_pad = sequence.pad_sequences(texts_ints,
maxlen=max_len,
truncating='pre',
padding='pre')
texts_ints_pad[:10]
array([[1605, 3571, 1356, ..., 6, 118, 2143],
[ 0, 0, 0, ..., 310, 42, 2921],
[ 15, 2373, 69, ..., 1208, 3, 226],
...,
[ 0, 0, 0, ..., 8, 291, 10],
[ 1, 83, 2147, ..., 33, 39, 4910],
[ 40, 74, 7, ..., 6, 9, 9477]], dtype=int32)
## Gereate X and y for training
X_train = np.array(texts_ints_pad).astype('int32')
y_train = np.array(labels)
## Gereate X and y for testing in the same way
X_test_texts = [n for (n, l) in test_set]
X_test = np.array(
sequence.pad_sequences(tokenizer.texts_to_sequences(X_test_texts),
maxlen=max_len,
padding='pre',
truncating='pre')).astype('int32')
y_test = np.array([l for (n, l) in test_set])
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(1800, 400)
(1800,)
(200, 400)
(200,)
Method 2: Text to Matrix (One-hot Encoding/Bag-of-Words)#
## Texts to One-Hot Encoding (bag of words)
texts_matrix = tokenizer.texts_to_matrix(texts, mode="binary")
X_train2 = np.array(texts_matrix).astype('int32')
y_train2 = np.array(labels)
## Same for Testing Data
X_test2 = tokenizer.texts_to_matrix(X_test_texts,
mode="binary").astype('int32')
y_test2 = np.array([l for (n, l) in test_set])
print(X_train2.shape)
print(y_train2.shape)
print(X_test2.shape)
print(y_test2.shape)
(1800, 10000)
(1800,)
(200, 10000)
(200,)
Hyperparameters#
## A few DL hyperparameters
BATCH_SIZE = 128
EPOCHS = 25
VALIDATION_SPLIT = 0.2
EMBEDDING_DIM = 128
Model Definition (Part 1)#
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
matplotlib.rcParams['figure.dpi'] = 150
# Plotting results
def plot1(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
## Accuracy plot
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
## Loss plot
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
def plot2(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
#plt.gca().set_ylim(0,1)
plt.show()
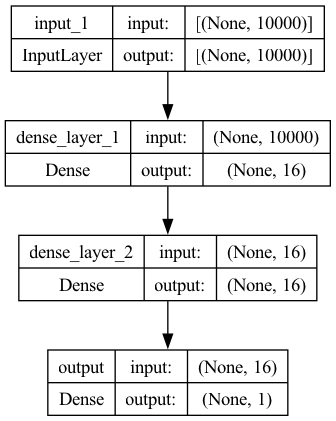
Model 1 (Feedforward Neural Network)#
Two layers of fully-connected dense layers
The input is the one-hot encoding of the text from text-to-matrix.
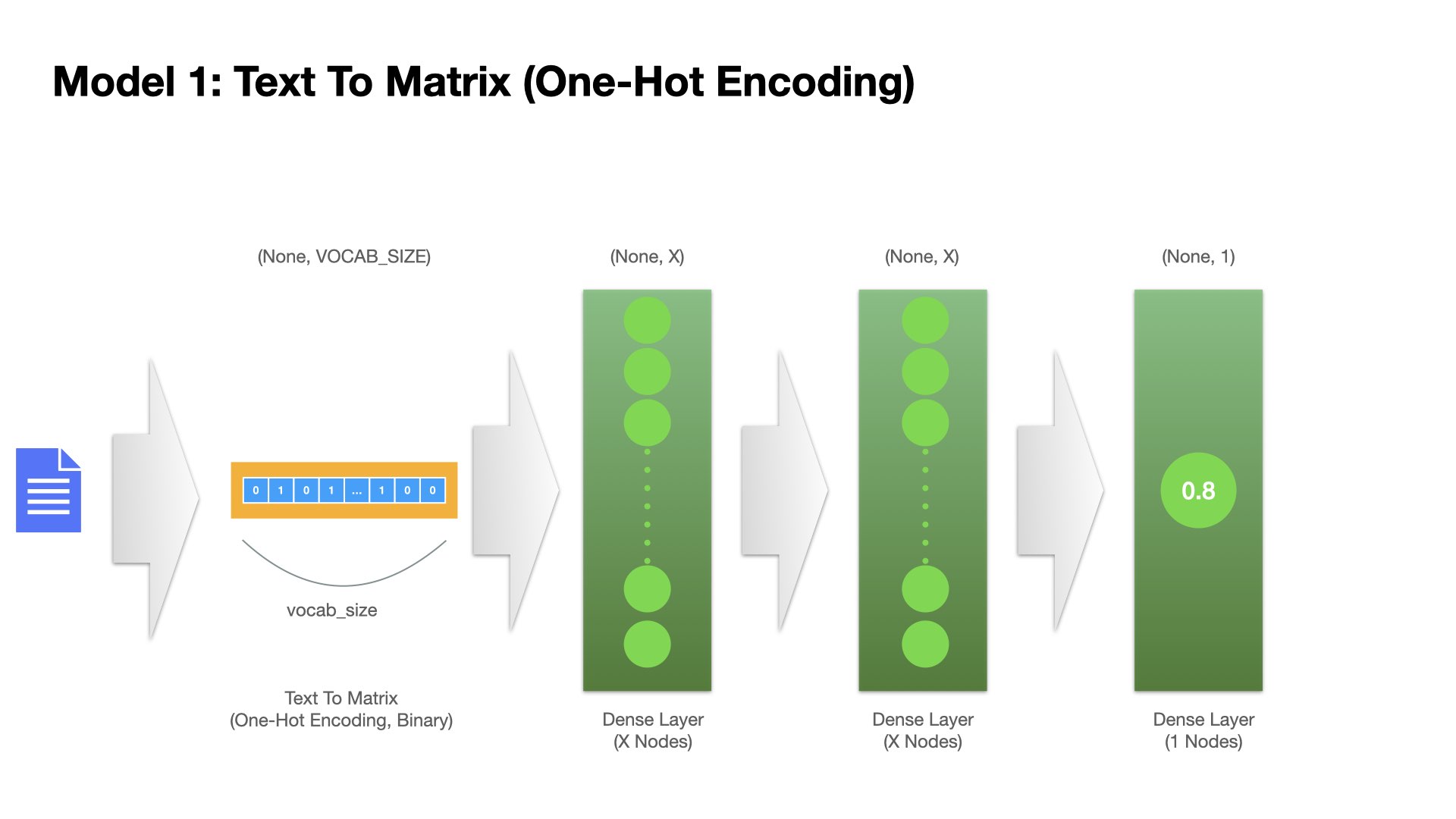
## Model 1
model1 = Sequential()
model1.add(Input(shape=(NUM_WORDS, )))
model1.add(Dense(16, activation="relu", name="dense_layer_1"))
model1.add(Dense(16, activation="relu", name="dense_layer_2"))
model1.add(Dense(1, activation="sigmoid", name="output"))
model1.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model1, show_shapes=True)
history1 = model1.fit(X_train2,
y_train2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
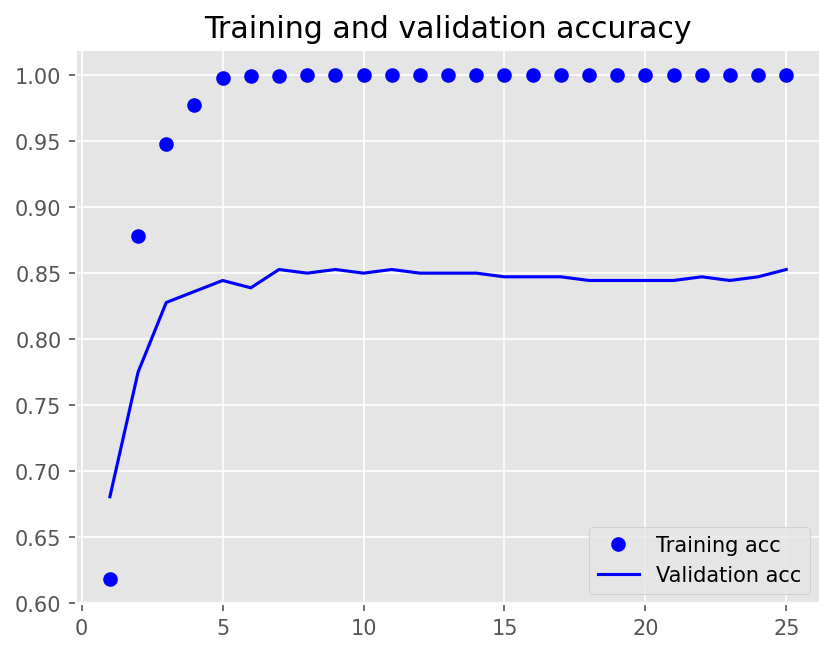
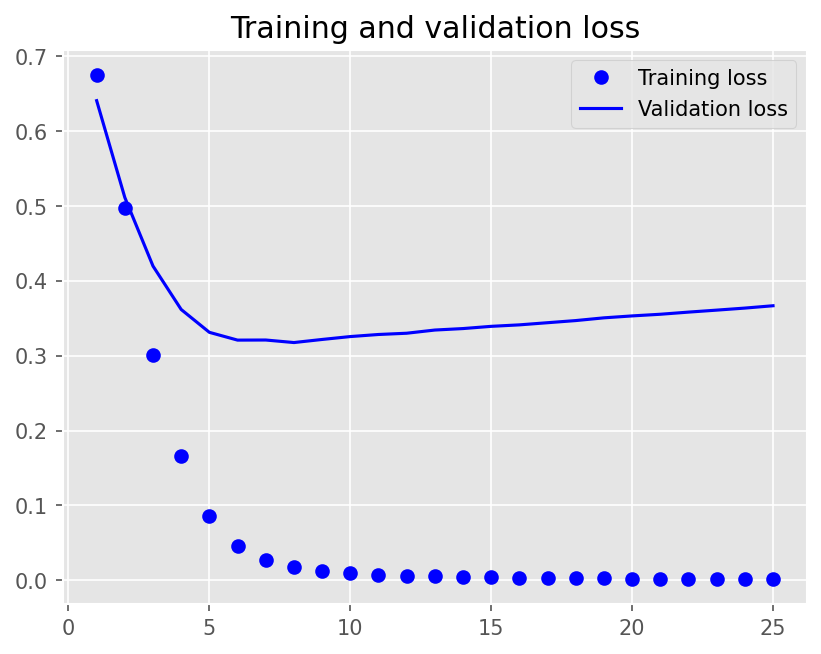
Epoch 1/25
12/12 - 1s - loss: 0.6749 - accuracy: 0.6181 - val_loss: 0.6408 - val_accuracy: 0.6806 - 1s/epoch - 90ms/step
Epoch 2/25
12/12 - 0s - loss: 0.4979 - accuracy: 0.8785 - val_loss: 0.5114 - val_accuracy: 0.7750 - 95ms/epoch - 8ms/step
Epoch 3/25
12/12 - 0s - loss: 0.3008 - accuracy: 0.9479 - val_loss: 0.4198 - val_accuracy: 0.8278 - 95ms/epoch - 8ms/step
Epoch 4/25
12/12 - 0s - loss: 0.1666 - accuracy: 0.9771 - val_loss: 0.3618 - val_accuracy: 0.8361 - 93ms/epoch - 8ms/step
Epoch 5/25
12/12 - 0s - loss: 0.0858 - accuracy: 0.9979 - val_loss: 0.3312 - val_accuracy: 0.8444 - 95ms/epoch - 8ms/step
Epoch 6/25
12/12 - 0s - loss: 0.0455 - accuracy: 0.9993 - val_loss: 0.3209 - val_accuracy: 0.8389 - 90ms/epoch - 7ms/step
Epoch 7/25
12/12 - 0s - loss: 0.0265 - accuracy: 0.9993 - val_loss: 0.3210 - val_accuracy: 0.8528 - 90ms/epoch - 8ms/step
Epoch 8/25
12/12 - 0s - loss: 0.0172 - accuracy: 1.0000 - val_loss: 0.3176 - val_accuracy: 0.8500 - 89ms/epoch - 7ms/step
Epoch 9/25
12/12 - 0s - loss: 0.0123 - accuracy: 1.0000 - val_loss: 0.3217 - val_accuracy: 0.8528 - 90ms/epoch - 7ms/step
Epoch 10/25
12/12 - 0s - loss: 0.0094 - accuracy: 1.0000 - val_loss: 0.3256 - val_accuracy: 0.8500 - 90ms/epoch - 7ms/step
Epoch 11/25
12/12 - 0s - loss: 0.0075 - accuracy: 1.0000 - val_loss: 0.3284 - val_accuracy: 0.8528 - 88ms/epoch - 7ms/step
Epoch 12/25
12/12 - 0s - loss: 0.0062 - accuracy: 1.0000 - val_loss: 0.3300 - val_accuracy: 0.8500 - 88ms/epoch - 7ms/step
Epoch 13/25
12/12 - 0s - loss: 0.0052 - accuracy: 1.0000 - val_loss: 0.3343 - val_accuracy: 0.8500 - 88ms/epoch - 7ms/step
Epoch 14/25
12/12 - 0s - loss: 0.0044 - accuracy: 1.0000 - val_loss: 0.3363 - val_accuracy: 0.8500 - 88ms/epoch - 7ms/step
Epoch 15/25
12/12 - 0s - loss: 0.0038 - accuracy: 1.0000 - val_loss: 0.3393 - val_accuracy: 0.8472 - 88ms/epoch - 7ms/step
Epoch 16/25
12/12 - 0s - loss: 0.0033 - accuracy: 1.0000 - val_loss: 0.3412 - val_accuracy: 0.8472 - 86ms/epoch - 7ms/step
Epoch 17/25
12/12 - 0s - loss: 0.0029 - accuracy: 1.0000 - val_loss: 0.3441 - val_accuracy: 0.8472 - 88ms/epoch - 7ms/step
Epoch 18/25
12/12 - 0s - loss: 0.0026 - accuracy: 1.0000 - val_loss: 0.3470 - val_accuracy: 0.8444 - 90ms/epoch - 7ms/step
Epoch 19/25
12/12 - 0s - loss: 0.0023 - accuracy: 1.0000 - val_loss: 0.3506 - val_accuracy: 0.8444 - 86ms/epoch - 7ms/step
Epoch 20/25
12/12 - 0s - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.3532 - val_accuracy: 0.8444 - 87ms/epoch - 7ms/step
Epoch 21/25
12/12 - 0s - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.3554 - val_accuracy: 0.8444 - 86ms/epoch - 7ms/step
Epoch 22/25
12/12 - 0s - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.3583 - val_accuracy: 0.8472 - 86ms/epoch - 7ms/step
Epoch 23/25
12/12 - 0s - loss: 0.0016 - accuracy: 1.0000 - val_loss: 0.3609 - val_accuracy: 0.8444 - 84ms/epoch - 7ms/step
Epoch 24/25
12/12 - 0s - loss: 0.0014 - accuracy: 1.0000 - val_loss: 0.3637 - val_accuracy: 0.8472 - 87ms/epoch - 7ms/step
Epoch 25/25
12/12 - 0s - loss: 0.0013 - accuracy: 1.0000 - val_loss: 0.3668 - val_accuracy: 0.8528 - 85ms/epoch - 7ms/step
## Plot Training History
plot1(history1)
## Model Evaluation
model1.evaluate(X_test2, y_test2, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 0.2818 - accuracy: 0.9050 - 32ms/epoch - 16ms/step
[0.28181010484695435, 0.9049999713897705]
Model 2 (Feedforward Neural Network)#
One Embedding Layer + Two fully-connected dense layers
The Inputs are the sequences (integers) of texts.
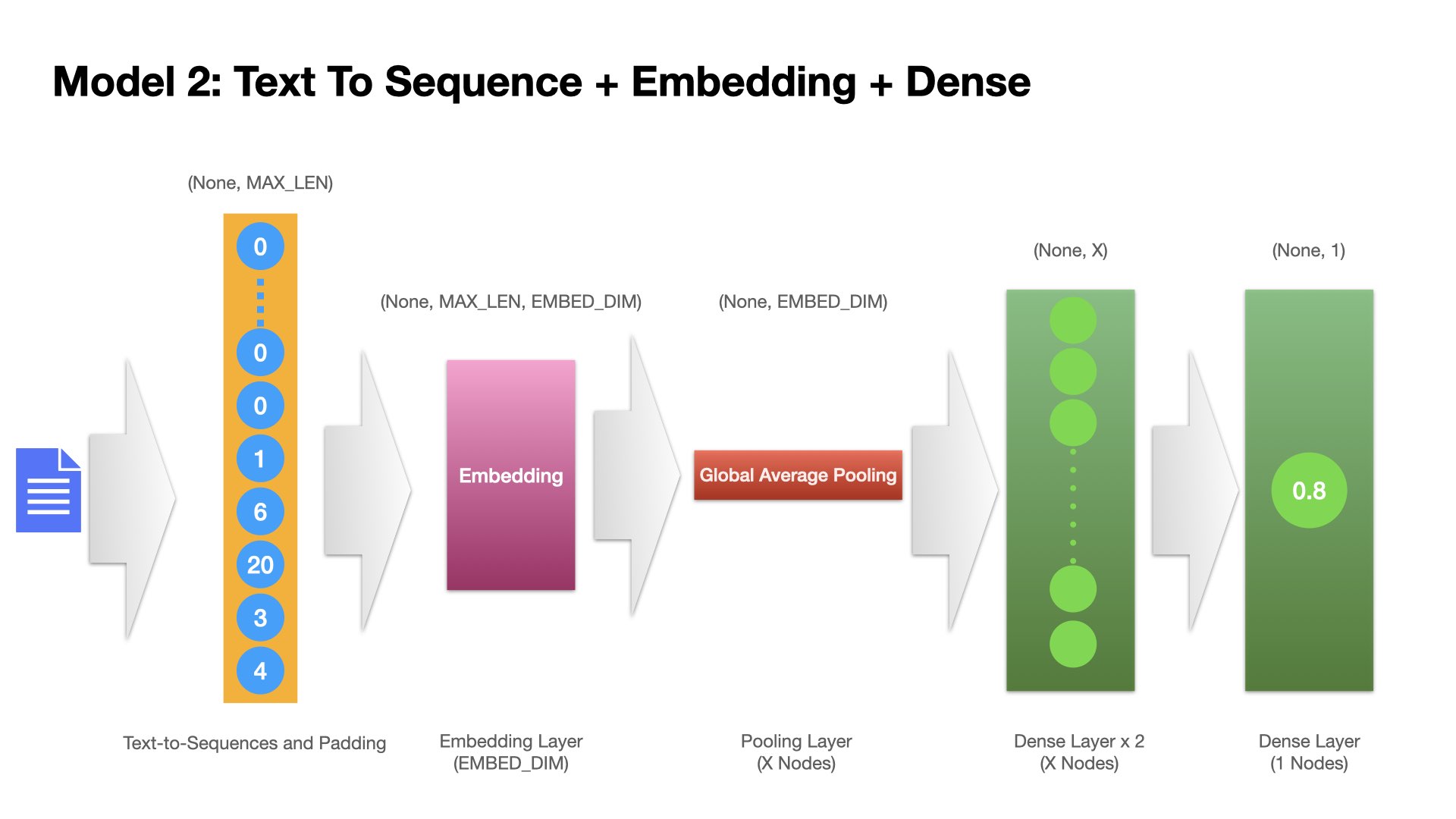
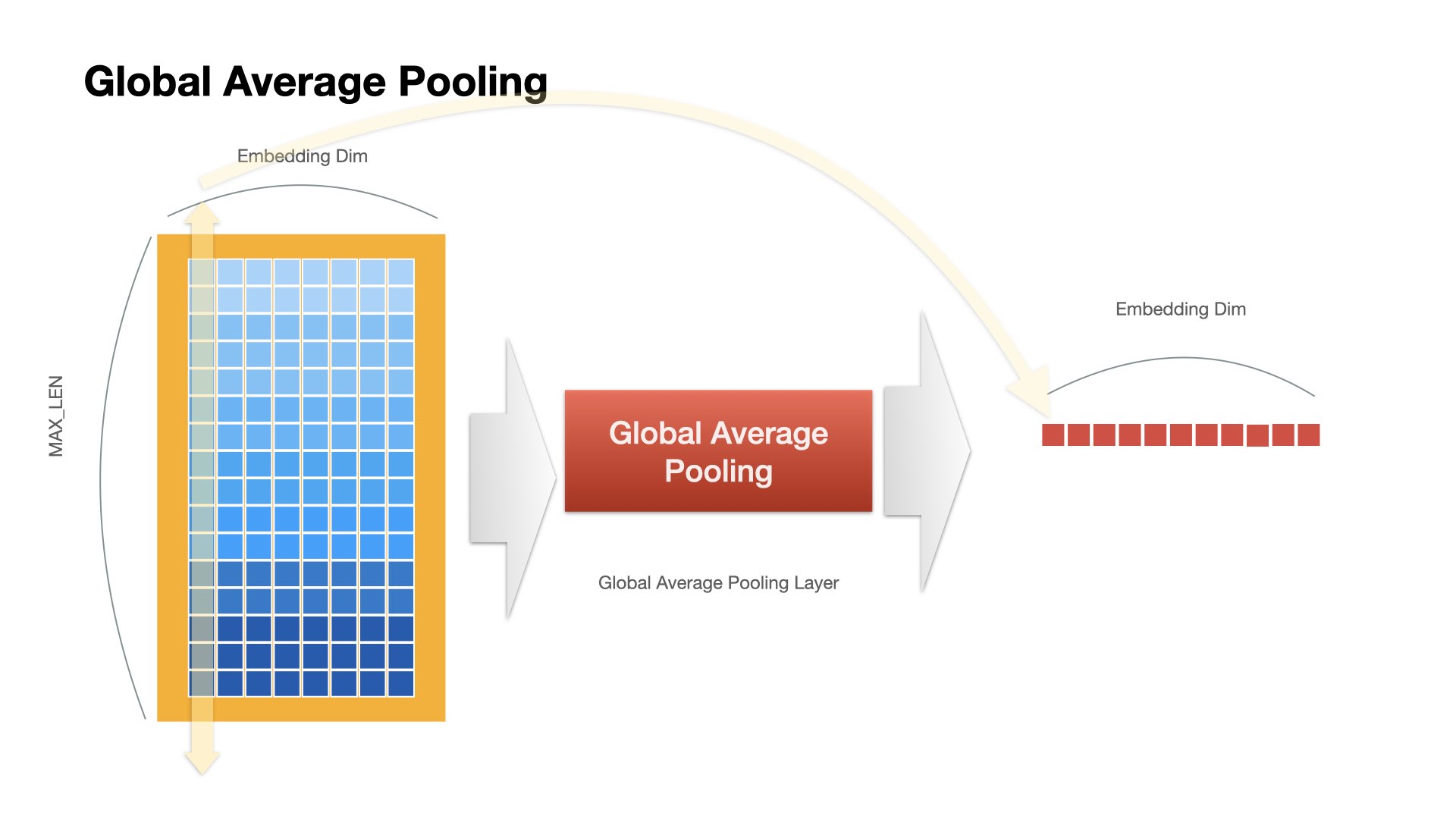
## Model 2
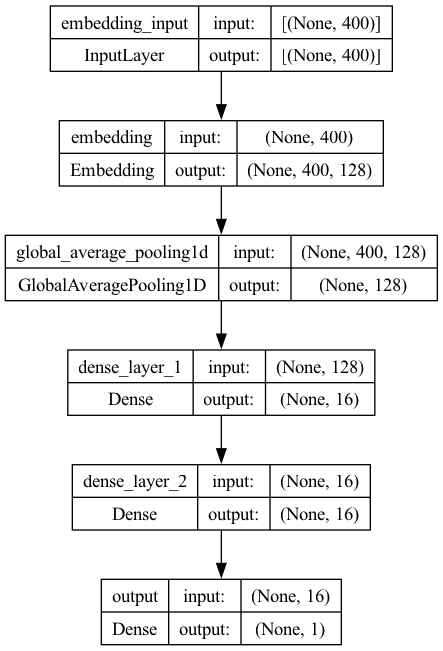
model2 = Sequential()
model2.add(
Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model2.add(
GlobalAveragePooling1D()
) ## The GlobalAveragePooling1D layer returns a fixed-length output vector for each example by averaging over the sequence dimension. This allows the model to handle input of variable length, in the simplest way possible.
model2.add(Dense(16, activation="relu", name="dense_layer_1"))
model2.add(Dense(16, activation="relu", name="dense_layer_2"))
model2.add(Dense(1, activation="sigmoid", name="output"))
model2.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model2, show_shapes=True)
history2 = model2.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
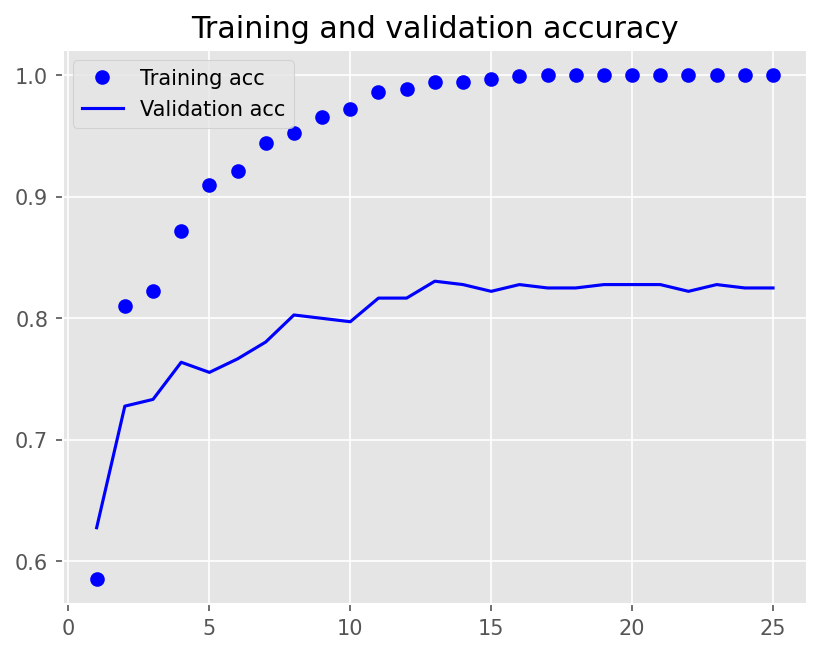
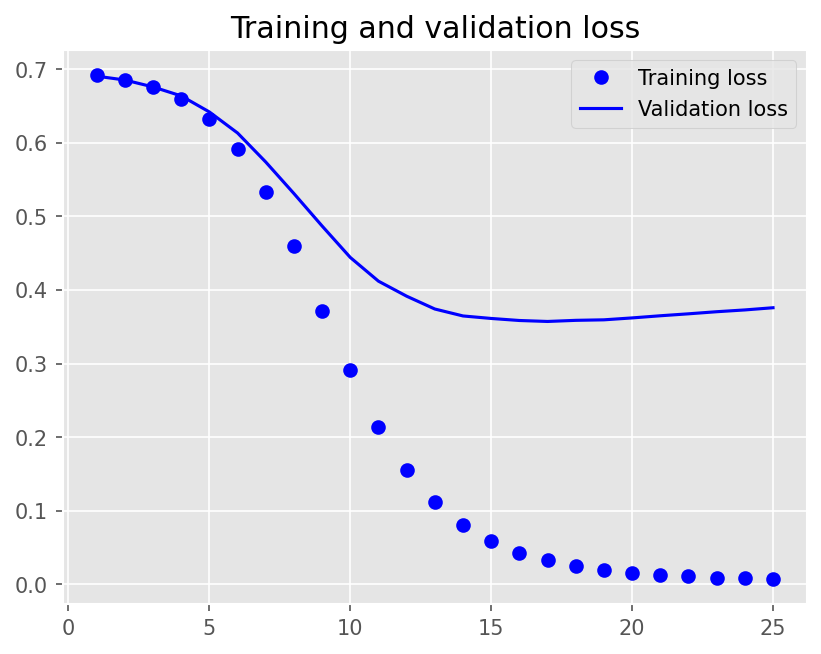
Epoch 1/25
12/12 - 1s - loss: 0.6922 - accuracy: 0.5854 - val_loss: 0.6909 - val_accuracy: 0.6278 - 1s/epoch - 94ms/step
Epoch 2/25
12/12 - 0s - loss: 0.6863 - accuracy: 0.8104 - val_loss: 0.6857 - val_accuracy: 0.7278 - 207ms/epoch - 17ms/step
Epoch 3/25
12/12 - 0s - loss: 0.6764 - accuracy: 0.8222 - val_loss: 0.6762 - val_accuracy: 0.7333 - 197ms/epoch - 16ms/step
Epoch 4/25
12/12 - 0s - loss: 0.6600 - accuracy: 0.8722 - val_loss: 0.6641 - val_accuracy: 0.7639 - 198ms/epoch - 17ms/step
Epoch 5/25
12/12 - 0s - loss: 0.6332 - accuracy: 0.9097 - val_loss: 0.6422 - val_accuracy: 0.7556 - 208ms/epoch - 17ms/step
Epoch 6/25
12/12 - 0s - loss: 0.5925 - accuracy: 0.9215 - val_loss: 0.6136 - val_accuracy: 0.7667 - 196ms/epoch - 16ms/step
Epoch 7/25
12/12 - 0s - loss: 0.5337 - accuracy: 0.9444 - val_loss: 0.5741 - val_accuracy: 0.7806 - 190ms/epoch - 16ms/step
Epoch 8/25
12/12 - 0s - loss: 0.4593 - accuracy: 0.9528 - val_loss: 0.5312 - val_accuracy: 0.8028 - 196ms/epoch - 16ms/step
Epoch 9/25
12/12 - 0s - loss: 0.3713 - accuracy: 0.9653 - val_loss: 0.4871 - val_accuracy: 0.8000 - 183ms/epoch - 15ms/step
Epoch 10/25
12/12 - 0s - loss: 0.2911 - accuracy: 0.9722 - val_loss: 0.4443 - val_accuracy: 0.7972 - 186ms/epoch - 15ms/step
Epoch 11/25
12/12 - 0s - loss: 0.2139 - accuracy: 0.9861 - val_loss: 0.4120 - val_accuracy: 0.8167 - 193ms/epoch - 16ms/step
Epoch 12/25
12/12 - 0s - loss: 0.1545 - accuracy: 0.9889 - val_loss: 0.3916 - val_accuracy: 0.8167 - 192ms/epoch - 16ms/step
Epoch 13/25
12/12 - 0s - loss: 0.1114 - accuracy: 0.9944 - val_loss: 0.3741 - val_accuracy: 0.8306 - 193ms/epoch - 16ms/step
Epoch 14/25
12/12 - 0s - loss: 0.0806 - accuracy: 0.9944 - val_loss: 0.3647 - val_accuracy: 0.8278 - 192ms/epoch - 16ms/step
Epoch 15/25
12/12 - 0s - loss: 0.0583 - accuracy: 0.9972 - val_loss: 0.3613 - val_accuracy: 0.8222 - 189ms/epoch - 16ms/step
Epoch 16/25
12/12 - 0s - loss: 0.0426 - accuracy: 0.9993 - val_loss: 0.3585 - val_accuracy: 0.8278 - 184ms/epoch - 15ms/step
Epoch 17/25
12/12 - 0s - loss: 0.0321 - accuracy: 1.0000 - val_loss: 0.3572 - val_accuracy: 0.8250 - 179ms/epoch - 15ms/step
Epoch 18/25
12/12 - 0s - loss: 0.0245 - accuracy: 1.0000 - val_loss: 0.3587 - val_accuracy: 0.8250 - 188ms/epoch - 16ms/step
Epoch 19/25
12/12 - 0s - loss: 0.0191 - accuracy: 1.0000 - val_loss: 0.3594 - val_accuracy: 0.8278 - 183ms/epoch - 15ms/step
Epoch 20/25
12/12 - 0s - loss: 0.0154 - accuracy: 1.0000 - val_loss: 0.3620 - val_accuracy: 0.8278 - 181ms/epoch - 15ms/step
Epoch 21/25
12/12 - 0s - loss: 0.0126 - accuracy: 1.0000 - val_loss: 0.3650 - val_accuracy: 0.8278 - 189ms/epoch - 16ms/step
Epoch 22/25
12/12 - 0s - loss: 0.0105 - accuracy: 1.0000 - val_loss: 0.3676 - val_accuracy: 0.8222 - 196ms/epoch - 16ms/step
Epoch 23/25
12/12 - 0s - loss: 0.0088 - accuracy: 1.0000 - val_loss: 0.3705 - val_accuracy: 0.8278 - 227ms/epoch - 19ms/step
Epoch 24/25
12/12 - 0s - loss: 0.0076 - accuracy: 1.0000 - val_loss: 0.3729 - val_accuracy: 0.8250 - 193ms/epoch - 16ms/step
Epoch 25/25
12/12 - 0s - loss: 0.0066 - accuracy: 1.0000 - val_loss: 0.3759 - val_accuracy: 0.8250 - 192ms/epoch - 16ms/step
plot1(history2)
model2.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 0.3117 - accuracy: 0.8850 - 31ms/epoch - 16ms/step
[0.311745822429657, 0.8849999904632568]
Note
Issues of Word/Character Representations
Generally speaking, we can train our word embeddings along with the downstream NLP task (e.g., the sentiment classification in our current case).
Another common method is to train the word embeddings using unsupervised methods on a large amount of data and apply the pre-trained word embeddings to the current downstream NLP task. Typical methods include word2vec (CBOW or skipped-gram, GloVe etc). We will come back to these unsupervised methods later.
Model Defintion (Part 2)#
For text sequences, we often apply RNN-based sequence models to create the model.
Model 3 (LSTM)#
One Embedding Layer + LSTM + Dense Layer
Input: the text sequences (padded)
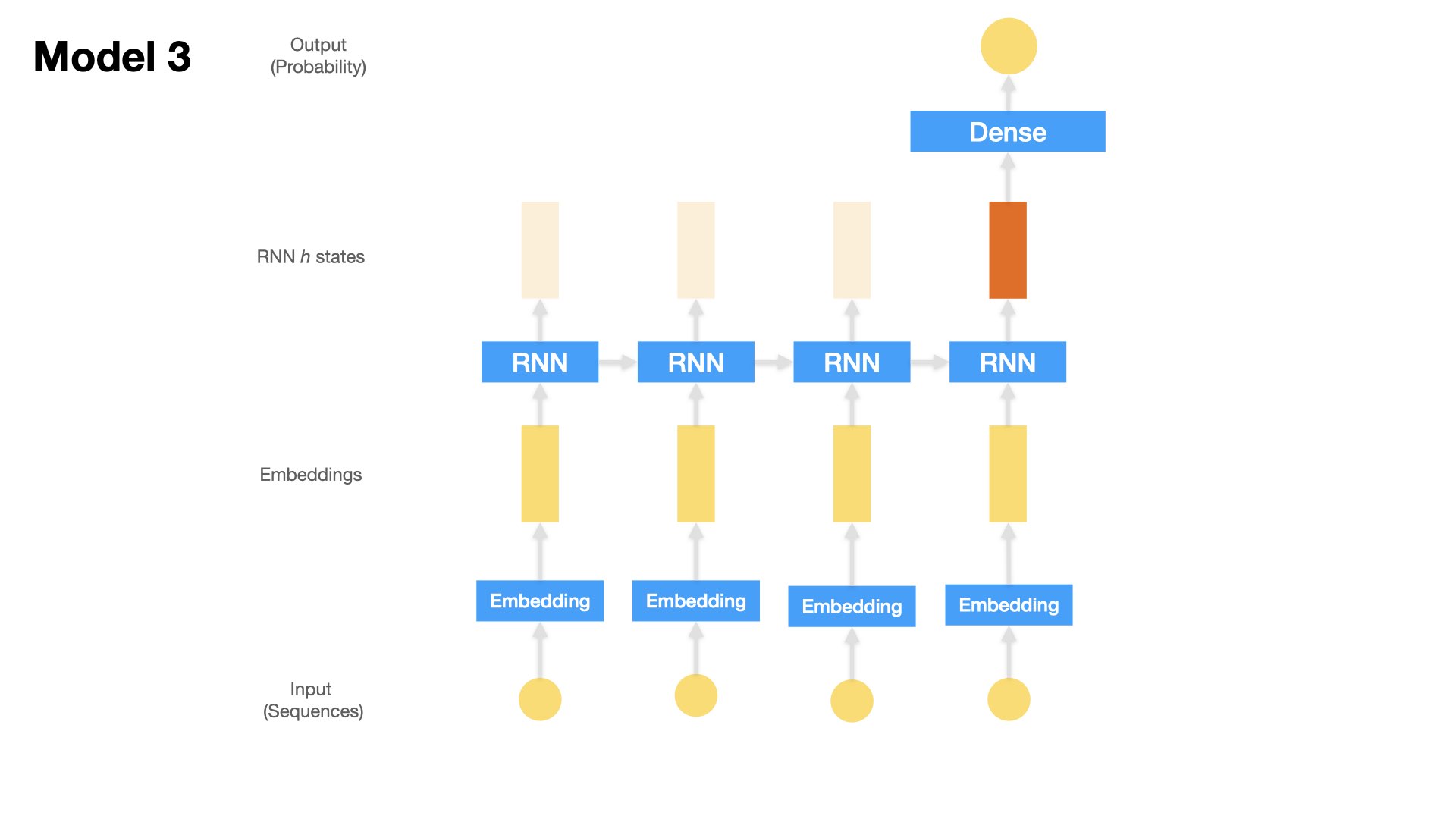
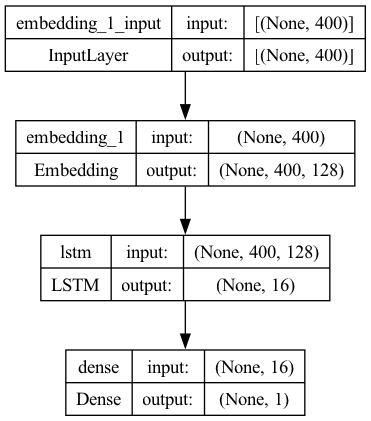
## Model 3
model3 = Sequential()
model3.add(
Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model3.add(LSTM(16, dropout=0.2, recurrent_dropout=0.2))
model3.add(Dense(1, activation="sigmoid"))
model3.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model3, show_shapes=True)
history3 = model3.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/25
12/12 - 8s - loss: 0.6926 - accuracy: 0.5215 - val_loss: 0.6910 - val_accuracy: 0.5250 - 8s/epoch - 673ms/step
Epoch 2/25
12/12 - 4s - loss: 0.6809 - accuracy: 0.7181 - val_loss: 0.6886 - val_accuracy: 0.5500 - 4s/epoch - 351ms/step
Epoch 3/25
12/12 - 4s - loss: 0.6591 - accuracy: 0.7840 - val_loss: 0.6799 - val_accuracy: 0.5694 - 4s/epoch - 347ms/step
Epoch 4/25
12/12 - 4s - loss: 0.6036 - accuracy: 0.8125 - val_loss: 0.6592 - val_accuracy: 0.5861 - 4s/epoch - 342ms/step
Epoch 5/25
12/12 - 4s - loss: 0.4672 - accuracy: 0.8694 - val_loss: 0.5653 - val_accuracy: 0.7194 - 4s/epoch - 345ms/step
Epoch 6/25
12/12 - 4s - loss: 0.3663 - accuracy: 0.9153 - val_loss: 0.5579 - val_accuracy: 0.7361 - 4s/epoch - 342ms/step
Epoch 7/25
12/12 - 4s - loss: 0.3172 - accuracy: 0.9417 - val_loss: 0.6491 - val_accuracy: 0.6889 - 4s/epoch - 344ms/step
Epoch 8/25
12/12 - 4s - loss: 0.2537 - accuracy: 0.9528 - val_loss: 0.5189 - val_accuracy: 0.7639 - 4s/epoch - 340ms/step
Epoch 9/25
12/12 - 4s - loss: 0.1980 - accuracy: 0.9771 - val_loss: 0.5636 - val_accuracy: 0.7500 - 4s/epoch - 351ms/step
Epoch 10/25
12/12 - 4s - loss: 0.1598 - accuracy: 0.9882 - val_loss: 0.5229 - val_accuracy: 0.7667 - 4s/epoch - 344ms/step
Epoch 11/25
12/12 - 4s - loss: 0.1274 - accuracy: 0.9944 - val_loss: 0.5695 - val_accuracy: 0.7500 - 4s/epoch - 347ms/step
Epoch 12/25
12/12 - 4s - loss: 0.1080 - accuracy: 0.9903 - val_loss: 0.5174 - val_accuracy: 0.7833 - 4s/epoch - 342ms/step
Epoch 13/25
12/12 - 4s - loss: 0.0873 - accuracy: 0.9958 - val_loss: 0.5545 - val_accuracy: 0.7778 - 4s/epoch - 347ms/step
Epoch 14/25
12/12 - 4s - loss: 0.1603 - accuracy: 0.9465 - val_loss: 0.5564 - val_accuracy: 0.7806 - 4s/epoch - 343ms/step
Epoch 15/25
12/12 - 4s - loss: 0.1127 - accuracy: 0.9743 - val_loss: 0.5890 - val_accuracy: 0.7250 - 4s/epoch - 348ms/step
Epoch 16/25
12/12 - 4s - loss: 0.0777 - accuracy: 0.9958 - val_loss: 0.5927 - val_accuracy: 0.7500 - 4s/epoch - 339ms/step
Epoch 17/25
12/12 - 4s - loss: 0.0615 - accuracy: 0.9972 - val_loss: 0.5749 - val_accuracy: 0.7778 - 4s/epoch - 344ms/step
Epoch 18/25
12/12 - 4s - loss: 0.0567 - accuracy: 0.9944 - val_loss: 0.5825 - val_accuracy: 0.7722 - 4s/epoch - 345ms/step
Epoch 19/25
12/12 - 4s - loss: 0.0459 - accuracy: 0.9986 - val_loss: 0.5995 - val_accuracy: 0.7667 - 4s/epoch - 340ms/step
Epoch 20/25
12/12 - 4s - loss: 0.0422 - accuracy: 1.0000 - val_loss: 0.6058 - val_accuracy: 0.7611 - 4s/epoch - 356ms/step
Epoch 21/25
12/12 - 4s - loss: 0.0364 - accuracy: 0.9993 - val_loss: 0.6102 - val_accuracy: 0.7722 - 4s/epoch - 343ms/step
Epoch 22/25
12/12 - 4s - loss: 0.0313 - accuracy: 1.0000 - val_loss: 0.6280 - val_accuracy: 0.7722 - 4s/epoch - 341ms/step
Epoch 23/25
12/12 - 4s - loss: 0.0316 - accuracy: 0.9986 - val_loss: 0.6524 - val_accuracy: 0.7694 - 4s/epoch - 342ms/step
Epoch 24/25
12/12 - 4s - loss: 0.0290 - accuracy: 0.9993 - val_loss: 0.6487 - val_accuracy: 0.7722 - 4s/epoch - 339ms/step
Epoch 25/25
12/12 - 4s - loss: 0.0286 - accuracy: 0.9979 - val_loss: 0.6708 - val_accuracy: 0.7667 - 4s/epoch - 344ms/step
plot1(history3)
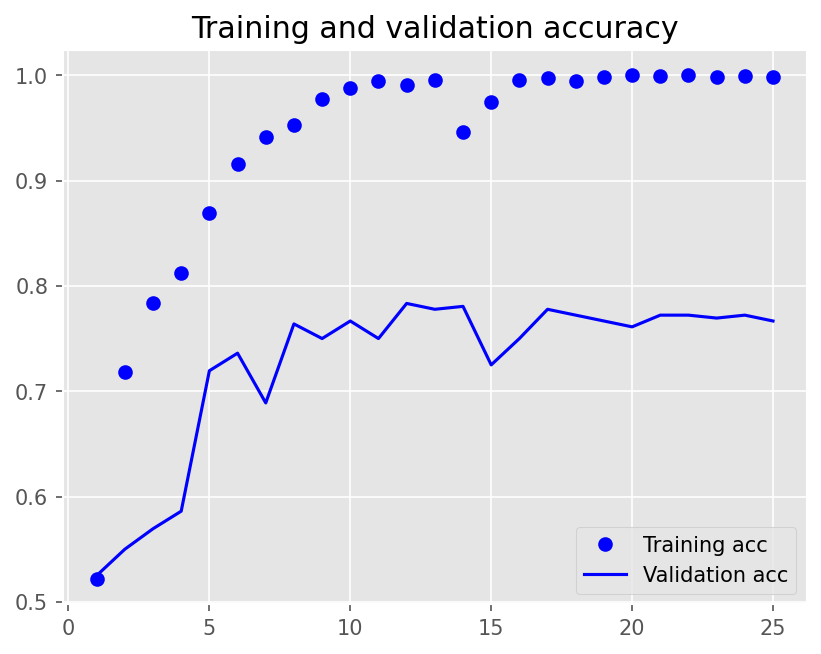
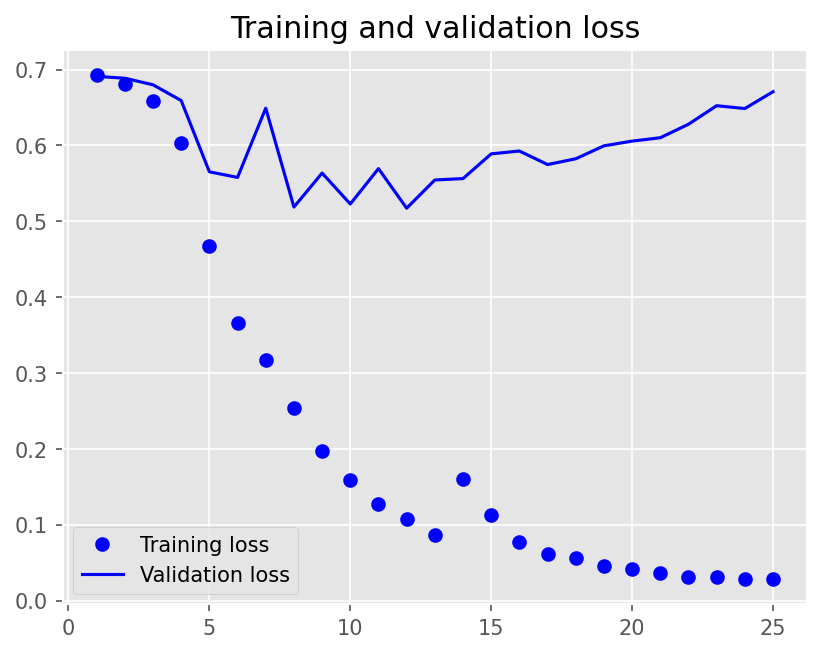
model3.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 0.5916 - accuracy: 0.8250 - 134ms/epoch - 67ms/step
[0.5916371941566467, 0.824999988079071]
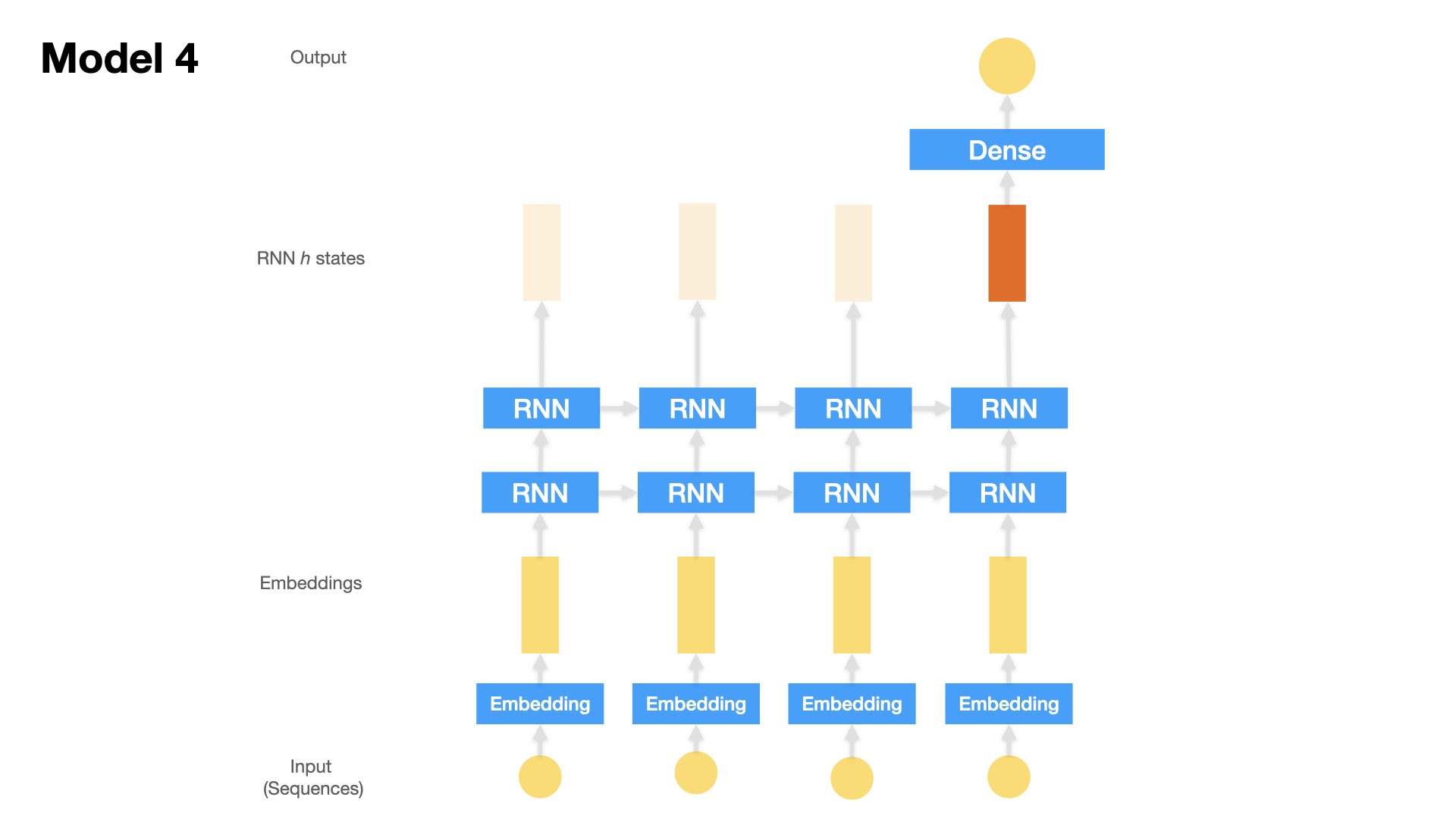
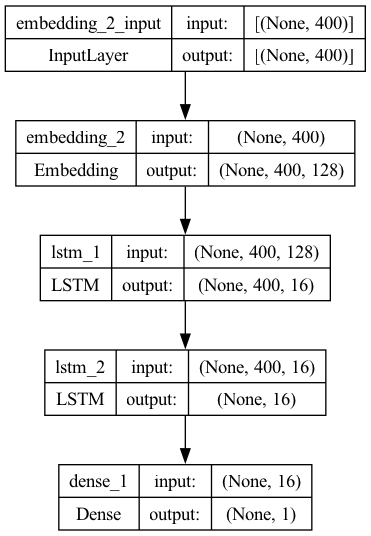
Model 4 (Stacked LSTM)#
One Embedding Layer + Two Stacked LSTM + Dense Layer
Inputs: text sequences (padded)
## Model 4
model4 = Sequential()
model4.add(
Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model4.add(LSTM(16,
return_sequences=True, ## return hidden states of all time steps
dropout=0.2,
recurrent_dropout=0.2))
model4.add(LSTM(16,
dropout=0.2,
recurrent_dropout=0.2))
model4.add(Dense(1, activation="sigmoid"))
model4.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model4, show_shapes=True)
history4 = model4.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=0.2)
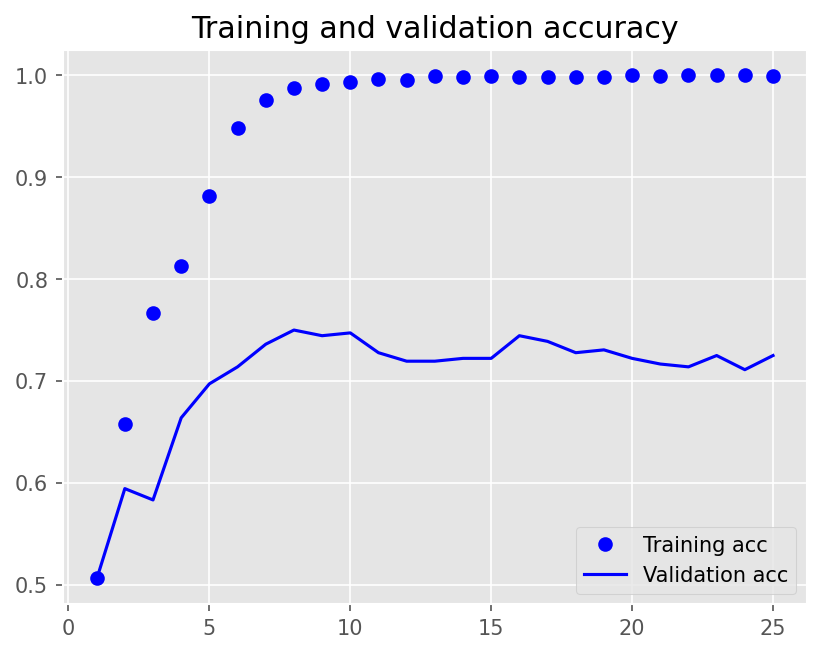
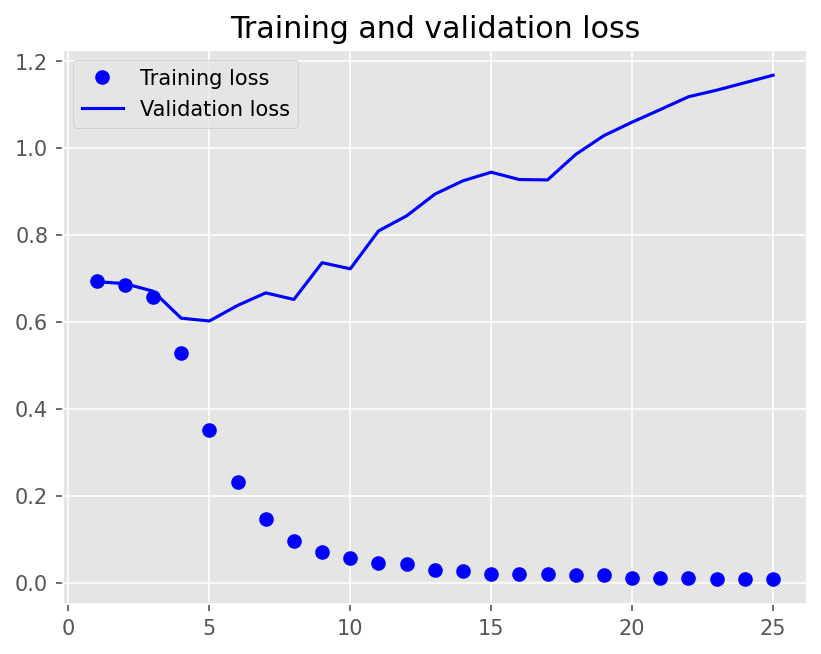
Epoch 1/25
12/12 - 14s - loss: 0.6929 - accuracy: 0.5069 - val_loss: 0.6924 - val_accuracy: 0.5056 - 14s/epoch - 1s/step
Epoch 2/25
12/12 - 8s - loss: 0.6853 - accuracy: 0.6576 - val_loss: 0.6879 - val_accuracy: 0.5944 - 8s/epoch - 654ms/step
Epoch 3/25
12/12 - 8s - loss: 0.6574 - accuracy: 0.7667 - val_loss: 0.6704 - val_accuracy: 0.5833 - 8s/epoch - 675ms/step
Epoch 4/25
12/12 - 8s - loss: 0.5275 - accuracy: 0.8132 - val_loss: 0.6083 - val_accuracy: 0.6639 - 8s/epoch - 677ms/step
Epoch 5/25
12/12 - 8s - loss: 0.3515 - accuracy: 0.8813 - val_loss: 0.6018 - val_accuracy: 0.6972 - 8s/epoch - 666ms/step
Epoch 6/25
12/12 - 8s - loss: 0.2318 - accuracy: 0.9479 - val_loss: 0.6376 - val_accuracy: 0.7139 - 8s/epoch - 662ms/step
Epoch 7/25
12/12 - 8s - loss: 0.1455 - accuracy: 0.9757 - val_loss: 0.6665 - val_accuracy: 0.7361 - 8s/epoch - 660ms/step
Epoch 8/25
12/12 - 8s - loss: 0.0961 - accuracy: 0.9875 - val_loss: 0.6514 - val_accuracy: 0.7500 - 8s/epoch - 661ms/step
Epoch 9/25
12/12 - 8s - loss: 0.0708 - accuracy: 0.9917 - val_loss: 0.7360 - val_accuracy: 0.7444 - 8s/epoch - 668ms/step
Epoch 10/25
12/12 - 8s - loss: 0.0571 - accuracy: 0.9937 - val_loss: 0.7219 - val_accuracy: 0.7472 - 8s/epoch - 665ms/step
Epoch 11/25
12/12 - 8s - loss: 0.0445 - accuracy: 0.9965 - val_loss: 0.8090 - val_accuracy: 0.7278 - 8s/epoch - 659ms/step
Epoch 12/25
12/12 - 8s - loss: 0.0420 - accuracy: 0.9951 - val_loss: 0.8438 - val_accuracy: 0.7194 - 8s/epoch - 655ms/step
Epoch 13/25
12/12 - 8s - loss: 0.0283 - accuracy: 0.9993 - val_loss: 0.8936 - val_accuracy: 0.7194 - 8s/epoch - 668ms/step
Epoch 14/25
12/12 - 8s - loss: 0.0264 - accuracy: 0.9986 - val_loss: 0.9245 - val_accuracy: 0.7222 - 8s/epoch - 660ms/step
Epoch 15/25
12/12 - 8s - loss: 0.0201 - accuracy: 0.9993 - val_loss: 0.9442 - val_accuracy: 0.7222 - 8s/epoch - 658ms/step
Epoch 16/25
12/12 - 8s - loss: 0.0199 - accuracy: 0.9986 - val_loss: 0.9273 - val_accuracy: 0.7444 - 8s/epoch - 671ms/step
Epoch 17/25
12/12 - 8s - loss: 0.0199 - accuracy: 0.9979 - val_loss: 0.9265 - val_accuracy: 0.7389 - 8s/epoch - 651ms/step
Epoch 18/25
12/12 - 8s - loss: 0.0175 - accuracy: 0.9986 - val_loss: 0.9852 - val_accuracy: 0.7278 - 8s/epoch - 661ms/step
Epoch 19/25
12/12 - 8s - loss: 0.0168 - accuracy: 0.9986 - val_loss: 1.0284 - val_accuracy: 0.7306 - 8s/epoch - 661ms/step
Epoch 20/25
12/12 - 8s - loss: 0.0110 - accuracy: 1.0000 - val_loss: 1.0594 - val_accuracy: 0.7222 - 8s/epoch - 665ms/step
Epoch 21/25
12/12 - 8s - loss: 0.0106 - accuracy: 0.9993 - val_loss: 1.0883 - val_accuracy: 0.7167 - 8s/epoch - 667ms/step
Epoch 22/25
12/12 - 8s - loss: 0.0094 - accuracy: 1.0000 - val_loss: 1.1179 - val_accuracy: 0.7139 - 8s/epoch - 674ms/step
Epoch 23/25
12/12 - 8s - loss: 0.0085 - accuracy: 1.0000 - val_loss: 1.1330 - val_accuracy: 0.7250 - 8s/epoch - 663ms/step
Epoch 24/25
12/12 - 8s - loss: 0.0077 - accuracy: 1.0000 - val_loss: 1.1501 - val_accuracy: 0.7111 - 8s/epoch - 678ms/step
Epoch 25/25
12/12 - 8s - loss: 0.0090 - accuracy: 0.9993 - val_loss: 1.1674 - val_accuracy: 0.7250 - 8s/epoch - 664ms/step
plot1(history4)
model4.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 1.2005 - accuracy: 0.6900 - 213ms/epoch - 107ms/step
[1.2005281448364258, 0.6899999976158142]
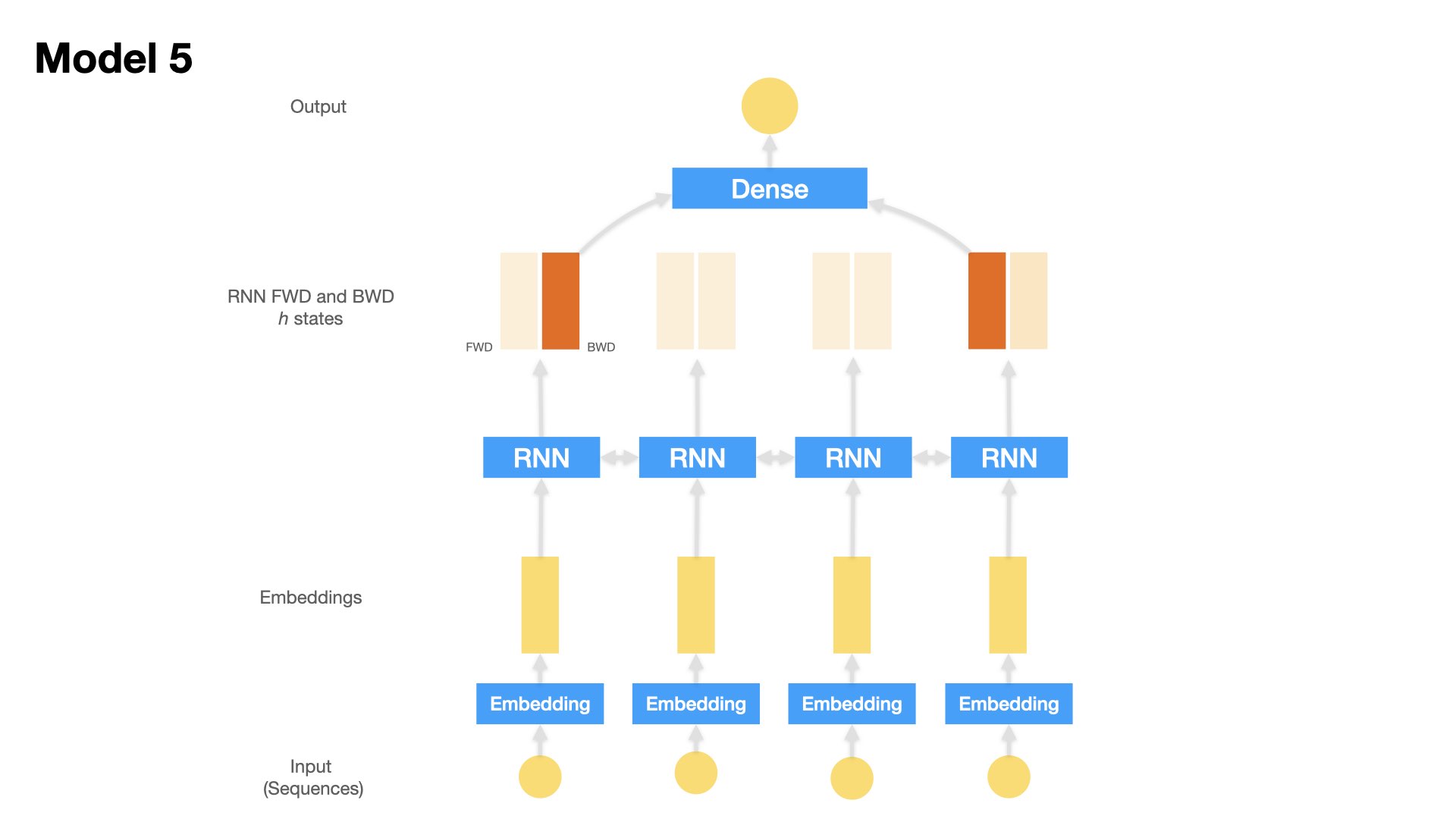
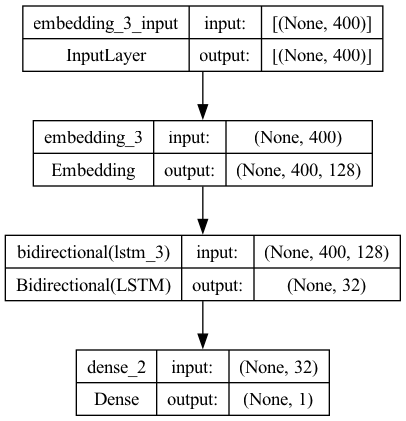
Model 5 (Bidirectional LSTM)#
Embedding Layer + Bidirectional LSTM + Dense Layer
Inputs: Text sequences (padded)
## Model 5
model5 = Sequential()
model5.add(
Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model5.add(Bidirectional(LSTM(16, dropout=0.2, recurrent_dropout=0.2)))
model5.add(Dense(1, activation="sigmoid"))
model5.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model5, show_shapes=True)
history5 = model5.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=0.2)
Epoch 1/25
12/12 - 12s - loss: 0.6924 - accuracy: 0.5035 - val_loss: 0.6929 - val_accuracy: 0.4750 - 12s/epoch - 981ms/step
Epoch 2/25
12/12 - 5s - loss: 0.6743 - accuracy: 0.6750 - val_loss: 0.6883 - val_accuracy: 0.5250 - 5s/epoch - 417ms/step
Epoch 3/25
12/12 - 5s - loss: 0.6367 - accuracy: 0.7646 - val_loss: 0.6737 - val_accuracy: 0.5556 - 5s/epoch - 411ms/step
Epoch 4/25
12/12 - 5s - loss: 0.5168 - accuracy: 0.8576 - val_loss: 0.6888 - val_accuracy: 0.6278 - 5s/epoch - 411ms/step
Epoch 5/25
12/12 - 5s - loss: 0.4034 - accuracy: 0.8562 - val_loss: 0.7105 - val_accuracy: 0.6111 - 5s/epoch - 416ms/step
Epoch 6/25
12/12 - 5s - loss: 0.2688 - accuracy: 0.9417 - val_loss: 0.5671 - val_accuracy: 0.6889 - 5s/epoch - 415ms/step
Epoch 7/25
12/12 - 5s - loss: 0.1561 - accuracy: 0.9806 - val_loss: 0.5828 - val_accuracy: 0.6806 - 5s/epoch - 411ms/step
Epoch 8/25
12/12 - 5s - loss: 0.0936 - accuracy: 0.9917 - val_loss: 0.5925 - val_accuracy: 0.7167 - 5s/epoch - 393ms/step
Epoch 9/25
12/12 - 5s - loss: 0.0599 - accuracy: 0.9972 - val_loss: 0.6207 - val_accuracy: 0.7167 - 5s/epoch - 407ms/step
Epoch 10/25
12/12 - 5s - loss: 0.0432 - accuracy: 0.9986 - val_loss: 0.6404 - val_accuracy: 0.6667 - 5s/epoch - 424ms/step
Epoch 11/25
12/12 - 5s - loss: 0.0321 - accuracy: 0.9986 - val_loss: 0.7508 - val_accuracy: 0.6528 - 5s/epoch - 417ms/step
Epoch 12/25
12/12 - 5s - loss: 0.0226 - accuracy: 1.0000 - val_loss: 0.7272 - val_accuracy: 0.6861 - 5s/epoch - 417ms/step
Epoch 13/25
12/12 - 5s - loss: 0.0181 - accuracy: 0.9993 - val_loss: 0.6988 - val_accuracy: 0.6861 - 5s/epoch - 410ms/step
Epoch 14/25
12/12 - 5s - loss: 0.0156 - accuracy: 1.0000 - val_loss: 0.8357 - val_accuracy: 0.6500 - 5s/epoch - 431ms/step
Epoch 15/25
12/12 - 5s - loss: 0.0127 - accuracy: 1.0000 - val_loss: 0.8104 - val_accuracy: 0.6861 - 5s/epoch - 413ms/step
Epoch 16/25
12/12 - 5s - loss: 0.0131 - accuracy: 0.9993 - val_loss: 0.7795 - val_accuracy: 0.6917 - 5s/epoch - 407ms/step
Epoch 17/25
12/12 - 5s - loss: 0.0119 - accuracy: 1.0000 - val_loss: 0.8514 - val_accuracy: 0.6444 - 5s/epoch - 411ms/step
Epoch 18/25
12/12 - 5s - loss: 0.0099 - accuracy: 1.0000 - val_loss: 0.7334 - val_accuracy: 0.7000 - 5s/epoch - 407ms/step
Epoch 19/25
12/12 - 5s - loss: 0.0088 - accuracy: 1.0000 - val_loss: 0.9122 - val_accuracy: 0.6556 - 5s/epoch - 413ms/step
Epoch 20/25
12/12 - 5s - loss: 0.0076 - accuracy: 1.0000 - val_loss: 0.8953 - val_accuracy: 0.6472 - 5s/epoch - 411ms/step
Epoch 21/25
12/12 - 5s - loss: 0.0069 - accuracy: 1.0000 - val_loss: 0.8807 - val_accuracy: 0.6639 - 5s/epoch - 406ms/step
Epoch 22/25
12/12 - 5s - loss: 0.0067 - accuracy: 1.0000 - val_loss: 0.8413 - val_accuracy: 0.6778 - 5s/epoch - 410ms/step
Epoch 23/25
12/12 - 5s - loss: 0.0060 - accuracy: 1.0000 - val_loss: 0.9627 - val_accuracy: 0.6556 - 5s/epoch - 412ms/step
Epoch 24/25
12/12 - 5s - loss: 0.0051 - accuracy: 1.0000 - val_loss: 0.9409 - val_accuracy: 0.6667 - 5s/epoch - 399ms/step
Epoch 25/25
12/12 - 5s - loss: 0.0050 - accuracy: 1.0000 - val_loss: 0.9556 - val_accuracy: 0.6750 - 5s/epoch - 404ms/step
plot1(history5)
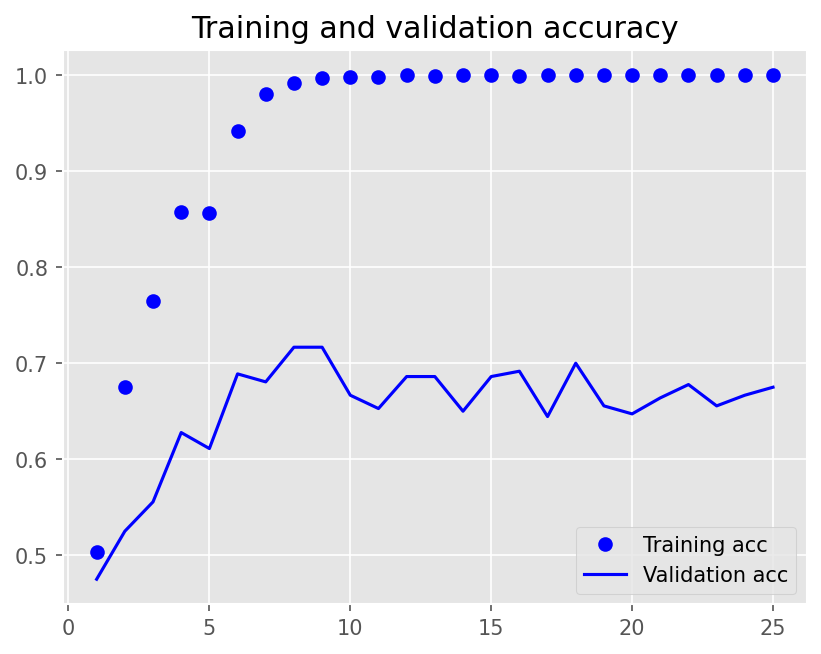
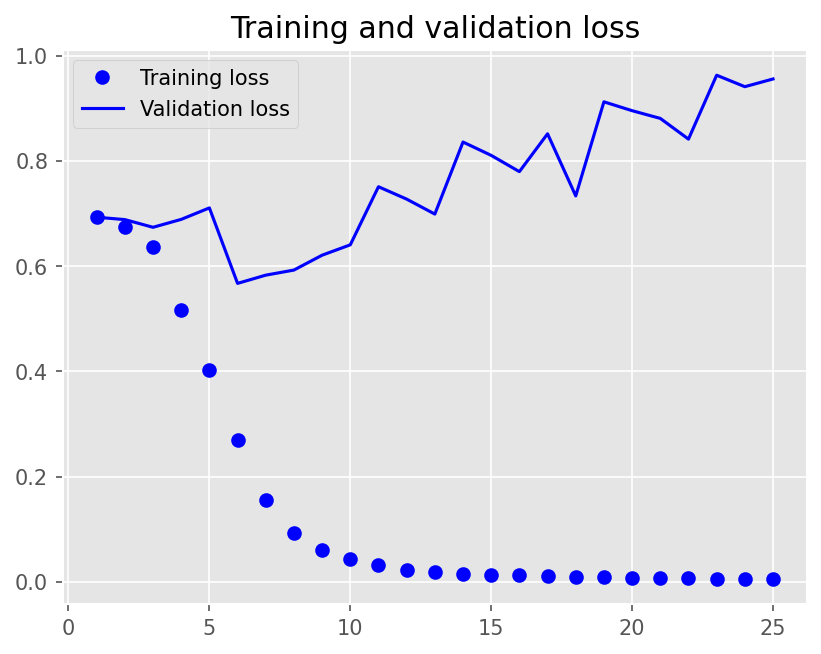
model5.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 0.6740 - accuracy: 0.7550 - 144ms/epoch - 72ms/step
[0.6739590167999268, 0.7549999952316284]
Model Definition (Part 3)#
Sequence models can be further enriched by:
considering all the hidden states at all timesteps;
introducing the mechansim of attention.
We can make the LSTM models more powerful in at least three more ways:
Add another Dense layer to the output of LSTM: This additional dense layer can help further refine and transform the information learned by the LSTM hidden states before making final predictions.
Considering all hidden states at all timesteps: In a standard LSTM model, only the final hidden state is typically used for making predictions. However, by considering all the hidden states at each timestep, the model can capture more detailed information from the input sequence. This allows the model to better understand the temporal dynamics of the sequence and make more accurate predictions.
Introducing the mechanism of attention: Attention mechanisms allow the model to selectively focus on different parts of the input sequence when making predictions. Instead of treating all parts of the sequence equally, attention mechanisms assign different weights to each timestep’s hidden state based on its relevance to the current prediction task. This allows the model to prioritize important information and ignore irrelevant or less informative parts of the sequence, leading to improved performance on tasks such as machine translation, text summarization, and sentiment analysis.
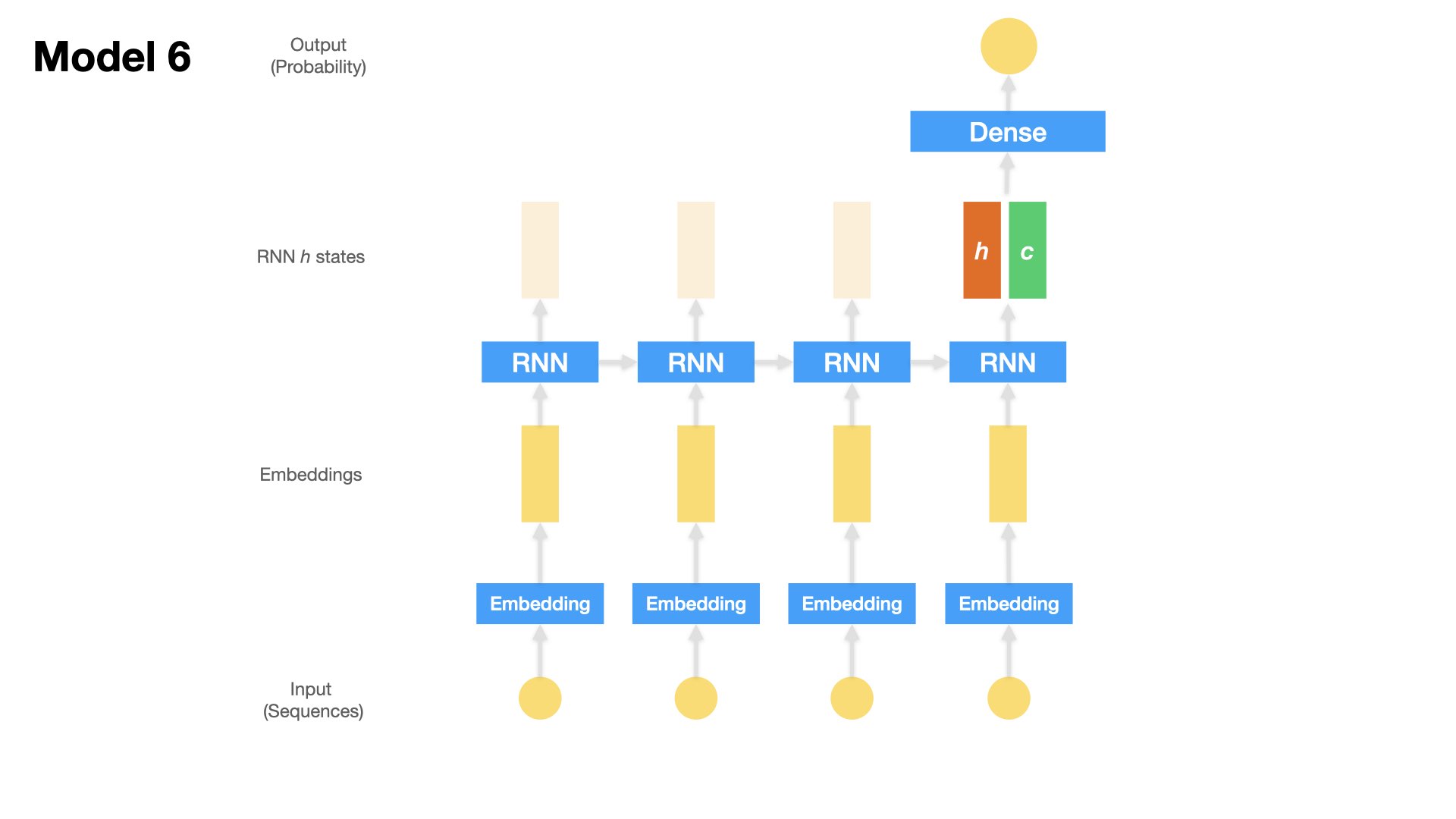
Model 6 (LSTM + Dense)#
One Embedding Layer + LSTM [hidden state of last time step + cell state of last time step] + Dense Layer
Inputs: Text sequences (padded)
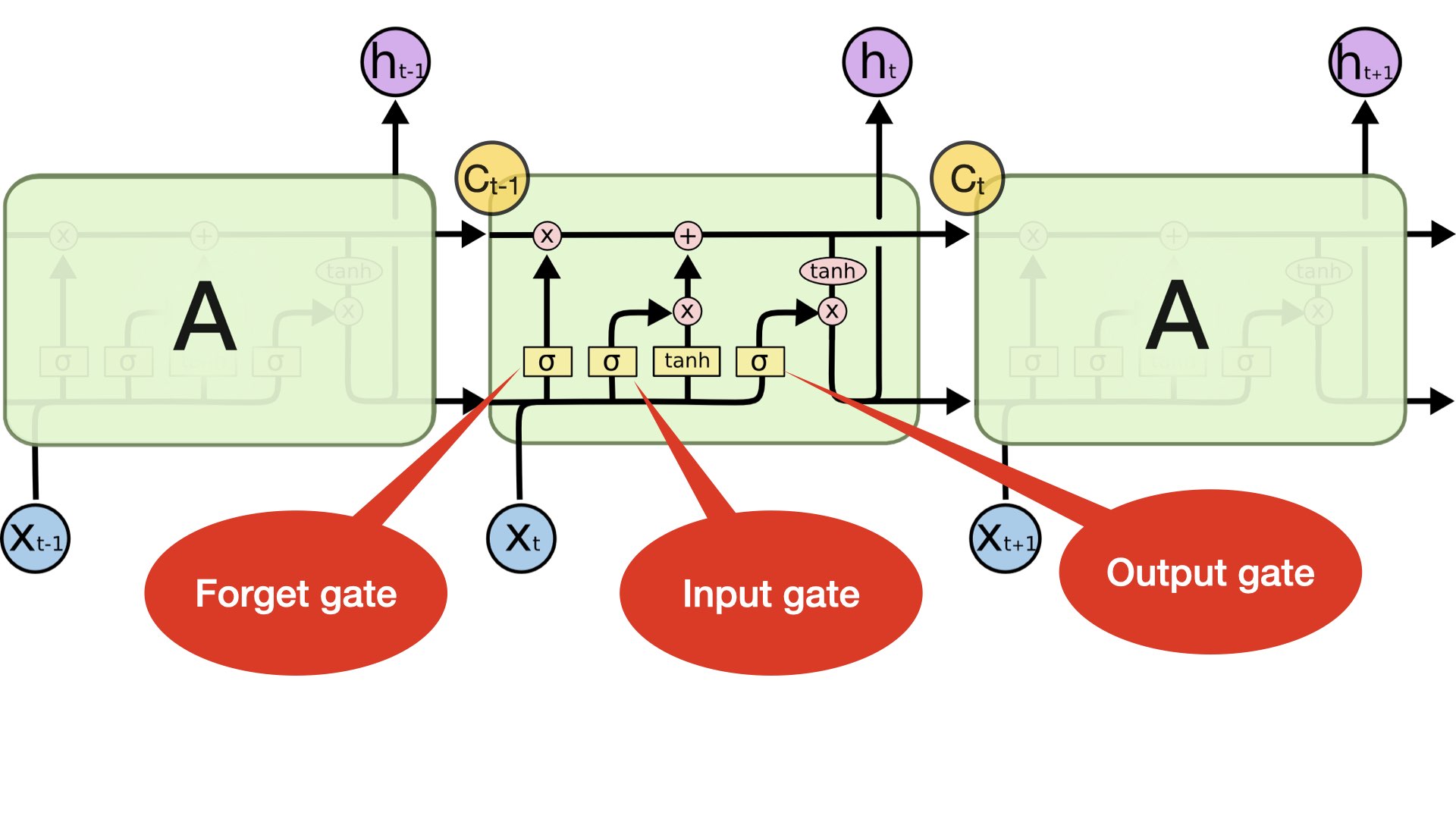 (Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
(Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
## Model 6
## Functional API
inputs = Input(shape=(max_len, ))
x = Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True)(inputs)
_, x_last_h, x_c = LSTM(16,
dropout=0.2,
recurrent_dropout=0.2,
return_sequences=False,
return_state=True)(x)
## LSTM Parameters:
# `return_seqeunces=True`: return the hidden states for each time step
# `return_state=True`: return the cell state of the last time step
# When both are set True, the return values of LSTM are:
# (1) the hidden states of all time steps (when `return_sequences=True`) or the hidden state of the last time step
# (2) the hidden state of the last time step
# (3) the cell state of the last time step
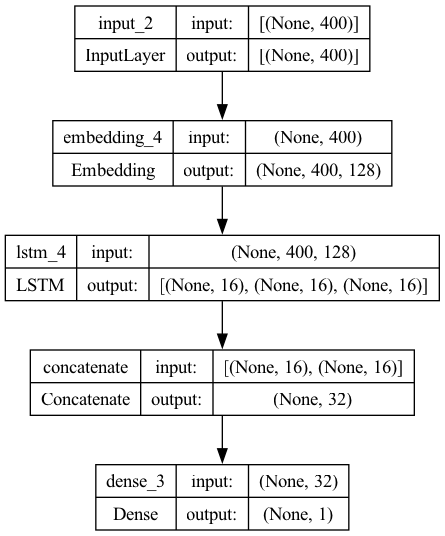
x = Concatenate(axis=1)([x_last_h, x_c])
outputs = Dense(1, activation='sigmoid')(x)
model6 = Model(inputs=inputs, outputs=outputs)
plot_model(model6, show_shapes=True)
model6.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
history6 = model6.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/25
12/12 - 8s - loss: 0.6921 - accuracy: 0.5326 - val_loss: 0.6908 - val_accuracy: 0.5472 - 8s/epoch - 634ms/step
Epoch 2/25
12/12 - 4s - loss: 0.6724 - accuracy: 0.7069 - val_loss: 0.6851 - val_accuracy: 0.5667 - 4s/epoch - 347ms/step
Epoch 3/25
12/12 - 4s - loss: 0.6268 - accuracy: 0.7750 - val_loss: 0.6640 - val_accuracy: 0.5778 - 4s/epoch - 354ms/step
Epoch 4/25
12/12 - 4s - loss: 0.4815 - accuracy: 0.8431 - val_loss: 0.5603 - val_accuracy: 0.7306 - 4s/epoch - 346ms/step
Epoch 5/25
12/12 - 4s - loss: 0.3212 - accuracy: 0.9097 - val_loss: 0.5372 - val_accuracy: 0.7611 - 4s/epoch - 344ms/step
Epoch 6/25
12/12 - 4s - loss: 0.2178 - accuracy: 0.9479 - val_loss: 0.5404 - val_accuracy: 0.7361 - 4s/epoch - 350ms/step
Epoch 7/25
12/12 - 4s - loss: 0.1449 - accuracy: 0.9792 - val_loss: 0.6886 - val_accuracy: 0.7444 - 4s/epoch - 356ms/step
Epoch 8/25
12/12 - 4s - loss: 0.0935 - accuracy: 0.9826 - val_loss: 0.7515 - val_accuracy: 0.7472 - 4s/epoch - 355ms/step
Epoch 9/25
12/12 - 4s - loss: 0.0626 - accuracy: 0.9910 - val_loss: 0.6428 - val_accuracy: 0.7694 - 4s/epoch - 352ms/step
Epoch 10/25
12/12 - 4s - loss: 0.0371 - accuracy: 0.9972 - val_loss: 0.6734 - val_accuracy: 0.7750 - 4s/epoch - 338ms/step
Epoch 11/25
12/12 - 4s - loss: 0.0325 - accuracy: 0.9937 - val_loss: 0.7257 - val_accuracy: 0.7611 - 4s/epoch - 340ms/step
Epoch 12/25
12/12 - 4s - loss: 0.0228 - accuracy: 0.9986 - val_loss: 0.7625 - val_accuracy: 0.7444 - 4s/epoch - 341ms/step
Epoch 13/25
12/12 - 4s - loss: 0.0193 - accuracy: 0.9979 - val_loss: 0.7921 - val_accuracy: 0.7556 - 4s/epoch - 342ms/step
Epoch 14/25
12/12 - 4s - loss: 0.0176 - accuracy: 0.9972 - val_loss: 0.8257 - val_accuracy: 0.7444 - 4s/epoch - 344ms/step
Epoch 15/25
12/12 - 4s - loss: 0.0168 - accuracy: 0.9965 - val_loss: 0.7569 - val_accuracy: 0.7361 - 4s/epoch - 347ms/step
Epoch 16/25
12/12 - 4s - loss: 0.0146 - accuracy: 0.9986 - val_loss: 0.8063 - val_accuracy: 0.7556 - 4s/epoch - 350ms/step
Epoch 17/25
12/12 - 4s - loss: 0.0782 - accuracy: 0.9743 - val_loss: 0.9868 - val_accuracy: 0.6583 - 4s/epoch - 349ms/step
Epoch 18/25
12/12 - 4s - loss: 0.0572 - accuracy: 0.9847 - val_loss: 0.8597 - val_accuracy: 0.6972 - 4s/epoch - 347ms/step
Epoch 19/25
12/12 - 4s - loss: 0.0375 - accuracy: 0.9910 - val_loss: 0.9109 - val_accuracy: 0.7056 - 4s/epoch - 344ms/step
Epoch 20/25
12/12 - 4s - loss: 0.0159 - accuracy: 0.9965 - val_loss: 0.9361 - val_accuracy: 0.7306 - 4s/epoch - 344ms/step
Epoch 21/25
12/12 - 4s - loss: 0.0082 - accuracy: 0.9993 - val_loss: 0.9406 - val_accuracy: 0.7250 - 4s/epoch - 341ms/step
Epoch 22/25
12/12 - 4s - loss: 0.0076 - accuracy: 1.0000 - val_loss: 0.9547 - val_accuracy: 0.7250 - 4s/epoch - 350ms/step
Epoch 23/25
12/12 - 4s - loss: 0.0048 - accuracy: 1.0000 - val_loss: 0.9604 - val_accuracy: 0.7389 - 4s/epoch - 342ms/step
Epoch 24/25
12/12 - 4s - loss: 0.0037 - accuracy: 1.0000 - val_loss: 0.9990 - val_accuracy: 0.7306 - 4s/epoch - 344ms/step
Epoch 25/25
12/12 - 4s - loss: 0.0029 - accuracy: 1.0000 - val_loss: 1.0288 - val_accuracy: 0.7333 - 4s/epoch - 349ms/step
plot1(history6)
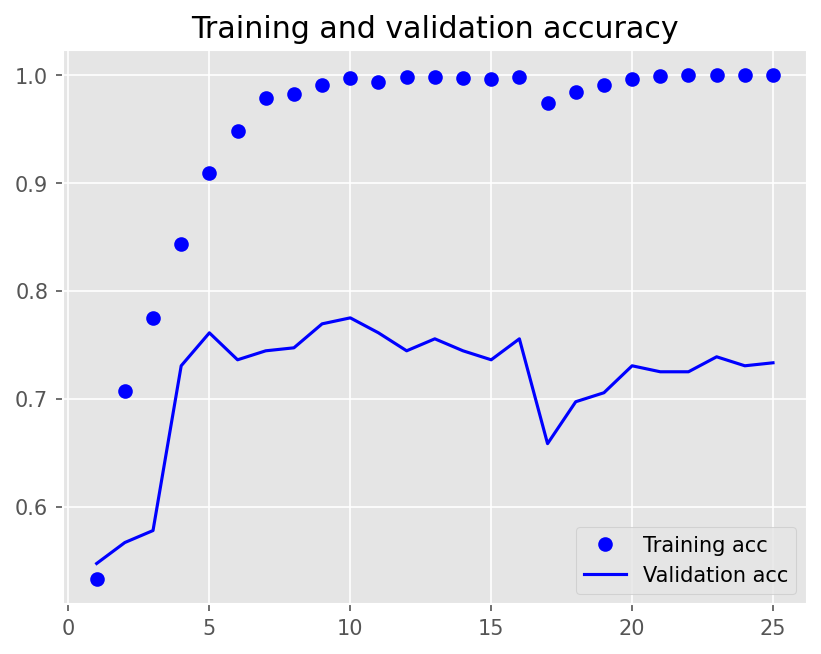
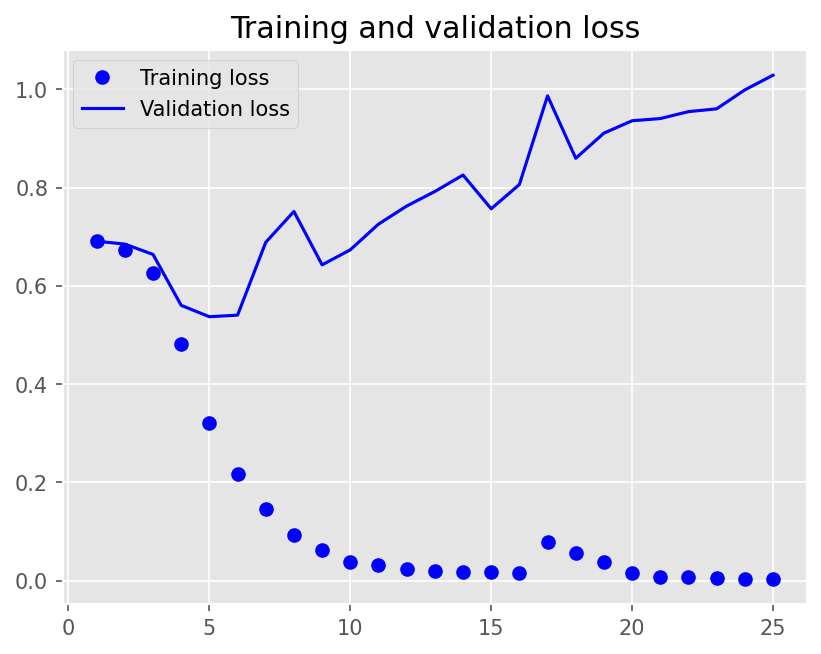
model6.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 1.0688 - accuracy: 0.7300 - 141ms/epoch - 71ms/step
[1.068809151649475, 0.7300000190734863]
Model 7 (LSTM + Attention)#
Embedding + LSTM + Self-Attention + Dense
Inputs: Text sequences
All of the previous RNN-based models only utilize the output of the last time step from the RNN as the input of the decision-making Dense layer.
We can also make all the hidden outputs at all time steps from the RNN available to decision-making Dense layer.
This is the idea of Attention.
Note
In the context of LSTM (Long Short-Term Memory) networks, the attention mechanism is a method used to enhance the model’s ability to focus on specific parts of the input sequence when making predictions.
Instead of processing the entire input sequence uniformly, the attention mechanism assigns different weights to different parts of the sequence, allowing the model to pay more attention to relevant information and ignore irrelevant or less important information.
This is particularly useful in tasks where certain parts of the input sequence are more relevant to the prediction than others, such as machine translation or text summarization.
By incorporating attention mechanisms into LSTM networks, the model can better capture long-range dependencies and improve its performance on sequence-related tasks.
Here we add one
Self-Attentionlayer, which gives us a weighted version of all the hidden states from the RNN.Self Attention layer is a simple sequence-to-sequence layer, which takes in a set of input tensors and returns a set of output tensors.
In Self Attention Layer, each output vector is transformed by considering the pairwise similarities of its corresponding input vector and all the other input vectors.
We will come back to the Attention mechanism in the later unit for more details.
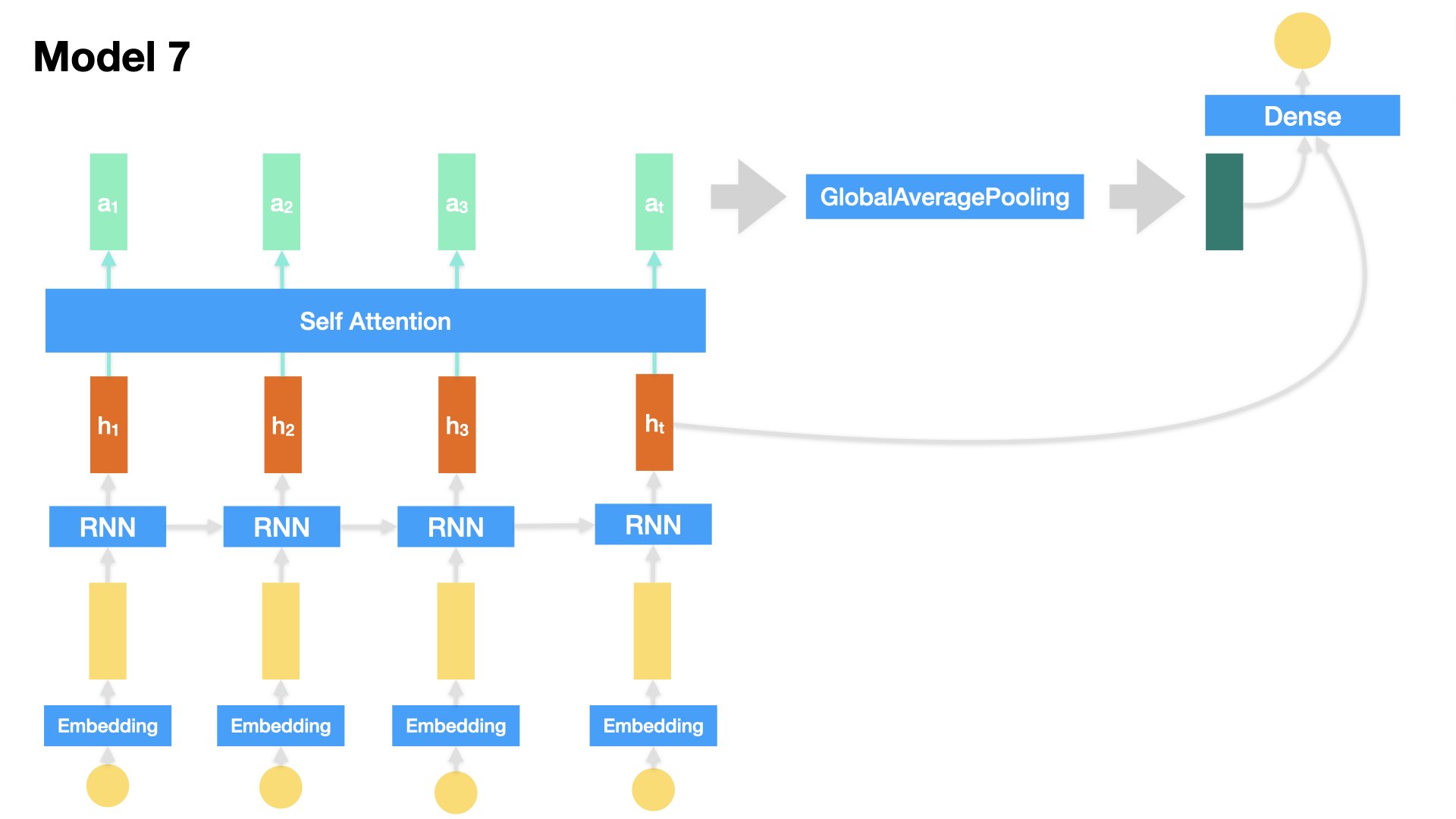
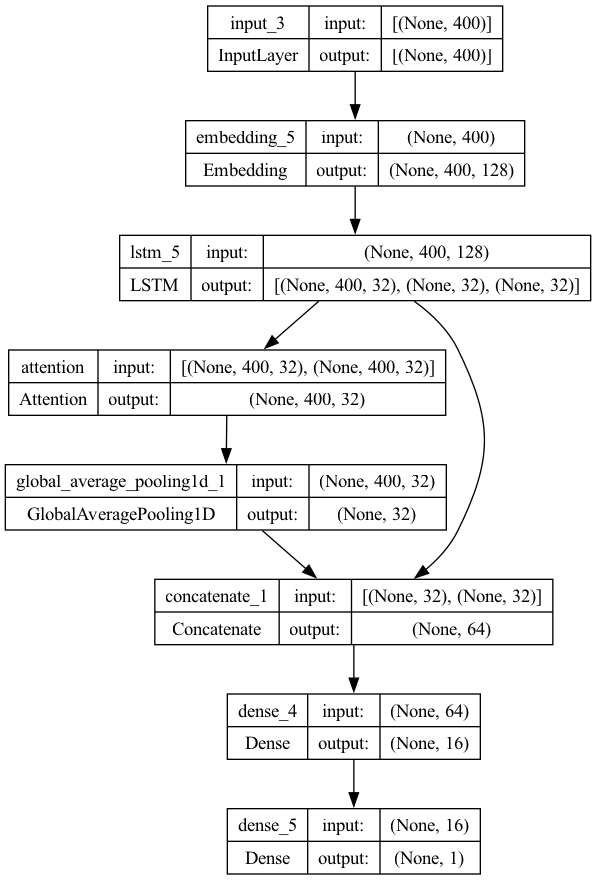
## Model 7 (Self-Attention)
inputs = Input(shape=(max_len, ))
x = Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True)(inputs)
x_all_hs, x_last_h, x_last_c = LSTM(32,
dropout=0.2,
recurrent_dropout=0.2,
return_sequences=True,
return_state=True)(x)
## LSTM Parameters:
# `return_seqeunces=True`: return the hidden states for each time step
# `return_state=True`: return the cell state of the last time step
# When both are set True, the return values of LSTM are:
# (1) the hidden states of all time steps (when `return_sequences=True`) or the hidden state of the last time step
# (2) the hidden state of the last time step
# (3) the cell state of the last time step
## Self Attention
atten_out = Attention()([x_all_hs, x_all_hs]) # query and key
atten_out_average = GlobalAveragePooling1D()(atten_out)
x_last_h_plus_atten = Concatenate()([x_last_h, atten_out_average])
x = Dense(16, activation="relu")(x_last_h_plus_atten)
outputs = Dense(1, activation='sigmoid')(x)
model7 = Model(inputs=inputs, outputs=outputs)
plot_model(model7, show_shapes=True)
# ## Model 7 (Attention of lasth on allh)
# inputs = Input(shape=(max_len,))
# x = Embedding(input_dim=vocab_size,
# output_dim=EMBEDDING_DIM,
# input_length=max_len,
# mask_zero=True)(inputs)
# x_all_hs, x_last_h, x_last_c = LSTM(32,
# dropout=0.2,
# recurrent_dropout=0.2,
# return_sequences=True,
# return_state=True)(x)
# ## LSTM Parameters:
# # `return_seqeunces=True`: return the hidden states for each time step
# # `return_state=True`: return the cell state of the last time step
# # When both are set True, the return values of LSTM are:
# # (1) the hidden states of all time steps (when `return_sequences=True`) or the hidden state of the last time step
# # (2) the hidden state of the last time step
# # (3) the cell state of the last time step
# ## Self Attention
# atten_out = Attention()([x_last_h, x_all_hs]) # Attention of last hidden states on all preceding states
# atten_out_average = layers.GlobalMaxPooling1D()(atten_out)
# x_last_h_plus_atten = Concatenate()([x_last_h, atten_out_average])
# x = Dense(16, activation="relu")(x_last_h_plus_atten)
# outputs = Dense(1, activation='sigmoid')(x)
# model7 = Model(inputs=inputs, outputs=outputs)
# plot_model(model7, show_shapes=True)
# ## Model 7 (Self-Attention before RNN)
# inputs = Input(shape=(max_len, ))
# x = Embedding(input_dim=vocab_size,
# output_dim=EMBEDDING_DIM,
# input_length=max_len,
# mask_zero=True)(inputs)
# atten_out = Attention()([x,x])
# x_all_hs, x_last_h, x_last_c = LSTM(32,
# dropout=0.2,
# recurrent_dropout=0.2,
# return_sequences=True,
# return_state=True)(atten_out)
# ## LSTM Parameters:
# # `return_seqeunces=True`: return the hidden states for each time step
# # `return_state=True`: return the cell state of the last time step
# # When both are set True, the return values of LSTM are:
# # (1) the hidden states of all time steps (when `return_sequences=True`) or the hidden state of the last time step
# # (2) the hidden state of the last time step
# # (3) the cell state of the last time step
# x = Dense(16, activation="relu")(x_last_h)
# outputs = Dense(1, activation='sigmoid')(x)
# model7 = Model(inputs=inputs, outputs=outputs)
# plot_model(model7, show_shapes=True)
model7.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
history7 = model7.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/25
12/12 - 12s - loss: 0.6925 - accuracy: 0.5243 - val_loss: 0.6929 - val_accuracy: 0.4833 - 12s/epoch - 1s/step
Epoch 2/25
12/12 - 8s - loss: 0.6809 - accuracy: 0.7174 - val_loss: 0.6812 - val_accuracy: 0.6278 - 8s/epoch - 672ms/step
Epoch 3/25
12/12 - 8s - loss: 0.6183 - accuracy: 0.8222 - val_loss: 0.5941 - val_accuracy: 0.7111 - 8s/epoch - 677ms/step
Epoch 4/25
12/12 - 8s - loss: 0.3753 - accuracy: 0.8681 - val_loss: 0.4825 - val_accuracy: 0.7778 - 8s/epoch - 678ms/step
Epoch 5/25
12/12 - 8s - loss: 0.2170 - accuracy: 0.9618 - val_loss: 0.6088 - val_accuracy: 0.7556 - 8s/epoch - 672ms/step
Epoch 6/25
12/12 - 8s - loss: 0.0985 - accuracy: 0.9694 - val_loss: 0.4559 - val_accuracy: 0.8139 - 8s/epoch - 665ms/step
Epoch 7/25
12/12 - 8s - loss: 0.0429 - accuracy: 0.9910 - val_loss: 0.6644 - val_accuracy: 0.7944 - 8s/epoch - 676ms/step
Epoch 8/25
12/12 - 8s - loss: 0.0181 - accuracy: 0.9958 - val_loss: 0.8001 - val_accuracy: 0.7806 - 8s/epoch - 671ms/step
Epoch 9/25
12/12 - 8s - loss: 0.0068 - accuracy: 1.0000 - val_loss: 0.6540 - val_accuracy: 0.7972 - 8s/epoch - 678ms/step
Epoch 10/25
12/12 - 8s - loss: 0.0042 - accuracy: 1.0000 - val_loss: 0.8686 - val_accuracy: 0.7806 - 8s/epoch - 671ms/step
Epoch 11/25
12/12 - 8s - loss: 0.0024 - accuracy: 1.0000 - val_loss: 1.0425 - val_accuracy: 0.7806 - 8s/epoch - 681ms/step
Epoch 12/25
12/12 - 8s - loss: 0.0261 - accuracy: 0.9917 - val_loss: 0.8744 - val_accuracy: 0.6861 - 8s/epoch - 670ms/step
Epoch 13/25
12/12 - 8s - loss: 0.0653 - accuracy: 0.9854 - val_loss: 0.4876 - val_accuracy: 0.8139 - 8s/epoch - 671ms/step
Epoch 14/25
12/12 - 8s - loss: 0.0253 - accuracy: 0.9958 - val_loss: 0.6208 - val_accuracy: 0.8139 - 8s/epoch - 670ms/step
Epoch 15/25
12/12 - 8s - loss: 0.0108 - accuracy: 0.9972 - val_loss: 0.8965 - val_accuracy: 0.7944 - 8s/epoch - 667ms/step
Epoch 16/25
12/12 - 8s - loss: 0.0053 - accuracy: 0.9986 - val_loss: 0.5973 - val_accuracy: 0.8083 - 8s/epoch - 668ms/step
Epoch 17/25
12/12 - 8s - loss: 0.0034 - accuracy: 1.0000 - val_loss: 0.5949 - val_accuracy: 0.8278 - 8s/epoch - 669ms/step
Epoch 18/25
12/12 - 8s - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.6533 - val_accuracy: 0.8250 - 8s/epoch - 673ms/step
Epoch 19/25
12/12 - 8s - loss: 0.0012 - accuracy: 1.0000 - val_loss: 0.6964 - val_accuracy: 0.8417 - 8s/epoch - 683ms/step
Epoch 20/25
12/12 - 8s - loss: 9.0544e-04 - accuracy: 1.0000 - val_loss: 0.7280 - val_accuracy: 0.8167 - 8s/epoch - 680ms/step
Epoch 21/25
12/12 - 8s - loss: 7.2374e-04 - accuracy: 1.0000 - val_loss: 0.7557 - val_accuracy: 0.8167 - 8s/epoch - 667ms/step
Epoch 22/25
12/12 - 8s - loss: 6.1662e-04 - accuracy: 1.0000 - val_loss: 0.7906 - val_accuracy: 0.8167 - 8s/epoch - 674ms/step
Epoch 23/25
12/12 - 8s - loss: 5.3917e-04 - accuracy: 1.0000 - val_loss: 0.8290 - val_accuracy: 0.8139 - 8s/epoch - 680ms/step
Epoch 24/25
12/12 - 8s - loss: 4.3267e-04 - accuracy: 1.0000 - val_loss: 0.8621 - val_accuracy: 0.8139 - 8s/epoch - 679ms/step
Epoch 25/25
12/12 - 8s - loss: 4.0709e-04 - accuracy: 1.0000 - val_loss: 0.8920 - val_accuracy: 0.8111 - 8s/epoch - 678ms/step
plot1(history7)
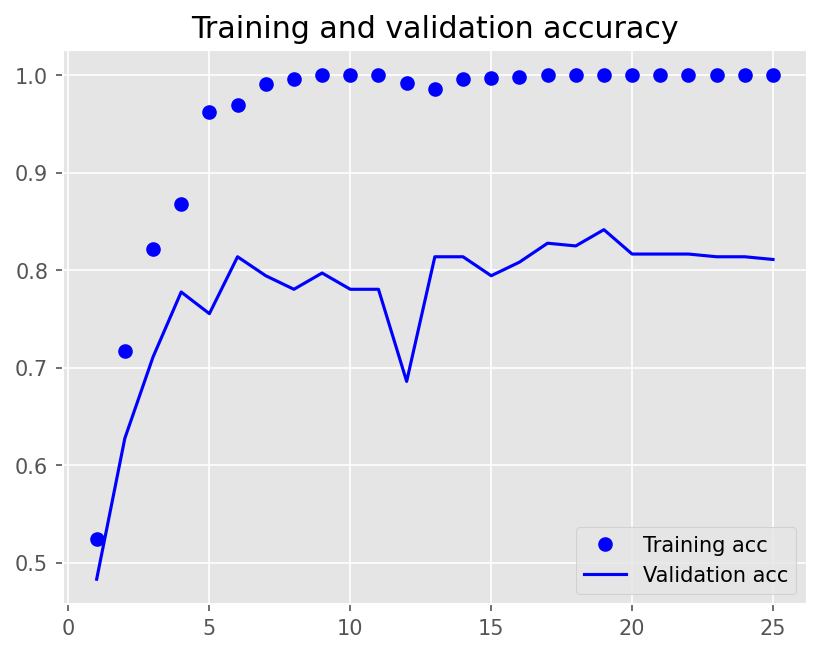
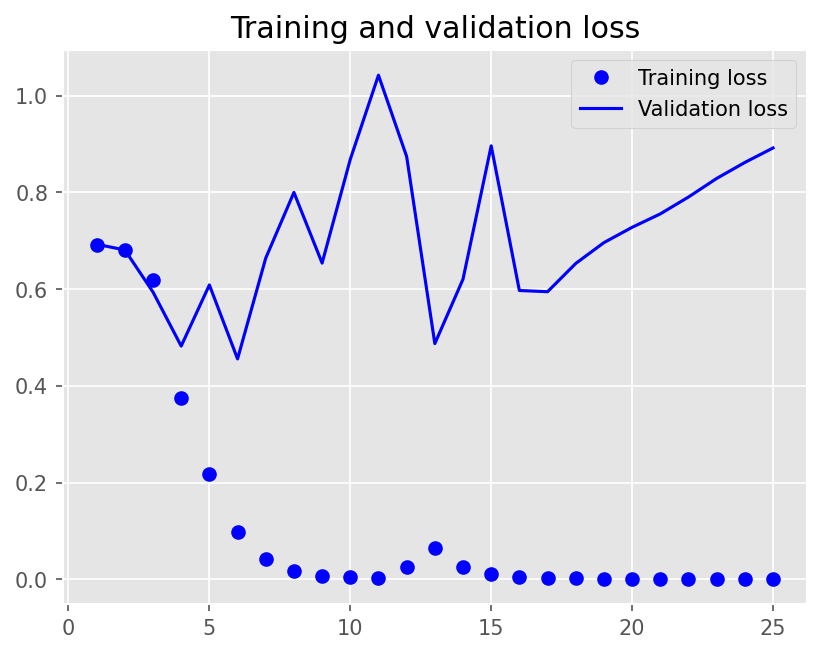
model7.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
2/2 - 0s - loss: 0.8629 - accuracy: 0.8300 - 366ms/epoch - 183ms/step
[0.8629053235054016, 0.8299999833106995]
Explanation#
We use LIME for model explanation.
Let’s inspect the Attention-based Model (model7).
Warning
In our current experiments, we have not considered very carefully the issue of model over-fitting. To optimize the network, it is necessary to include regularization and dropouts to reduce the variation of the model performance on unseen datasets (i.e., generalization).
## Colab only
!pip install lime
Collecting lime
Downloading lime-0.2.0.1.tar.gz (275 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 275.7/275.7 kB 2.6 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from lime) (3.7.1)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from lime) (1.25.2)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from lime) (1.11.4)
Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from lime) (4.66.2)
Requirement already satisfied: scikit-learn>=0.18 in /usr/local/lib/python3.10/dist-packages (from lime) (1.2.2)
Requirement already satisfied: scikit-image>=0.12 in /usr/local/lib/python3.10/dist-packages (from lime) (0.19.3)
Requirement already satisfied: networkx>=2.2 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (3.3)
Requirement already satisfied: pillow!=7.1.0,!=7.1.1,!=8.3.0,>=6.1.0 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (10.3.0)
Requirement already satisfied: imageio>=2.4.1 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (2.34.0)
Requirement already satisfied: tifffile>=2019.7.26 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (2024.2.12)
Requirement already satisfied: PyWavelets>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (1.6.0)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from scikit-image>=0.12->lime) (24.0)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn>=0.18->lime) (1.4.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn>=0.18->lime) (3.4.0)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (1.2.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (4.51.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (1.4.5)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->lime) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->lime) (1.16.0)
Building wheels for collected packages: lime
Building wheel for lime (setup.py) ... ?25l?25hdone
Created wheel for lime: filename=lime-0.2.0.1-py3-none-any.whl size=283835 sha256=1e956a27b9916a111673baaeafca666d2cf4ecea283261cf06c8f0ea2f413425
Stored in directory: /root/.cache/pip/wheels/fd/a2/af/9ac0a1a85a27f314a06b39e1f492bee1547d52549a4606ed89
Successfully built lime
Installing collected packages: lime
Successfully installed lime-0.2.0.1
from lime.lime_text import LimeTextExplainer
explainer = LimeTextExplainer(class_names=['negative', 'positive'],
char_level=False)
## Select the best model so far
best_model = model7
## Pipeline for LIME
def model_predict_pipeline(text):
_seq = tokenizer.texts_to_sequences(text)
_seq_pad = keras.preprocessing.sequence.pad_sequences(_seq, maxlen=max_len)
return np.array([[float(1 - x), float(x)]
for x in best_model.predict(np.array(_seq_pad))])
text_id = 3
exp = explainer.explain_instance(X_test_texts[text_id],
model_predict_pipeline,
num_features=20,
top_labels=1)
exp.show_in_notebook(text=True)
157/157 [==============================] - 10s 62ms/step
<ipython-input-61-a1a375469bbb>:5: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
return np.array([[float(1 - x), float(x)]
exp.show_in_notebook(text=True)
Check Embeddings#
We can also examine the word embeddings learned along with our Classifier.
Steps include:
Extract the embedding weights from the trained model.
Determine words we would like to inspect.
Extract the embeddings of these words.
Use dimensional reduction techniques to plot word embeddings in a 2D graph.
word_vectors = best_model.layers[1].get_weights()[0]
word_vectors.shape
(10001, 128)
## Mapping of embeddings and word-labels
token_labels = [
word for (ind, word) in tokenizer.index_word.items()
if ind < word_vectors.shape[0]
]
token_labels.insert(0, "PAD")
token_labels[:10]
['PAD', 'the', 'a', 'and', 'of', 'to', "'", 'is', 'in', 's']
len(token_labels)
10001
Because there are many words, we select words for visualization based on the following criteria:
Include embeddings of words that are not on the English stopword list (
nltk.corpus.stopwords.words('english')) and whose word length >= 5 (characters)
from sklearn.manifold import TSNE
stopword_list = nltk.corpus.stopwords.words('english')
out_index = [
i for i, w in enumerate(token_labels)
if len(w) >= 5 and w not in stopword_list
]
len(out_index)
8195
out_index[:10]
[27, 69, 70, 73, 80, 83, 95, 97, 100, 102]
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_vectors[out_index[:100], ])
labels = list(np.array(token_labels)[out_index[:100]])
len(labels)
plt.figure(figsize=(10, 10), dpi=150)
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label,
xy=(x + 0.01, y + 0.01),
xytext=(0, 0),
textcoords='offset points')
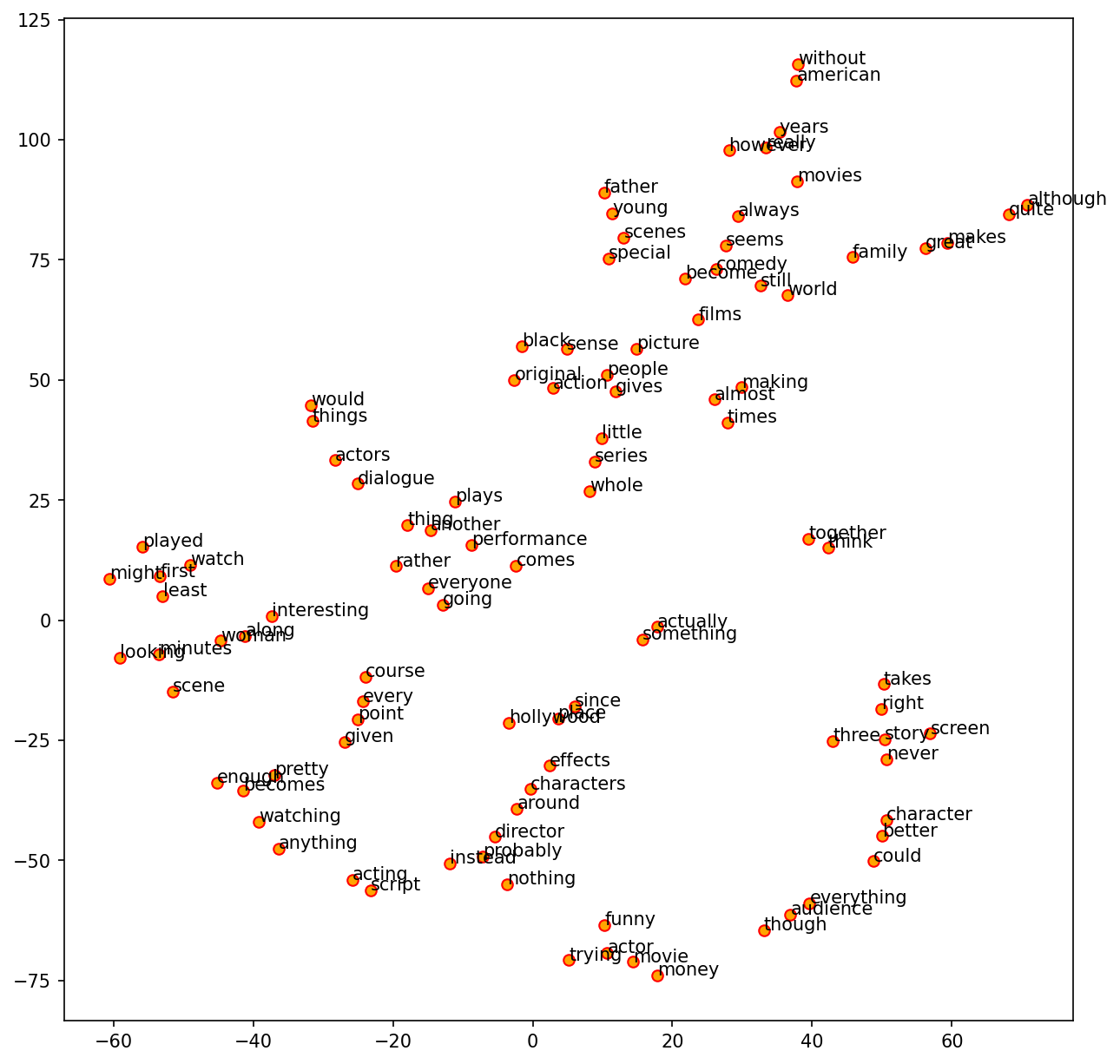
Model Comparisons#
Let’s compare the learning performance of all the models by examining their changes of accuracies and losses in each epoch of training.
history = [
history1, history2, history3, history4, history5, history6, history7
]
history = [i.history for i in history]
model_names = [
'One-hot-dense', 'Embedding-dense', 'RNN', 'Two-RNN', 'Bidirect',
'Hidden-Cell', 'Self-attention'
]
## Set color pallete
import seaborn as sns
qualitative_colors = sns.color_palette("Paired", len(history))
## Accuracy
acc = [i['accuracy'] for i in history]
val_acc = [i['val_accuracy'] for i in history]
plt.figure(figsize=(10, 8))
plt.style.use('ggplot')
for i, a in enumerate(acc):
plt.plot(range(len(a) + 1), [0] + a,
linestyle='--',
marker='o',
color=qualitative_colors[i],
linewidth=1,
label=model_names[i])
plt.legend()
plt.title('Comparing Different Sequence Models')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.tight_layout()
plt.show()
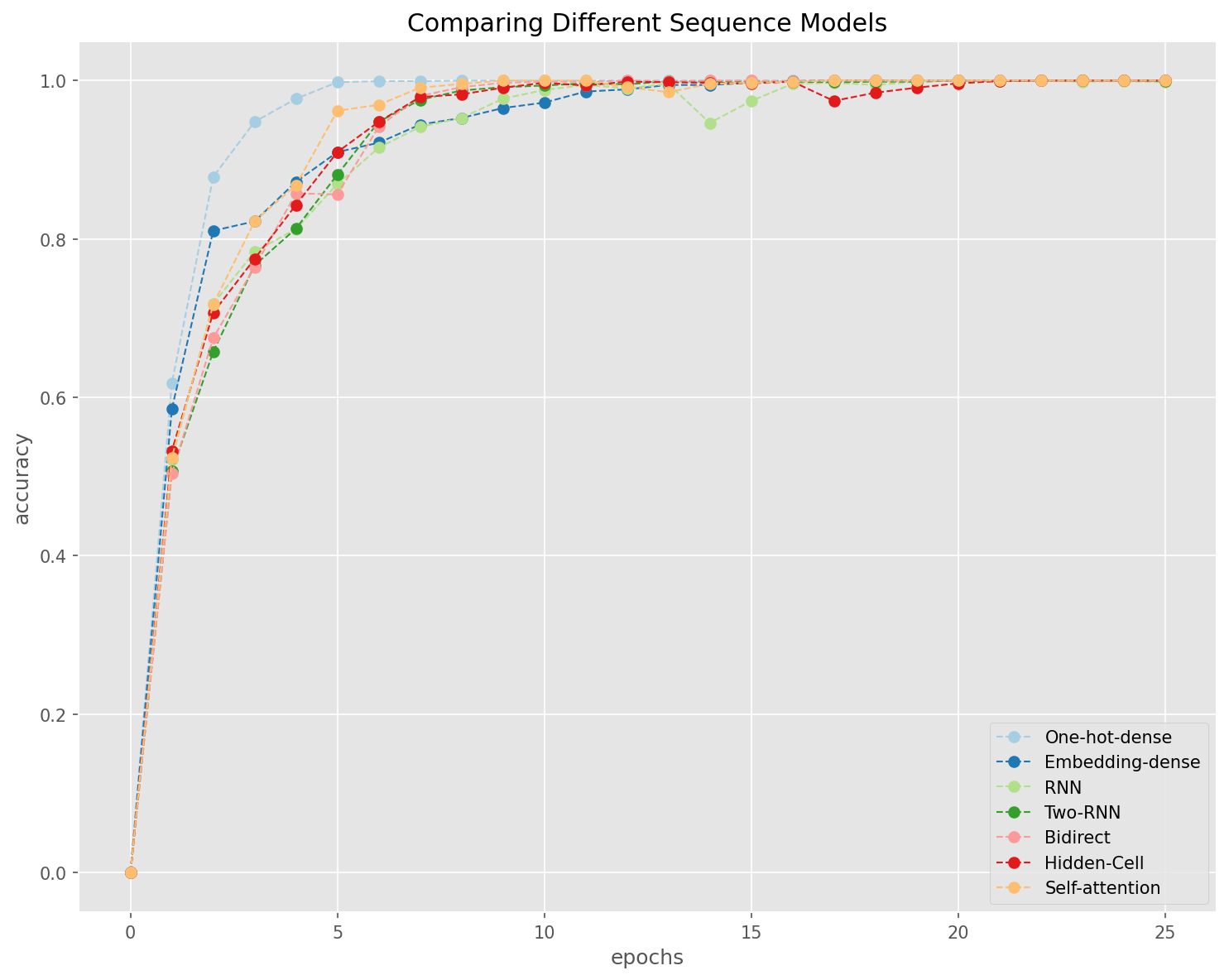
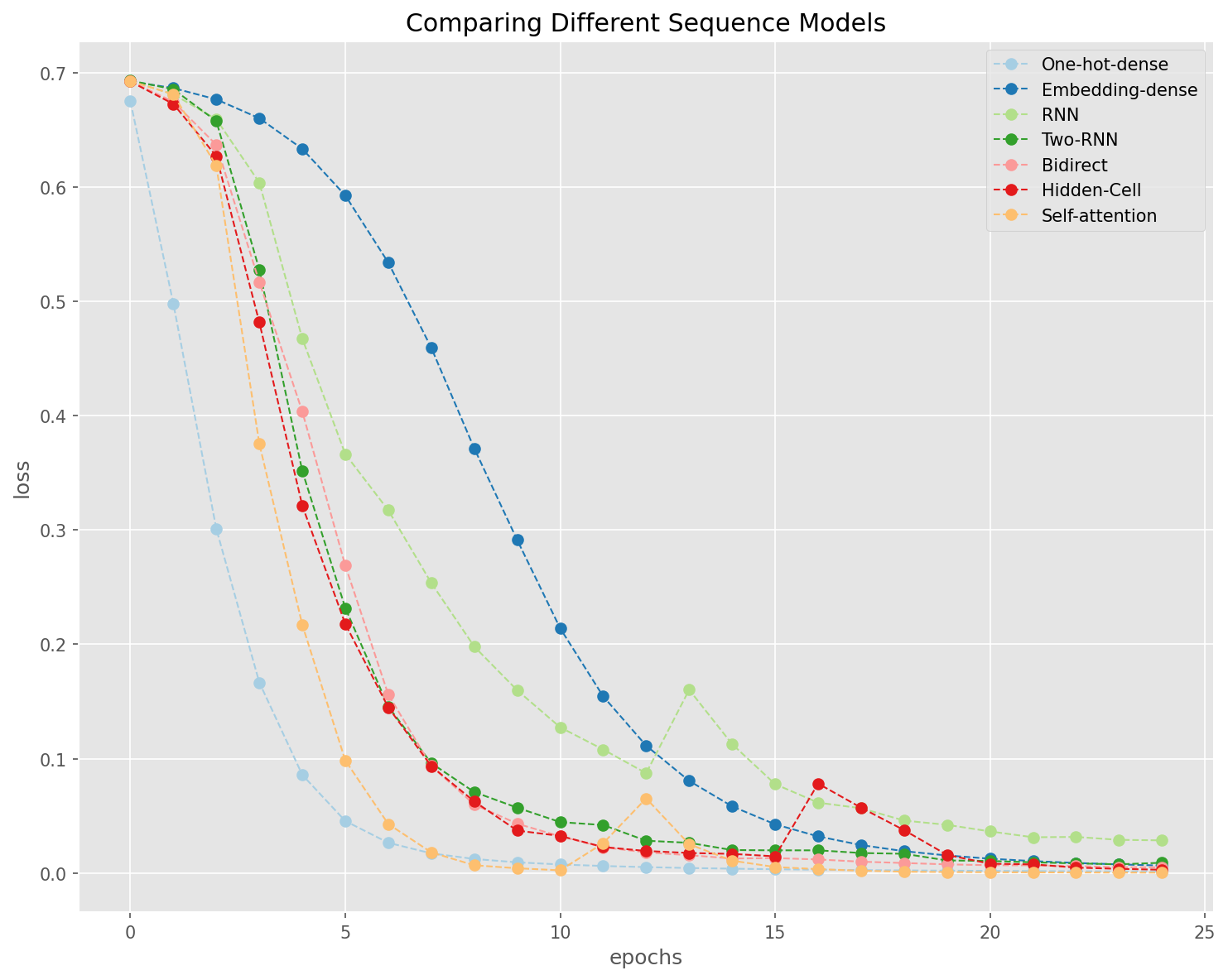
General Observations
Fully-connected network works better with one-hot encoding of texts (i.e., bag-of-words vectorized representations of texts)
Embeddings are more useful when working with sequence models (e.g., RNN).
The self-attention layer, in our current case, is on the entire input sequence, and therefore is limited in its effects.
loss = [i['loss'] for i in history]
plt.figure(figsize=(10, 8))
plt.style.use('ggplot')
for i, a in enumerate(loss):
plt.plot(range(len(a)),
a,
linestyle='--',
marker='o',
color=qualitative_colors[i],
linewidth=1,
label=model_names[i])
plt.legend()
plt.title('Comparing Different Sequence Models')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.tight_layout()
plt.show()