
Sequence Model with Attention for Addition Learning#
In this unit, we will practice on the sequence-to-sequence model using a naive example of numbers addition.
The inputs are sequences of two numbers adding together (e.g., 123+23); the outputs are the correct answers, i.e., the sum of the two numbers (i.e., 125).
This type of sequence model is also referred to as Encoder-Decoder Models.
This task is to simulate the machine translation task (i.e, the sequence to the left of the equation is the source language while the sequence to the right of the equation is the target language).
In particular, we will implement not only a vanilla RNN-based sequence-to-sequence model but also a few extended variants of the RNN, including:
GRU
Bidirectional GRU
Peeky Decoder
Attention-based Decoder
Set up Dependencies#
import re
import tensorflow
import numpy as np
from random import randint
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import GRU
from tensorflow.keras.layers import SimpleRNN
from tensorflow.keras.layers import Bidirectional
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.layers import TimeDistributed
from tensorflow.keras.layers import RepeatVector
from tensorflow.keras.layers import Attention
from tensorflow.keras.layers import AdditiveAttention
from tensorflow.keras.layers import GlobalAveragePooling1D
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.utils import plot_model
print('Tensorflow Version: ', tensorflow.__version__)
Tensorflow Version: 2.13.0
Deep Learning Hyperparameters#
batch_size = 128 # Batch size for training.
epochs = 30 # Epochs for training
latent_dim = 256 # Encoder-Decoder latent dimensions
Data#
Please download the data set from
demo_data/addition-student-version.csv, where each line is a training sample, consisting of the input sequence (e.g.,16+75) and the target sequence (e.g.,91) separated by a comma.We load the data and add initial and ending token to all the target sequences (
_).
## download the dataset
data_path = '../../../RepositoryData/data/deep-learning-2/addition-student-version.csv'
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
## cleaning
lines = [l for l in lines if l!='']
## split input and target
input_texts = [l.split(',')[0] for l in lines]
target_texts = [l.split(',')[-1].strip() for l in lines]
## add special tokens for targets
target_texts = ['_' + sent + '_' for sent in target_texts]
## randomize
np.random.seed(123)
inds = np.arange(len(input_texts))
np.random.shuffle(inds)
## checking
print(input_texts[:5])
print(target_texts[:5])
print('Data Size:', len(input_texts))
['16+75', '52+607', '75+22', '63+22', '795+3']
['_91_', '_659_', '_97_', '_85_', '_798_']
Data Size: 50000
Train-Test Split#
train_test_ratio = 0.9
train_size = int(round(len(lines) * train_test_ratio))
train_inds = inds[:train_size]
test_inds = inds[train_size:]
tr_input_texts = [input_texts[ti] for ti in train_inds]
tr_target_texts = [target_texts[ti] for ti in train_inds]
ts_input_texts = [input_texts[ti] for ti in test_inds]
ts_target_texts = [target_texts[ti] for ti in test_inds]
tr_input_texts[:10]
['27+673',
'153+27',
'93+901',
'243+678',
'269+46',
'235+891',
'46+290',
'324+947',
'721+49',
'535+7']
tr_target_texts[:10]
['_700_',
'_180_',
'_994_',
'_921_',
'_315_',
'_1126_',
'_336_',
'_1271_',
'_770_',
'_542_']
print('Number of Samples:', len(lines))
print('Number of Samples in Training:', len(tr_input_texts))
print('Number of Samples in Testing:', len(ts_input_texts))
Number of Samples: 50000
Number of Samples in Training: 45000
Number of Samples in Testing: 5000
Data Preprocessing#
Text to Sequences#
Tokenization of input and target texts invovles the following important steps:
Create a
TokenizerFit the
Tokenizeron the training setsTokenize input and target texts of the training set into sequences
Identify the maxlen of the input and target sequences
Pad input and target sequences to uniform lengths
Note that we need to create a character-based
Tokenizer.There will be two Tokenizers, one for input texts and the other for target texts.
## Tokenizers for inputs
input_tokenizer = Tokenizer(char_level=True)
input_tokenizer.fit_on_texts(tr_input_texts)
encoder_input_sequences = input_tokenizer.texts_to_sequences(tr_input_texts)
input_maxlen = np.max([len(l) for l in encoder_input_sequences])
encoder_input_sequences = pad_sequences(encoder_input_sequences,
padding='post',
maxlen=input_maxlen)
## Tokenizer for targets
target_tokenizer = Tokenizer(char_level=True)
target_tokenizer.fit_on_texts(tr_target_texts)
target_sequences = target_tokenizer.texts_to_sequences(tr_target_texts)
target_maxlen = np.max([len(l) for l in target_sequences])
target_sequences = pad_sequences(target_sequences,
padding='post',
maxlen=target_maxlen)
## Shapes of Input and Target Sequences
print(encoder_input_sequences.shape)
print(target_sequences.shape)
(45000, 7)
(45000, 6)
## vocab size
input_vsize = max(input_tokenizer.index_word.keys()) + 1
target_vsize = max(target_tokenizer.index_word.keys()) + 1
Note
The plus 1 for vocabulary size is to include the padding character, whose index is the reserved 0.
print(input_vsize)
print(target_vsize)
12
12
print(tr_input_texts[:3])
print(encoder_input_sequences[:3])
['27+673', '153+27', '93+901']
[[ 9 10 1 7 10 5 0]
[ 8 6 5 1 9 10 0]
[ 2 5 1 2 11 8 0]]
input_tokenizer.word_index
{'+': 1,
'9': 2,
'4': 3,
'8': 4,
'3': 5,
'5': 6,
'6': 7,
'1': 8,
'2': 9,
'7': 10,
'0': 11}
print(tr_target_texts[:3])
print(target_sequences[:3])
['_700_', '_180_', '_994_']
[[ 1 4 11 11 1 0]
[ 1 2 10 11 1 0]
[ 1 7 7 8 1 0]]
target_tokenizer.word_index
{'_': 1,
'1': 2,
'2': 3,
'7': 4,
'6': 5,
'3': 6,
'9': 7,
'4': 8,
'5': 9,
'8': 10,
'0': 11}
Special Considerations for Decoder’s Input and Output#
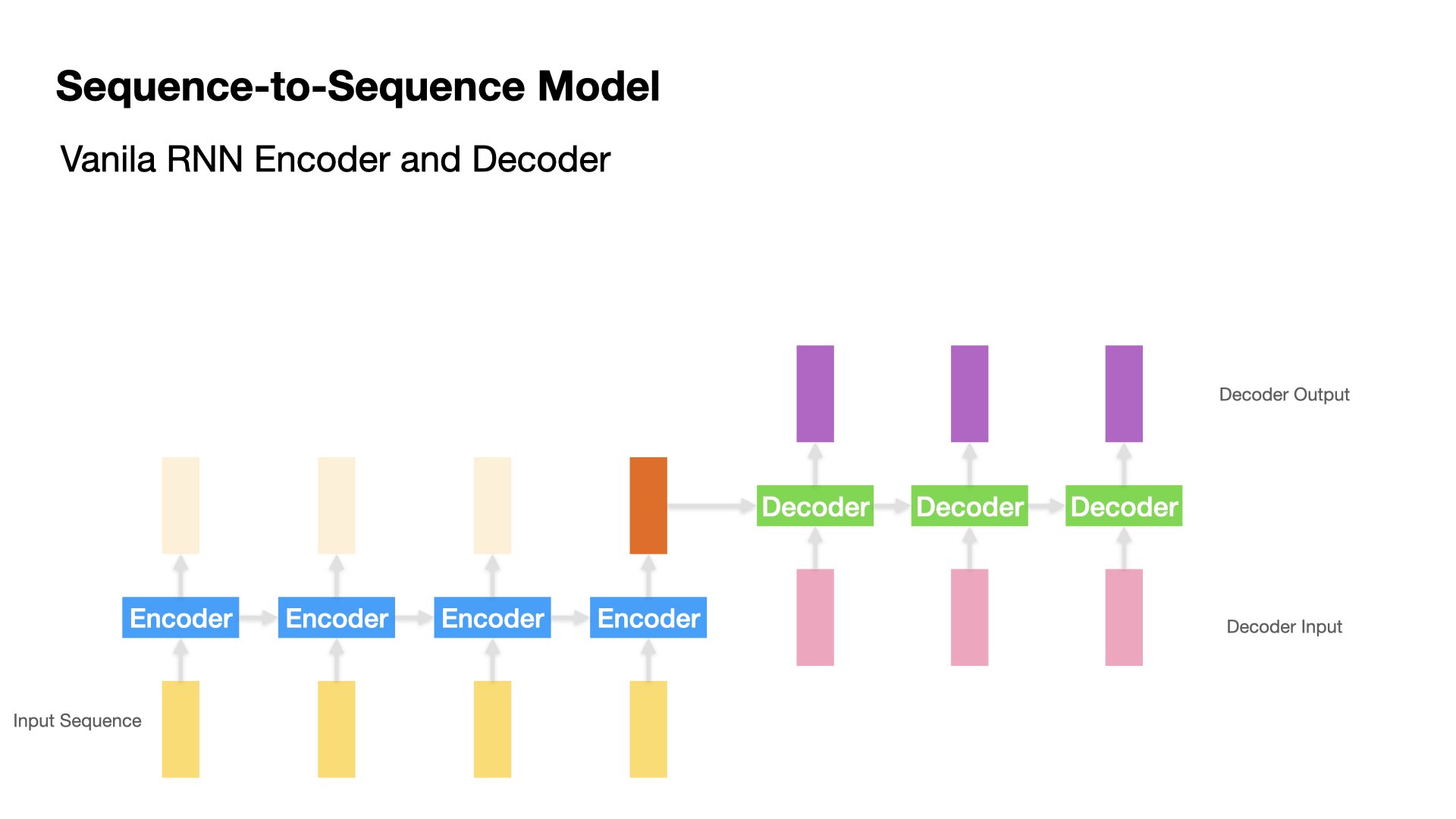
In the training stage, we give the Decoder the correct target sequences for teacher forcing.
Input and Output Sequences for Decoder
Decoder input and output sequences have one time-step difference (i.e., the decoder’s output at \(t-1\) is the decoder’s input at \(t\))
We create decoder input and output sequences as different sets of data.
decoder_input_sequences = target_sequences[:,:-1]
decoder_output_sequences = target_sequences[:,1:]
print(decoder_input_sequences[:5])
print(decoder_output_sequences[:5])
[[ 1 4 11 11 1]
[ 1 2 10 11 1]
[ 1 7 7 8 1]
[ 1 7 3 2 1]
[ 1 6 2 9 1]]
[[ 4 11 11 1 0]
[ 2 10 11 1 0]
[ 7 7 8 1 0]
[ 7 3 2 1 0]
[ 6 2 9 1 0]]
Sequences to One-Hot Encoding#
To simplify the matter, we convert each sequence/integer token into one-hot encoding, which will be the input of the Encoder directly.
Normally we would add an Embedding layer to convert sequence tokens to embeddings before sending them to the Encoder.
Please note that this step renders the text representation of the entire training data from 2D (
batch_size,max_length) to 3D tensors (batch_size,max_length,vocab_size).
Note
For neural machine translations, the vocabulary sizes of the input and target languages are usually very large. It is more effective to implement an Embedding layer to convert sequences (integers) into embeddings, rather than one-hot encodings.
For this tutorial, we have a limited vocabulary size (only digits and math symbols). One-hot encodings should be fine.
However, in the assignment, you will practice on how to add embedding layers for both Encoder and Decoder.
print(encoder_input_sequences.shape)
print(decoder_input_sequences.shape)
print(decoder_output_sequences.shape)
(45000, 7)
(45000, 5)
(45000, 5)
encoder_input_onehot = to_categorical(encoder_input_sequences,
num_classes=input_vsize)
decoder_input_onehot = to_categorical(decoder_input_sequences,
num_classes=target_vsize)
decoder_output_onehot = to_categorical(decoder_output_sequences,
num_classes=target_vsize)
print(encoder_input_onehot.shape)
print(decoder_input_onehot.shape)
print(decoder_output_onehot.shape)
(45000, 7, 12)
(45000, 5, 12)
(45000, 5, 12)
Token Indices#
We create the integer-to-character dictionaries for later use.
Two dictionaries, one for the input sequence and one for the target sequence.
""" Index2word """
enc_index2word = dict(
zip(input_tokenizer.word_index.values(),
input_tokenizer.word_index.keys()))
dec_index2word = dict(
zip(target_tokenizer.word_index.values(),
target_tokenizer.word_index.keys()))
enc_index2word
{1: '+',
2: '9',
3: '4',
4: '8',
5: '3',
6: '5',
7: '6',
8: '1',
9: '2',
10: '7',
11: '0'}
dec_index2word
{1: '_',
2: '1',
3: '2',
4: '7',
5: '6',
6: '3',
7: '9',
8: '4',
9: '5',
10: '8',
11: '0'}
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
matplotlib.rcParams['figure.dpi'] = 150
# Plotting results
def plot1(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
## Accuracy plot
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
## Loss plot
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
def plot2(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
#plt.gca().set_ylim(0,1)
plt.show()
Model Training#
Define the model architecture
Train the model
Sequence-to-Sequence can go from simple RNNs to complex models with attention mechanisms.
In this tutorial, we will try the following:
Sequence-to-sequence model with vanilla RNN Encoder and Decoder
Sequence-to-sequence model with GRU Encoder and Decoder
Sequence-to-sequence model with bidirectional RNN Encoder
Sequence-to-sequence model with peeky Decoder
Sequence-to-sequence model with attention-based Decoder
Sequential vs. Functional API in
kerasWe have been using the Sequential API to create the network models, where each layer’s output is the input of the subsequent layer.
However, for Encoder-Decoder Models, sometimes not all the outputs of the previous layer are the inputs of the subsequent layer.
We need more flexibility in the ways of connecting the inputs and outputs of the model layers.
Therefore, here we will use the Functional API for model definition.
Model 1 (Vanilla RNN)#
Define Model#
Important Highlights:
In the training stage, we feed the decoder the correct answer at each time step as the input sequence.
In the testing stage, the decoder will take the hidden state from the previous time step as the input sequence.
This type of training is referred to as teacher forcing learning strategy. This can help the model converge more effectively.
The decoder uses encoder’s last hidden state as the initial hidden state.
# Define Model Inputs
encoder_inputs = Input(shape=(input_maxlen, input_vsize),
name='encoder_inputs')
decoder_inputs = Input(shape=(target_maxlen - 1, target_vsize),
name='decoder_inputs')
# Encoder RNN
## first return is the hidden states of all timesteps of encoder
## second return is the last hidden state of encoder
encoder_rnn = SimpleRNN(latent_dim,
return_sequences=True,
return_state=True,
name='encoder_rnn')
_, encoder_state = encoder_rnn(encoder_inputs)
# Decoder RNN
## using `encoder_state` (last h) as initial state.
## using `decoder_inputs` for teacher forcing learning
decoder_rnn = SimpleRNN(latent_dim,
return_sequences=True,
return_state=True,
name='decoder_rnn')
decoder_out, _ = decoder_rnn(decoder_inputs, initial_state=encoder_state)
# Dense layer
dense = Dense(target_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_out)
# Full model
full_model1 = Model(inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_pred)
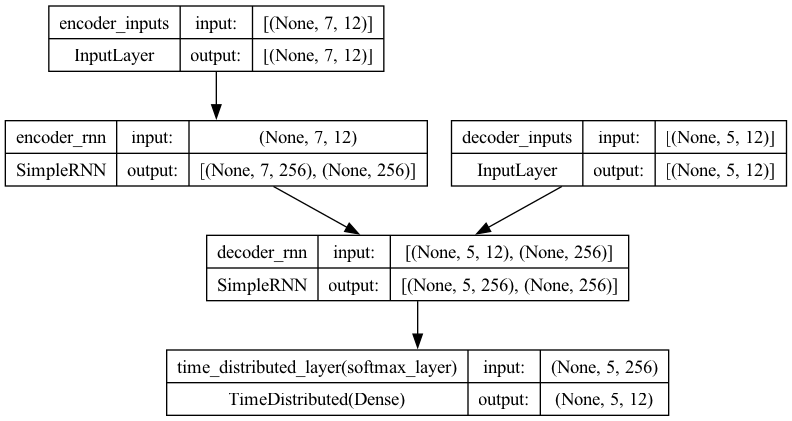
full_model1.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
encoder_rnn (SimpleRNN) [(None, 7, 256), 68864 ['encoder_inputs[0][0]']
(None, 256)]
decoder_rnn (SimpleRNN) [(None, 5, 256), 68864 ['decoder_inputs[0][0]',
(None, 256)] 'encoder_rnn[0][1]']
time_distributed_layer (Ti (None, 5, 12) 3084 ['decoder_rnn[0][0]']
meDistributed)
==================================================================================================
Total params: 140812 (550.05 KB)
Trainable params: 140812 (550.05 KB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
Note
It is crucial to wrap the Dense layer with TimeDistributed layer. The TimeDistributed wrapper ensures that the Dense layer is applied independently to each time step in the input sequence. This is useful in models that deal with sequences, such as RNNs, LSTMs, and GRUs, where you need to apply the same layer to each element of the sequence.
plot_model(full_model1, show_shapes=True)
Training#
# Run training
full_model1.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history1 = full_model1.fit([encoder_input_onehot, decoder_input_onehot],
decoder_output_onehot,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Show code cell output
Epoch 1/30
282/282 [==============================] - 3s 9ms/step - loss: 1.3127 - accuracy: 0.5142 - val_loss: 1.1931 - val_accuracy: 0.5534
Epoch 2/30
282/282 [==============================] - 2s 8ms/step - loss: 1.1009 - accuracy: 0.5870 - val_loss: 1.0211 - val_accuracy: 0.6139
Epoch 3/30
282/282 [==============================] - 2s 9ms/step - loss: 0.9173 - accuracy: 0.6500 - val_loss: 0.8363 - val_accuracy: 0.6737
Epoch 4/30
282/282 [==============================] - 2s 8ms/step - loss: 0.7440 - accuracy: 0.7129 - val_loss: 0.6818 - val_accuracy: 0.7317
Epoch 5/30
282/282 [==============================] - 2s 9ms/step - loss: 0.6040 - accuracy: 0.7679 - val_loss: 0.5688 - val_accuracy: 0.7736
Epoch 6/30
282/282 [==============================] - 2s 9ms/step - loss: 0.4908 - accuracy: 0.8138 - val_loss: 0.4671 - val_accuracy: 0.8196
Epoch 7/30
282/282 [==============================] - 2s 9ms/step - loss: 0.4137 - accuracy: 0.8431 - val_loss: 0.4192 - val_accuracy: 0.8309
Epoch 8/30
282/282 [==============================] - 2s 9ms/step - loss: 0.3442 - accuracy: 0.8698 - val_loss: 0.3372 - val_accuracy: 0.8660
Epoch 9/30
282/282 [==============================] - 2s 8ms/step - loss: 0.2847 - accuracy: 0.8935 - val_loss: 0.2892 - val_accuracy: 0.8892
Epoch 10/30
282/282 [==============================] - 2s 9ms/step - loss: 0.2376 - accuracy: 0.9132 - val_loss: 0.2696 - val_accuracy: 0.8958
Epoch 11/30
282/282 [==============================] - 2s 8ms/step - loss: 0.2146 - accuracy: 0.9217 - val_loss: 0.2328 - val_accuracy: 0.9116
Epoch 12/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1927 - accuracy: 0.9297 - val_loss: 0.2322 - val_accuracy: 0.9084
Epoch 13/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1678 - accuracy: 0.9413 - val_loss: 0.1838 - val_accuracy: 0.9302
Epoch 14/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1561 - accuracy: 0.9441 - val_loss: 0.2071 - val_accuracy: 0.9191
Epoch 15/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1451 - accuracy: 0.9475 - val_loss: 0.1814 - val_accuracy: 0.9309
Epoch 16/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1431 - accuracy: 0.9479 - val_loss: 0.1869 - val_accuracy: 0.9290
Epoch 17/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1262 - accuracy: 0.9548 - val_loss: 0.1534 - val_accuracy: 0.9424
Epoch 18/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1185 - accuracy: 0.9584 - val_loss: 0.1880 - val_accuracy: 0.9298
Epoch 19/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1123 - accuracy: 0.9603 - val_loss: 0.1497 - val_accuracy: 0.9433
Epoch 20/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1094 - accuracy: 0.9608 - val_loss: 0.1479 - val_accuracy: 0.9422
Epoch 21/30
282/282 [==============================] - 2s 9ms/step - loss: 0.0959 - accuracy: 0.9669 - val_loss: 0.1568 - val_accuracy: 0.9399
Epoch 22/30
282/282 [==============================] - 2s 9ms/step - loss: 0.1089 - accuracy: 0.9607 - val_loss: 0.1576 - val_accuracy: 0.9422
Epoch 23/30
282/282 [==============================] - 2s 9ms/step - loss: 0.0907 - accuracy: 0.9678 - val_loss: 0.1418 - val_accuracy: 0.9453
Epoch 24/30
282/282 [==============================] - 2s 9ms/step - loss: 0.0892 - accuracy: 0.9685 - val_loss: 0.1580 - val_accuracy: 0.9417
Epoch 25/30
282/282 [==============================] - 2s 9ms/step - loss: 0.0906 - accuracy: 0.9672 - val_loss: 0.1567 - val_accuracy: 0.9409
Epoch 26/30
282/282 [==============================] - 3s 9ms/step - loss: 0.0897 - accuracy: 0.9678 - val_loss: 0.1396 - val_accuracy: 0.9479
Epoch 27/30
282/282 [==============================] - 3s 9ms/step - loss: 0.0855 - accuracy: 0.9698 - val_loss: 0.1460 - val_accuracy: 0.9464
Epoch 28/30
282/282 [==============================] - 2s 9ms/step - loss: 0.0842 - accuracy: 0.9704 - val_loss: 0.1445 - val_accuracy: 0.9467
Epoch 29/30
282/282 [==============================] - 3s 9ms/step - loss: 0.0825 - accuracy: 0.9708 - val_loss: 0.1409 - val_accuracy: 0.9473
Epoch 30/30
282/282 [==============================] - 3s 9ms/step - loss: 0.0694 - accuracy: 0.9759 - val_loss: 0.1590 - val_accuracy: 0.9417
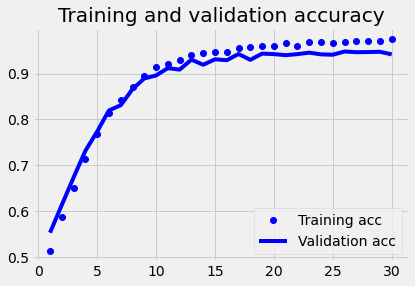
plot1(history1)
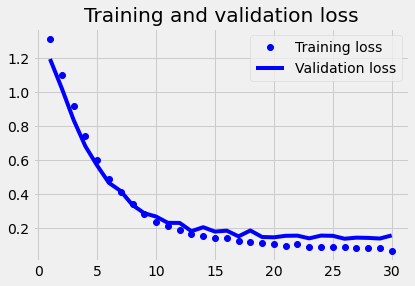
Model 2 (GRU)#
Define Model#
Important highlights:
In Model 2, we replace vanilla RNN with GRU, which deals with the issue of long-distance dependencies between sequences.
You can try LSTM as well.
# Define Model Inputs
encoder_inputs = Input(shape=(input_maxlen, input_vsize),
name='encoder_inputs')
decoder_inputs = Input(shape=(target_maxlen - 1, target_vsize),
name='decoder_inputs')
# Encoder GRU
## first return is the hidden states of all timesteps of encoder
## second return is the last hidden state of encoder
encoder_gru = GRU(latent_dim,
return_sequences=True,
return_state=True,
name='encoder_gru')
_, encoder_state = encoder_gru(encoder_inputs)
# Decoder RNN
## using `encoder_state` (last h) as initial state.
## using `decoder_inputs` for teacher forcing learning
decoder_gru = GRU(latent_dim,
return_sequences=True,
return_state=True,
name='decoder_gru')
decoder_out, _ = decoder_gru(decoder_inputs, initial_state=encoder_state)
# Dense layer
dense = Dense(target_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_out)
# Full model
full_model2 = Model(inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_pred)
full_model2.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
encoder_gru (GRU) [(None, 7, 256), 207360 ['encoder_inputs[0][0]']
(None, 256)]
decoder_gru (GRU) [(None, 5, 256), 207360 ['decoder_inputs[0][0]',
(None, 256)] 'encoder_gru[0][1]']
time_distributed_layer (Ti (None, 5, 12) 3084 ['decoder_gru[0][0]']
meDistributed)
==================================================================================================
Total params: 417804 (1.59 MB)
Trainable params: 417804 (1.59 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
plot_model(full_model2, show_shapes=True)
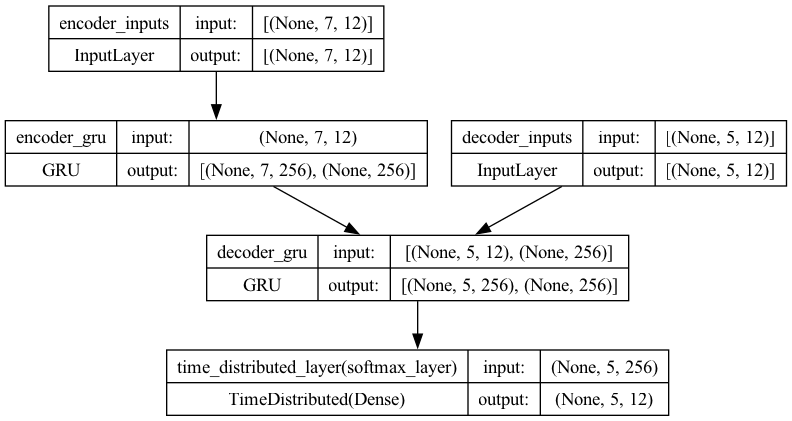
Training#
# Run training
full_model2.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history2 = full_model2.fit([encoder_input_onehot, decoder_input_onehot],
decoder_output_onehot,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Show code cell output
Epoch 1/30
282/282 [==============================] - 7s 22ms/step - loss: 1.4847 - accuracy: 0.4599 - val_loss: 1.3745 - val_accuracy: 0.4835
Epoch 2/30
282/282 [==============================] - 6s 22ms/step - loss: 1.3170 - accuracy: 0.5044 - val_loss: 1.2046 - val_accuracy: 0.5423
Epoch 3/30
282/282 [==============================] - 6s 22ms/step - loss: 1.1033 - accuracy: 0.5820 - val_loss: 1.0287 - val_accuracy: 0.6080
Epoch 4/30
282/282 [==============================] - 6s 23ms/step - loss: 0.9732 - accuracy: 0.6299 - val_loss: 0.9163 - val_accuracy: 0.6503
Epoch 5/30
282/282 [==============================] - 6s 22ms/step - loss: 0.8589 - accuracy: 0.6723 - val_loss: 0.8084 - val_accuracy: 0.6925
Epoch 6/30
282/282 [==============================] - 6s 22ms/step - loss: 0.7667 - accuracy: 0.7077 - val_loss: 0.7415 - val_accuracy: 0.7166
Epoch 7/30
282/282 [==============================] - 6s 23ms/step - loss: 0.7039 - accuracy: 0.7360 - val_loss: 0.6964 - val_accuracy: 0.7313
Epoch 8/30
282/282 [==============================] - 7s 23ms/step - loss: 0.6590 - accuracy: 0.7528 - val_loss: 0.6635 - val_accuracy: 0.7428
Epoch 9/30
282/282 [==============================] - 7s 25ms/step - loss: 0.6170 - accuracy: 0.7666 - val_loss: 0.6115 - val_accuracy: 0.7636
Epoch 10/30
282/282 [==============================] - 7s 24ms/step - loss: 0.5770 - accuracy: 0.7796 - val_loss: 0.5821 - val_accuracy: 0.7709
Epoch 11/30
282/282 [==============================] - 7s 24ms/step - loss: 0.5386 - accuracy: 0.7918 - val_loss: 0.5455 - val_accuracy: 0.7836
Epoch 12/30
282/282 [==============================] - 6s 23ms/step - loss: 0.5118 - accuracy: 0.8005 - val_loss: 0.5117 - val_accuracy: 0.7965
Epoch 13/30
282/282 [==============================] - 7s 23ms/step - loss: 0.4765 - accuracy: 0.8132 - val_loss: 0.4848 - val_accuracy: 0.8067
Epoch 14/30
282/282 [==============================] - 7s 23ms/step - loss: 0.4444 - accuracy: 0.8262 - val_loss: 0.4512 - val_accuracy: 0.8171
Epoch 15/30
282/282 [==============================] - 7s 23ms/step - loss: 0.4040 - accuracy: 0.8414 - val_loss: 0.4349 - val_accuracy: 0.8220
Epoch 16/30
282/282 [==============================] - 6s 23ms/step - loss: 0.3529 - accuracy: 0.8625 - val_loss: 0.3531 - val_accuracy: 0.8574
Epoch 17/30
282/282 [==============================] - 7s 23ms/step - loss: 0.3035 - accuracy: 0.8842 - val_loss: 0.3054 - val_accuracy: 0.8799
Epoch 18/30
282/282 [==============================] - 7s 24ms/step - loss: 0.2529 - accuracy: 0.9064 - val_loss: 0.2599 - val_accuracy: 0.8991
Epoch 19/30
282/282 [==============================] - 7s 25ms/step - loss: 0.2105 - accuracy: 0.9242 - val_loss: 0.2181 - val_accuracy: 0.9173
Epoch 20/30
282/282 [==============================] - 7s 24ms/step - loss: 0.1728 - accuracy: 0.9386 - val_loss: 0.1745 - val_accuracy: 0.9346
Epoch 21/30
282/282 [==============================] - 7s 24ms/step - loss: 0.1399 - accuracy: 0.9509 - val_loss: 0.1543 - val_accuracy: 0.9406
Epoch 22/30
282/282 [==============================] - 7s 25ms/step - loss: 0.1172 - accuracy: 0.9592 - val_loss: 0.1319 - val_accuracy: 0.9505
Epoch 23/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0895 - accuracy: 0.9708 - val_loss: 0.0991 - val_accuracy: 0.9650
Epoch 24/30
282/282 [==============================] - 7s 24ms/step - loss: 0.0755 - accuracy: 0.9761 - val_loss: 0.0893 - val_accuracy: 0.9668
Epoch 25/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0552 - accuracy: 0.9845 - val_loss: 0.0738 - val_accuracy: 0.9743
Epoch 26/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0499 - accuracy: 0.9858 - val_loss: 0.1067 - val_accuracy: 0.9602
Epoch 27/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0521 - accuracy: 0.9837 - val_loss: 0.0708 - val_accuracy: 0.9749
Epoch 28/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0381 - accuracy: 0.9895 - val_loss: 0.0543 - val_accuracy: 0.9811
Epoch 29/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0338 - accuracy: 0.9907 - val_loss: 0.0495 - val_accuracy: 0.9829
Epoch 30/30
282/282 [==============================] - 7s 25ms/step - loss: 0.0360 - accuracy: 0.9895 - val_loss: 0.0582 - val_accuracy: 0.9796
plot1(history2)
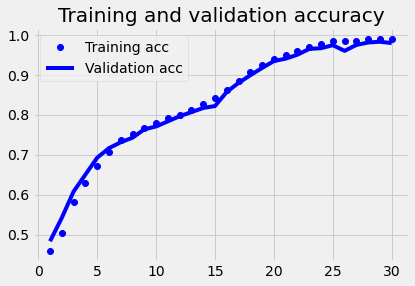
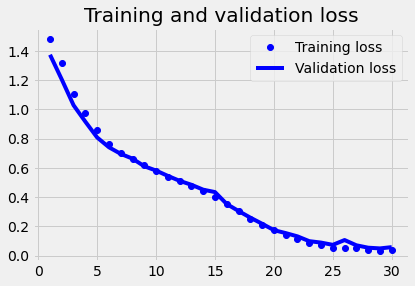
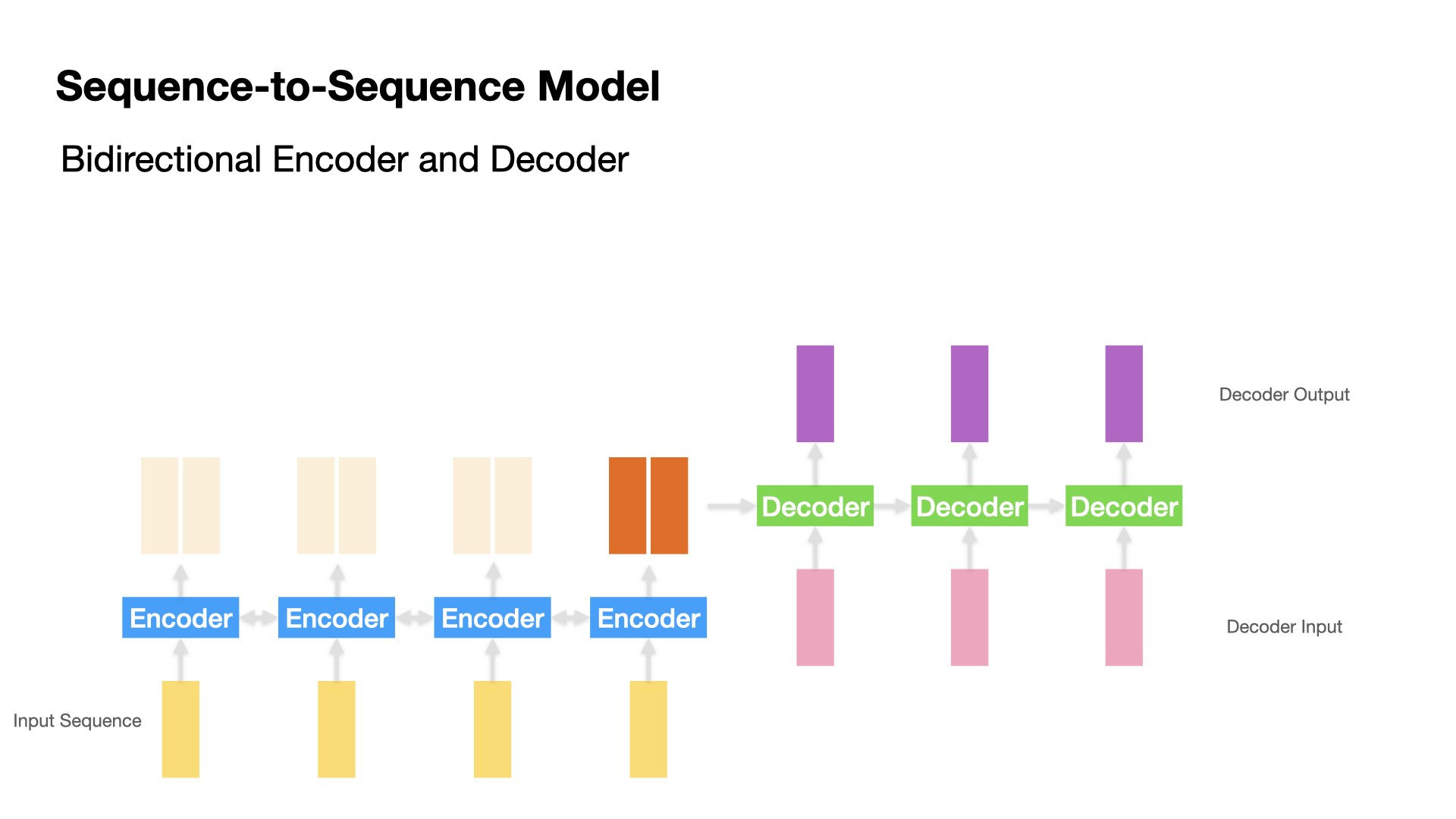
Model 3 (Birdirectional)#
Define Model#
Important highlights:
In Model 3, we implement a bi-directional Encoder.
At each encoding step, there will be two hidden states (i.e., forward and backward passes)
# Define Model Inputs
encoder_inputs = Input(shape=(input_maxlen, input_vsize),
name='encoder_inputs')
decoder_inputs = Input(shape=(target_maxlen - 1, target_vsize),
name='decoder_inputs')
# Encoder GRU
encoder_gru = Bidirectional(
GRU(latent_dim,
return_sequences=True,
return_state=True,
name='encoder_gru'))
_, encoder_state_fwd, encoder_state_bwd = encoder_gru(encoder_inputs)
# Combine forward and backward state (last h's) from encoder
encoder_state = Concatenate(axis=-1)([encoder_state_fwd, encoder_state_bwd])
# Decoder GRU
# using `encoder_state` as initial state
# the latent_dim *2 because we use two last states from the bidirectional encoder
decoder_gru = GRU(latent_dim * 2,
return_sequences=True,
return_state=True,
name='decoder_gru')
decoder_out, _ = decoder_gru(decoder_inputs, initial_state=encoder_state)
# Dense layer
dense = Dense(target_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_out)
# Full model
full_model3 = Model(inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_pred)
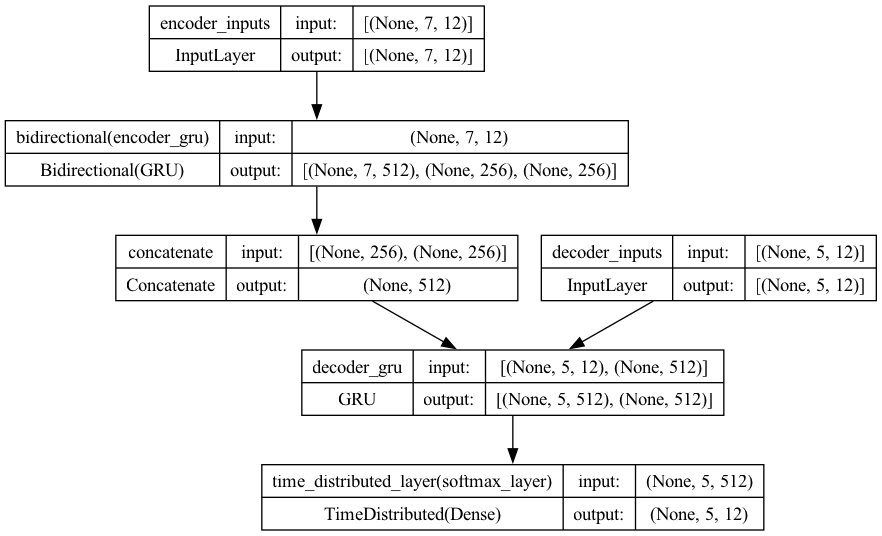
full_model3.summary()
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
bidirectional (Bidirection [(None, 7, 512), 414720 ['encoder_inputs[0][0]']
al) (None, 256),
(None, 256)]
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
concatenate (Concatenate) (None, 512) 0 ['bidirectional[0][1]',
'bidirectional[0][2]']
decoder_gru (GRU) [(None, 5, 512), 807936 ['decoder_inputs[0][0]',
(None, 512)] 'concatenate[0][0]']
time_distributed_layer (Ti (None, 5, 12) 6156 ['decoder_gru[0][0]']
meDistributed)
==================================================================================================
Total params: 1228812 (4.69 MB)
Trainable params: 1228812 (4.69 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
plot_model(full_model3, show_shapes=True)
Training#
# Run training
full_model3.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history3 = full_model3.fit([encoder_input_onehot, decoder_input_onehot],
decoder_output_onehot,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Show code cell output
Epoch 1/30
282/282 [==============================] - 12s 37ms/step - loss: 1.4408 - accuracy: 0.4702 - val_loss: 1.3021 - val_accuracy: 0.5137
Epoch 2/30
282/282 [==============================] - 11s 39ms/step - loss: 1.1192 - accuracy: 0.5754 - val_loss: 0.9751 - val_accuracy: 0.6264
Epoch 3/30
282/282 [==============================] - 12s 43ms/step - loss: 0.8618 - accuracy: 0.6683 - val_loss: 0.8019 - val_accuracy: 0.6840
Epoch 4/30
282/282 [==============================] - 11s 39ms/step - loss: 0.7199 - accuracy: 0.7256 - val_loss: 0.6826 - val_accuracy: 0.7352
Epoch 5/30
282/282 [==============================] - 12s 43ms/step - loss: 0.6149 - accuracy: 0.7667 - val_loss: 0.5581 - val_accuracy: 0.7875
Epoch 6/30
282/282 [==============================] - 12s 41ms/step - loss: 0.4916 - accuracy: 0.8153 - val_loss: 0.4018 - val_accuracy: 0.8436
Epoch 7/30
282/282 [==============================] - 12s 44ms/step - loss: 0.2687 - accuracy: 0.9028 - val_loss: 0.2229 - val_accuracy: 0.9060
Epoch 8/30
282/282 [==============================] - 12s 42ms/step - loss: 0.1327 - accuracy: 0.9587 - val_loss: 0.1096 - val_accuracy: 0.9638
Epoch 9/30
282/282 [==============================] - 11s 40ms/step - loss: 0.0713 - accuracy: 0.9826 - val_loss: 0.0769 - val_accuracy: 0.9760
Epoch 10/30
282/282 [==============================] - 12s 43ms/step - loss: 0.0663 - accuracy: 0.9815 - val_loss: 0.0558 - val_accuracy: 0.9846
Epoch 11/30
282/282 [==============================] - 12s 41ms/step - loss: 0.0350 - accuracy: 0.9928 - val_loss: 0.0443 - val_accuracy: 0.9868
Epoch 12/30
282/282 [==============================] - 12s 43ms/step - loss: 0.0573 - accuracy: 0.9843 - val_loss: 0.0260 - val_accuracy: 0.9943
Epoch 13/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0184 - accuracy: 0.9969 - val_loss: 0.0277 - val_accuracy: 0.9920
Epoch 14/30
282/282 [==============================] - 12s 41ms/step - loss: 0.0425 - accuracy: 0.9869 - val_loss: 0.0343 - val_accuracy: 0.9892
Epoch 15/30
282/282 [==============================] - 11s 40ms/step - loss: 0.0155 - accuracy: 0.9971 - val_loss: 0.0151 - val_accuracy: 0.9962
Epoch 16/30
282/282 [==============================] - 12s 43ms/step - loss: 0.0129 - accuracy: 0.9973 - val_loss: 0.0655 - val_accuracy: 0.9763
Epoch 17/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0511 - accuracy: 0.9833 - val_loss: 0.0160 - val_accuracy: 0.9962
Epoch 18/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0073 - accuracy: 0.9991 - val_loss: 0.0101 - val_accuracy: 0.9976
Epoch 19/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0060 - accuracy: 0.9991 - val_loss: 0.0170 - val_accuracy: 0.9947
Epoch 20/30
282/282 [==============================] - 12s 43ms/step - loss: 0.0527 - accuracy: 0.9833 - val_loss: 0.0827 - val_accuracy: 0.9717
Epoch 21/30
282/282 [==============================] - 11s 40ms/step - loss: 0.0148 - accuracy: 0.9968 - val_loss: 0.0102 - val_accuracy: 0.9976
Epoch 22/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0048 - accuracy: 0.9995 - val_loss: 0.0073 - val_accuracy: 0.9980
Epoch 23/30
282/282 [==============================] - 12s 43ms/step - loss: 0.0052 - accuracy: 0.9990 - val_loss: 0.0243 - val_accuracy: 0.9920
Epoch 24/30
282/282 [==============================] - 12s 41ms/step - loss: 0.0441 - accuracy: 0.9853 - val_loss: 0.0170 - val_accuracy: 0.9952
Epoch 25/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0070 - accuracy: 0.9987 - val_loss: 0.0096 - val_accuracy: 0.9974
Epoch 26/30
282/282 [==============================] - 11s 41ms/step - loss: 0.0271 - accuracy: 0.9910 - val_loss: 0.0449 - val_accuracy: 0.9837
Epoch 27/30
282/282 [==============================] - 12s 41ms/step - loss: 0.0190 - accuracy: 0.9941 - val_loss: 0.0142 - val_accuracy: 0.9957
Epoch 28/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0119 - accuracy: 0.9967 - val_loss: 0.0114 - val_accuracy: 0.9963
Epoch 29/30
282/282 [==============================] - 12s 41ms/step - loss: 0.0071 - accuracy: 0.9983 - val_loss: 0.0408 - val_accuracy: 0.9855
Epoch 30/30
282/282 [==============================] - 12s 42ms/step - loss: 0.0289 - accuracy: 0.9904 - val_loss: 0.0476 - val_accuracy: 0.9848
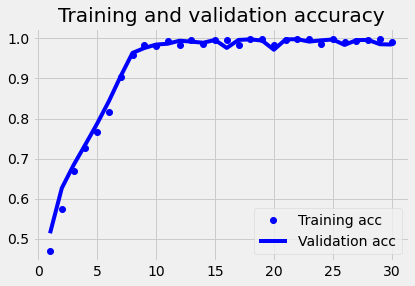
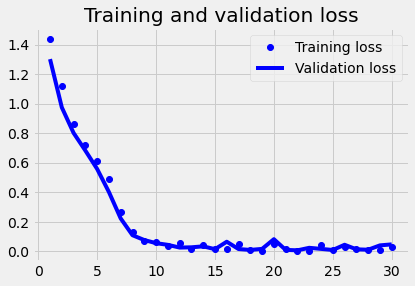
plot1(history3)
Model 4 (Peeky Decoder)#
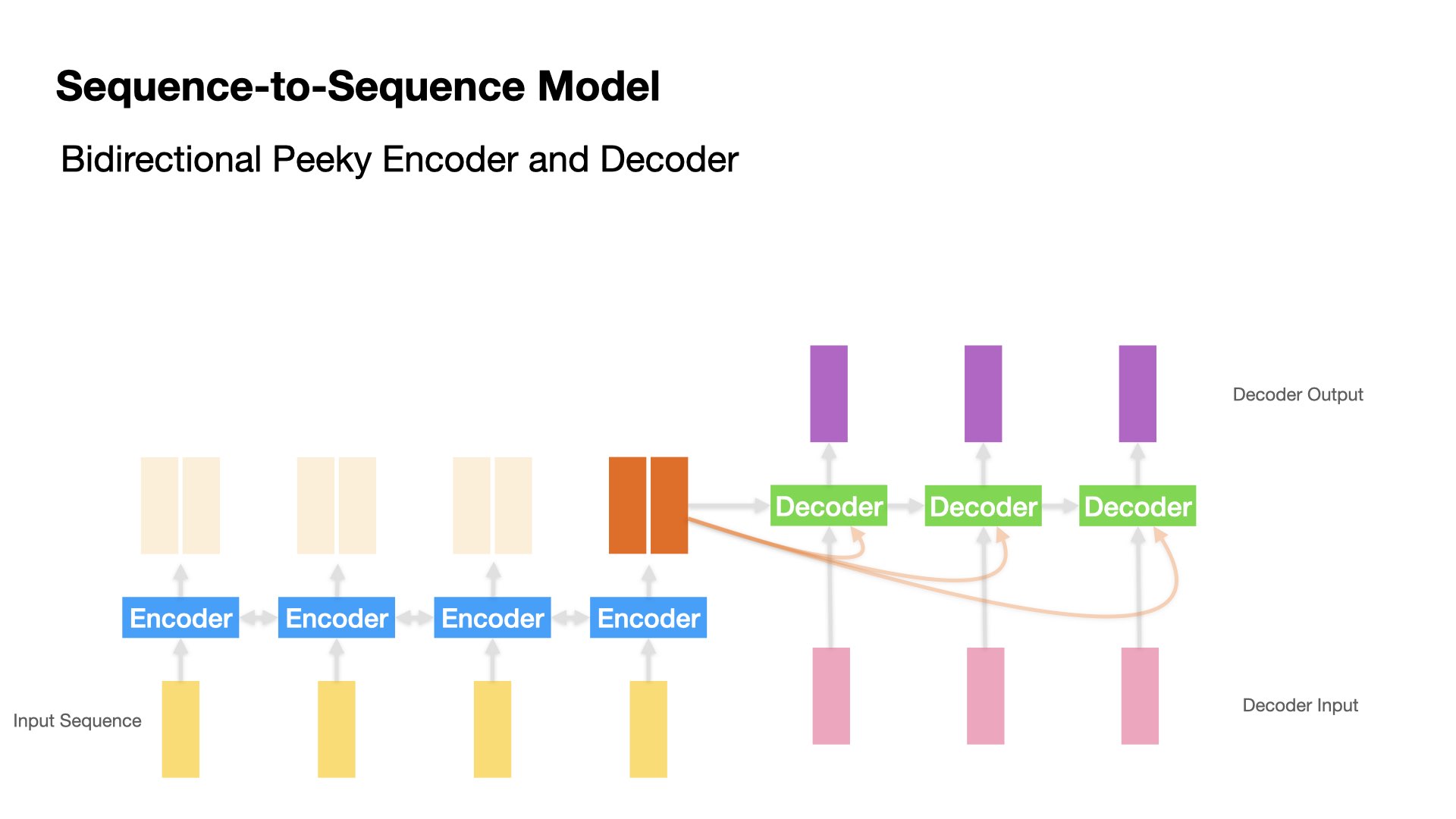
Define Model#
Important highlights:
In the previous models, Decoder only utilizes Encoder’s last hidden state for the decoding of the first output. As for the subsequent decoding time steps, Decoder does not have any information from Encoder.
In Model 4, we implement a peeky Decoder. This strategy allows Decoder to access the information (last hidden state) of the Encoder in every decoding time step.
print(type(target_maxlen))
<class 'numpy.int64'>
# Define Model Inputs
encoder_inputs = Input(shape=(input_maxlen, input_vsize),
name='encoder_inputs')
decoder_inputs = Input(shape=(target_maxlen - 1, target_vsize),
name='decoder_inputs')
# Encoder GRU
encoder_gru = Bidirectional(
GRU(latent_dim,
return_sequences=True,
return_state=True,
name='encoder_gru'))
_, encoder_state_fwd, encoder_state_bwd = encoder_gru(encoder_inputs)
# Combine forward and backward state (last h's) from encoder
encoder_state = Concatenate(axis=-1)([encoder_state_fwd, encoder_state_bwd])
# Repeat the last-hidden-state of Encoder
encoder_state_repeated = RepeatVector(int(target_maxlen) - 1)(encoder_state)
## Concatenate every decoder input with the encoder_state (last hidden state from encoder)
decoder_inputs_peeky = Concatenate(axis=2)(
[decoder_inputs, encoder_state_repeated])
# Decoder GRU
decoder_gru = GRU(latent_dim * 2,
return_sequences=True,
return_state=True,
name='decoder_gru')
decoder_out, _ = decoder_gru(decoder_inputs_peeky, initial_state=encoder_state)
# Dense layer
dense = Dense(target_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_out)
# Full model
full_model4 = Model(inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_pred)
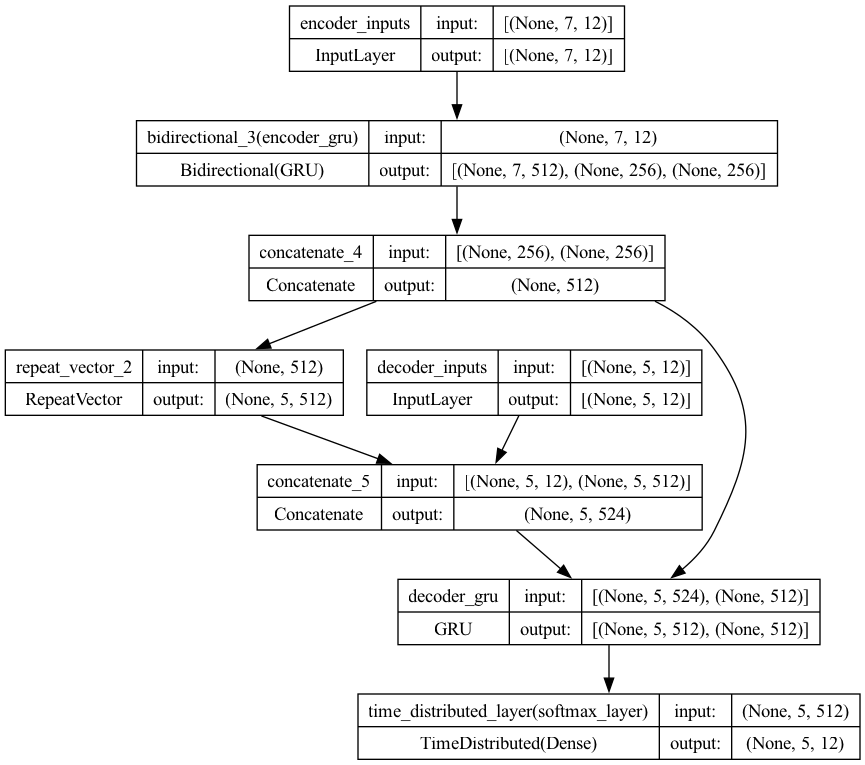
full_model4.summary()
Model: "model_4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
bidirectional_3 (Bidirecti [(None, 7, 512), 414720 ['encoder_inputs[0][0]']
onal) (None, 256),
(None, 256)]
concatenate_4 (Concatenate (None, 512) 0 ['bidirectional_3[0][1]',
) 'bidirectional_3[0][2]']
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
repeat_vector_2 (RepeatVec (None, 5, 512) 0 ['concatenate_4[0][0]']
tor)
concatenate_5 (Concatenate (None, 5, 524) 0 ['decoder_inputs[0][0]',
) 'repeat_vector_2[0][0]']
decoder_gru (GRU) [(None, 5, 512), 1594368 ['concatenate_5[0][0]',
(None, 512)] 'concatenate_4[0][0]']
time_distributed_layer (Ti (None, 5, 12) 6156 ['decoder_gru[0][0]']
meDistributed)
==================================================================================================
Total params: 2015244 (7.69 MB)
Trainable params: 2015244 (7.69 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
plot_model(full_model4, show_shapes=True)
Training#
# Run training
full_model4.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history4 = full_model4.fit([encoder_input_onehot, decoder_input_onehot],
decoder_output_onehot,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Show code cell output
Epoch 1/30
282/282 [==============================] - 15s 49ms/step - loss: 1.4575 - accuracy: 0.4671 - val_loss: 1.3298 - val_accuracy: 0.5042
Epoch 2/30
282/282 [==============================] - 14s 50ms/step - loss: 1.1431 - accuracy: 0.5682 - val_loss: 0.9817 - val_accuracy: 0.6284
Epoch 3/30
282/282 [==============================] - 14s 50ms/step - loss: 0.8454 - accuracy: 0.6782 - val_loss: 0.7315 - val_accuracy: 0.7163
Epoch 4/30
282/282 [==============================] - 14s 49ms/step - loss: 0.6416 - accuracy: 0.7585 - val_loss: 0.5794 - val_accuracy: 0.7819
Epoch 5/30
282/282 [==============================] - 15s 52ms/step - loss: 0.5134 - accuracy: 0.8079 - val_loss: 0.4452 - val_accuracy: 0.8253
Epoch 6/30
282/282 [==============================] - 14s 49ms/step - loss: 0.2866 - accuracy: 0.8976 - val_loss: 0.2098 - val_accuracy: 0.9229
Epoch 7/30
282/282 [==============================] - 14s 48ms/step - loss: 0.1302 - accuracy: 0.9635 - val_loss: 0.0975 - val_accuracy: 0.9742
Epoch 8/30
282/282 [==============================] - 15s 52ms/step - loss: 0.0755 - accuracy: 0.9811 - val_loss: 0.0536 - val_accuracy: 0.9876
Epoch 9/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0632 - accuracy: 0.9826 - val_loss: 0.0853 - val_accuracy: 0.9716
Epoch 10/30
282/282 [==============================] - 14s 50ms/step - loss: 0.0330 - accuracy: 0.9936 - val_loss: 0.0264 - val_accuracy: 0.9943
Epoch 11/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0532 - accuracy: 0.9834 - val_loss: 0.0453 - val_accuracy: 0.9882
Epoch 12/30
282/282 [==============================] - 14s 50ms/step - loss: 0.0177 - accuracy: 0.9973 - val_loss: 0.0142 - val_accuracy: 0.9971
Epoch 13/30
282/282 [==============================] - 14s 51ms/step - loss: 0.0082 - accuracy: 0.9991 - val_loss: 0.0187 - val_accuracy: 0.9950
Epoch 14/30
282/282 [==============================] - 14s 50ms/step - loss: 0.0462 - accuracy: 0.9860 - val_loss: 0.0176 - val_accuracy: 0.9958
Epoch 15/30
282/282 [==============================] - 14s 51ms/step - loss: 0.0098 - accuracy: 0.9984 - val_loss: 0.0138 - val_accuracy: 0.9967
Epoch 16/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0464 - accuracy: 0.9844 - val_loss: 0.0208 - val_accuracy: 0.9943
Epoch 17/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0088 - accuracy: 0.9985 - val_loss: 0.0078 - val_accuracy: 0.9984
Epoch 18/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0039 - accuracy: 0.9995 - val_loss: 0.0075 - val_accuracy: 0.9980
Epoch 19/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0409 - accuracy: 0.9861 - val_loss: 0.0515 - val_accuracy: 0.9824
Epoch 20/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0175 - accuracy: 0.9953 - val_loss: 0.0129 - val_accuracy: 0.9967
Epoch 21/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0343 - accuracy: 0.9888 - val_loss: 0.0282 - val_accuracy: 0.9910
Epoch 22/30
282/282 [==============================] - 14s 49ms/step - loss: 0.0070 - accuracy: 0.9987 - val_loss: 0.0063 - val_accuracy: 0.9986
Epoch 23/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0029 - accuracy: 0.9996 - val_loss: 0.0058 - val_accuracy: 0.9984
Epoch 24/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0031 - accuracy: 0.9994 - val_loss: 0.0153 - val_accuracy: 0.9951
Epoch 25/30
282/282 [==============================] - 13s 47ms/step - loss: 0.0448 - accuracy: 0.9854 - val_loss: 0.0111 - val_accuracy: 0.9968
Epoch 26/30
282/282 [==============================] - 14s 50ms/step - loss: 0.0042 - accuracy: 0.9993 - val_loss: 0.0045 - val_accuracy: 0.9989
Epoch 27/30
282/282 [==============================] - 13s 48ms/step - loss: 0.0019 - accuracy: 0.9998 - val_loss: 0.0093 - val_accuracy: 0.9969
Epoch 28/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0450 - accuracy: 0.9848 - val_loss: 0.0246 - val_accuracy: 0.9920
Epoch 29/30
282/282 [==============================] - 14s 50ms/step - loss: 0.0057 - accuracy: 0.9989 - val_loss: 0.0059 - val_accuracy: 0.9985
Epoch 30/30
282/282 [==============================] - 14s 48ms/step - loss: 0.0023 - accuracy: 0.9997 - val_loss: 0.0055 - val_accuracy: 0.9986
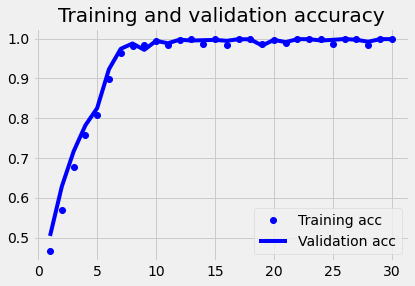
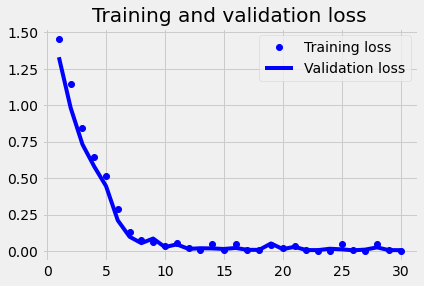
plot1(history4)
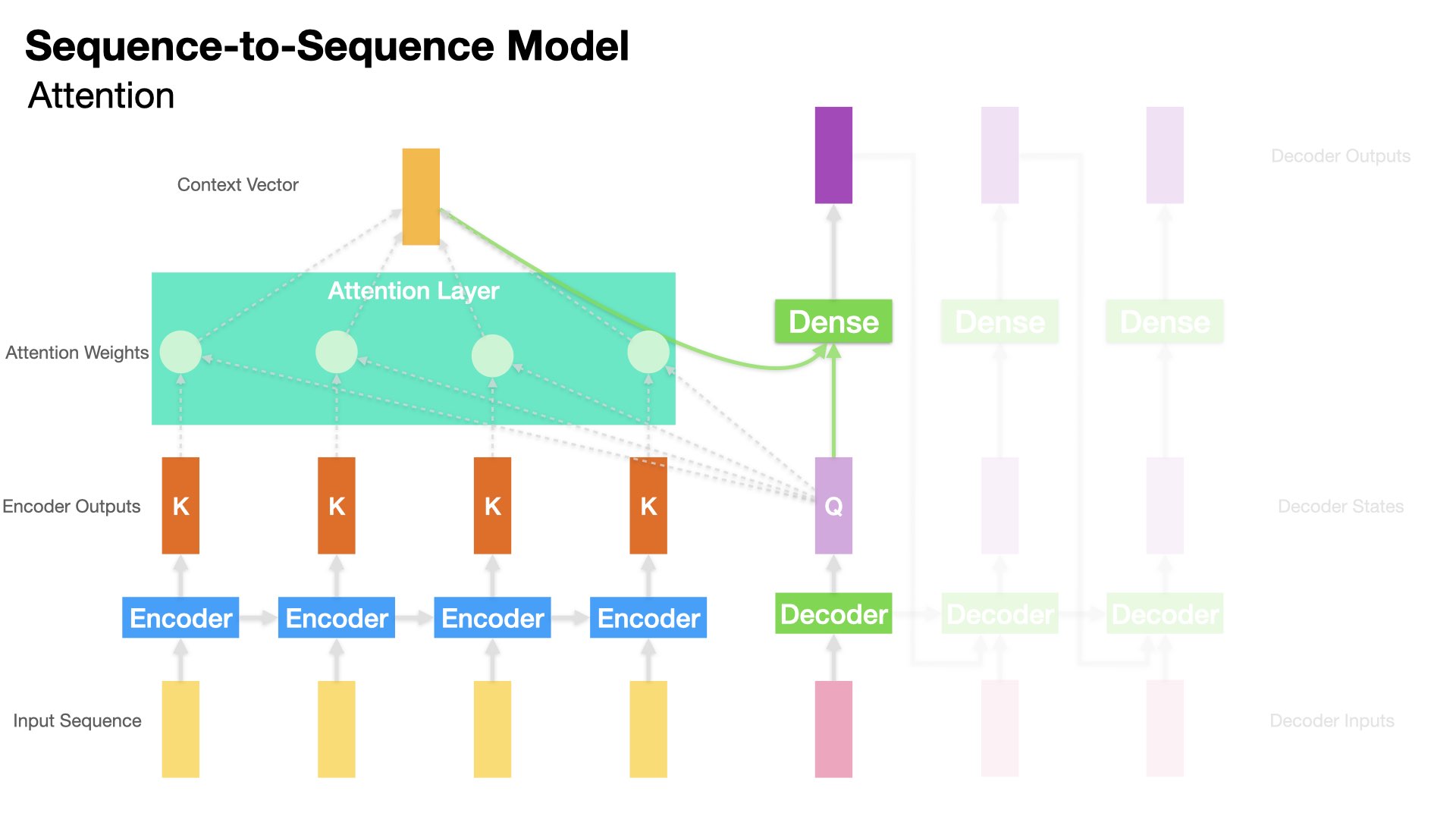
Model 5 (Attention)#
Define Model#
Important highlights:
In Model 5, we implement an Attention-based Decoder.
This Attention mechanism allows the Decoder to use Encoder’s all hidden states.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(input_maxlen, input_vsize),
name='encoder_inputs')
decoder_inputs = Input(shape=(target_maxlen - 1, target_vsize),
name='decoder_inputs')
# Encoder GRU
encoder_gru = GRU(latent_dim,
return_sequences=True,
return_state=True,
name='encoder_gru')
encoder_out, encoder_state = encoder_gru(encoder_inputs)
# Decoder GRU
decoder_gru = GRU(latent_dim,
return_sequences=True,
return_state=True,
name='decoder_gru')
decoder_out, decoder_state = decoder_gru(decoder_inputs,
initial_state=encoder_state)
# Attention layer
attn_layer = Attention(name="attention_layer")
## The inputs for Attention:
## `query`: the `decoder_out` = decoder's hidden state at the decoding step
## `value` & `key`: the `encoder_out` = encoder's all hidden states
## It returns a tensor of shape as `query`, i.e., context tensor
attn_out, attn_weights = attn_layer([decoder_out, encoder_out],
return_attention_scores=True)
# Concat context tensor + decoder_out
decoder_concat_input = Concatenate(
axis=-1, name='concat_layer')([decoder_out, attn_out])
# Dense layer
dense = Dense(target_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_concat_input)
# Full model
full_model5 = Model(inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_pred)
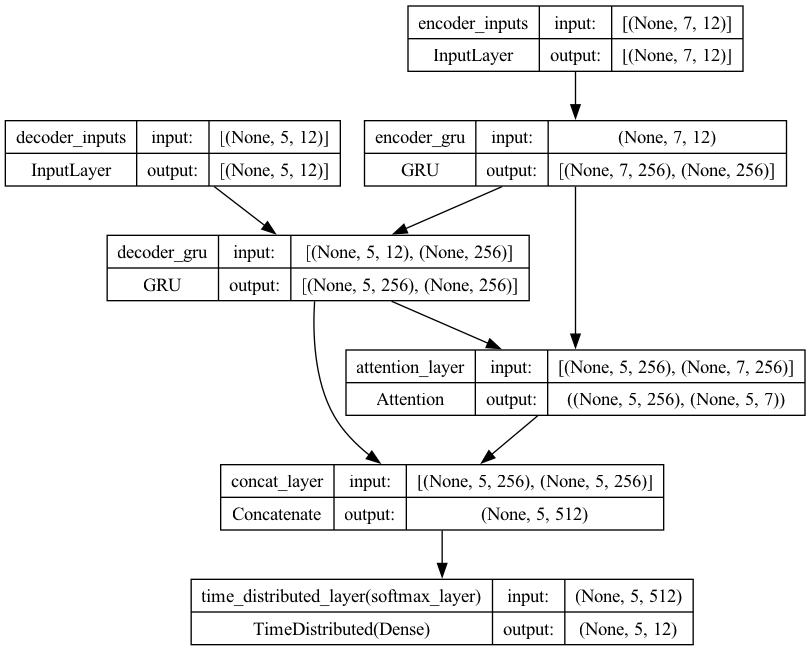
full_model5.summary()
Model: "model_5"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
encoder_gru (GRU) [(None, 7, 256), 207360 ['encoder_inputs[0][0]']
(None, 256)]
decoder_gru (GRU) [(None, 5, 256), 207360 ['decoder_inputs[0][0]',
(None, 256)] 'encoder_gru[0][1]']
attention_layer (Attention ((None, 5, 256), 0 ['decoder_gru[0][0]',
) (None, 5, 7)) 'encoder_gru[0][0]']
concat_layer (Concatenate) (None, 5, 512) 0 ['decoder_gru[0][0]',
'attention_layer[0][0]']
time_distributed_layer (Ti (None, 5, 12) 6156 ['concat_layer[0][0]']
meDistributed)
==================================================================================================
Total params: 420876 (1.61 MB)
Trainable params: 420876 (1.61 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
plot_model(full_model5, show_shapes=True)
Training#
# Run training
full_model5.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history5 = full_model5.fit([encoder_input_onehot, decoder_input_onehot],
decoder_output_onehot,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Show code cell output
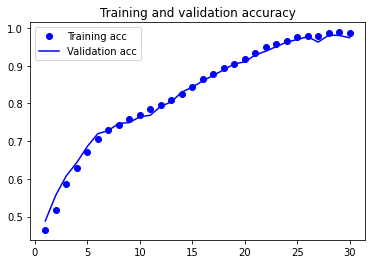
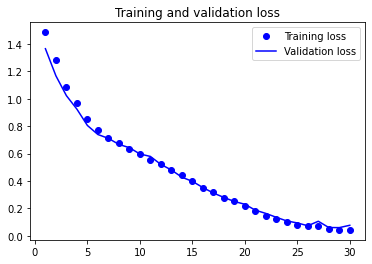
Epoch 1/30
282/282 [==============================] - 10s 32ms/step - loss: 1.4844 - accuracy: 0.4648 - val_loss: 1.3643 - val_accuracy: 0.4886
Epoch 2/30
282/282 [==============================] - 9s 32ms/step - loss: 1.2823 - accuracy: 0.5179 - val_loss: 1.1667 - val_accuracy: 0.5568
Epoch 3/30
282/282 [==============================] - 8s 30ms/step - loss: 1.0821 - accuracy: 0.5861 - val_loss: 1.0221 - val_accuracy: 0.6080
Epoch 4/30
282/282 [==============================] - 9s 30ms/step - loss: 0.9666 - accuracy: 0.6296 - val_loss: 0.9237 - val_accuracy: 0.6430
Epoch 5/30
282/282 [==============================] - 9s 30ms/step - loss: 0.8499 - accuracy: 0.6719 - val_loss: 0.8047 - val_accuracy: 0.6857
Epoch 6/30
282/282 [==============================] - 9s 31ms/step - loss: 0.7705 - accuracy: 0.7048 - val_loss: 0.7387 - val_accuracy: 0.7198
Epoch 7/30
282/282 [==============================] - 9s 33ms/step - loss: 0.7143 - accuracy: 0.7299 - val_loss: 0.7108 - val_accuracy: 0.7278
Epoch 8/30
282/282 [==============================] - 9s 32ms/step - loss: 0.6750 - accuracy: 0.7437 - val_loss: 0.6666 - val_accuracy: 0.7470
Epoch 9/30
282/282 [==============================] - 9s 33ms/step - loss: 0.6342 - accuracy: 0.7589 - val_loss: 0.6429 - val_accuracy: 0.7490
Epoch 10/30
282/282 [==============================] - 9s 31ms/step - loss: 0.5980 - accuracy: 0.7687 - val_loss: 0.5968 - val_accuracy: 0.7645
Epoch 11/30
282/282 [==============================] - 9s 32ms/step - loss: 0.5564 - accuracy: 0.7843 - val_loss: 0.5790 - val_accuracy: 0.7686
Epoch 12/30
282/282 [==============================] - 9s 33ms/step - loss: 0.5242 - accuracy: 0.7949 - val_loss: 0.5206 - val_accuracy: 0.7924
Epoch 13/30
282/282 [==============================] - 10s 34ms/step - loss: 0.4812 - accuracy: 0.8103 - val_loss: 0.4803 - val_accuracy: 0.8039
Epoch 14/30
282/282 [==============================] - 9s 32ms/step - loss: 0.4412 - accuracy: 0.8260 - val_loss: 0.4275 - val_accuracy: 0.8300
Epoch 15/30
282/282 [==============================] - 9s 31ms/step - loss: 0.3969 - accuracy: 0.8440 - val_loss: 0.3974 - val_accuracy: 0.8426
Epoch 16/30
282/282 [==============================] - 9s 32ms/step - loss: 0.3513 - accuracy: 0.8644 - val_loss: 0.3523 - val_accuracy: 0.8597
Epoch 17/30
282/282 [==============================] - 9s 34ms/step - loss: 0.3163 - accuracy: 0.8781 - val_loss: 0.3121 - val_accuracy: 0.8742
Epoch 18/30
282/282 [==============================] - 9s 33ms/step - loss: 0.2777 - accuracy: 0.8944 - val_loss: 0.2802 - val_accuracy: 0.8890
Epoch 19/30
282/282 [==============================] - 9s 33ms/step - loss: 0.2508 - accuracy: 0.9050 - val_loss: 0.2504 - val_accuracy: 0.9047
Epoch 20/30
282/282 [==============================] - 9s 31ms/step - loss: 0.2191 - accuracy: 0.9190 - val_loss: 0.2302 - val_accuracy: 0.9100
Epoch 21/30
282/282 [==============================] - 9s 33ms/step - loss: 0.1837 - accuracy: 0.9333 - val_loss: 0.1870 - val_accuracy: 0.9284
Epoch 22/30
282/282 [==============================] - 9s 33ms/step - loss: 0.1473 - accuracy: 0.9484 - val_loss: 0.1635 - val_accuracy: 0.9383
Epoch 23/30
282/282 [==============================] - 9s 32ms/step - loss: 0.1230 - accuracy: 0.9582 - val_loss: 0.1351 - val_accuracy: 0.9504
Epoch 24/30
282/282 [==============================] - 10s 34ms/step - loss: 0.1030 - accuracy: 0.9662 - val_loss: 0.1084 - val_accuracy: 0.9624
Epoch 25/30
282/282 [==============================] - 9s 33ms/step - loss: 0.0806 - accuracy: 0.9757 - val_loss: 0.0940 - val_accuracy: 0.9693
Epoch 26/30
282/282 [==============================] - 9s 33ms/step - loss: 0.0699 - accuracy: 0.9796 - val_loss: 0.0734 - val_accuracy: 0.9766
Epoch 27/30
282/282 [==============================] - 9s 33ms/step - loss: 0.0691 - accuracy: 0.9785 - val_loss: 0.1062 - val_accuracy: 0.9625
Epoch 28/30
282/282 [==============================] - 10s 36ms/step - loss: 0.0515 - accuracy: 0.9866 - val_loss: 0.0605 - val_accuracy: 0.9807
Epoch 29/30
282/282 [==============================] - 9s 33ms/step - loss: 0.0431 - accuracy: 0.9885 - val_loss: 0.0599 - val_accuracy: 0.9801
Epoch 30/30
282/282 [==============================] - 10s 36ms/step - loss: 0.0449 - accuracy: 0.9872 - val_loss: 0.0770 - val_accuracy: 0.9740
plot_model(full_model5, show_shapes=True)
plot1(history5)
Save Models#
# # Save model
full_model5.save('keras_models/s2s-addition-attention.h5')
/Users/alvinchen/anaconda3/envs/python-notes/lib/python3.9/site-packages/keras/src/engine/training.py:3000: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
Interim Comparison#
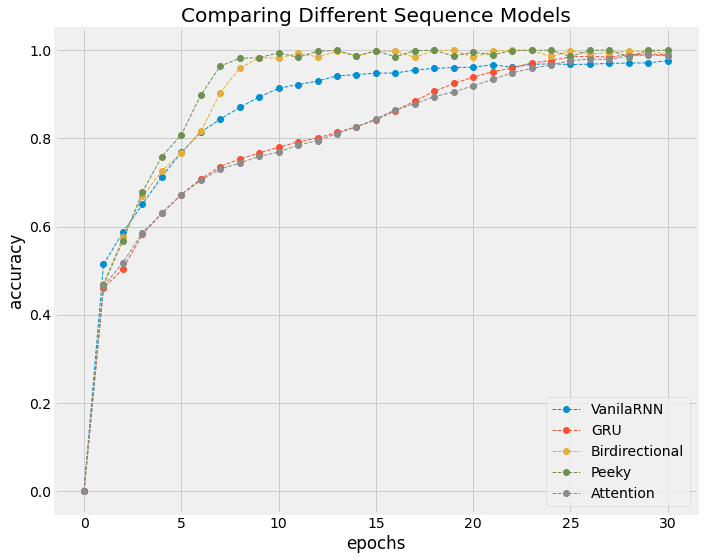
history = [history1, history2, history3, history4, history5]
history = [i.history for i in history]
model_names = ['VanilaRNN', 'GRU', 'Birdirectional', 'Peeky', 'Attention']
# ## Saving all training histories
# import pickle
# with open('keras_models/s2s-attention-addition-history', 'wb') as f:
# pickle.dump(history, f)
# with open('keras_models/s2s-attention-addition-history', 'rb') as f:
# history = pickle.load(f)
acc = [i['accuracy'] for i in history]
val_acc = [i['val_accuracy'] for i in history]
plt.figure(figsize=(10, 8))
plt.style.use('fivethirtyeight')
for i, a in enumerate(acc):
plt.plot(range(len(a) + 1), [0] + a,
linestyle='--',
marker='o',
linewidth=1,
label=model_names[i])
plt.legend()
plt.title('Comparing Different Sequence Models')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.tight_layout()
plt.show()
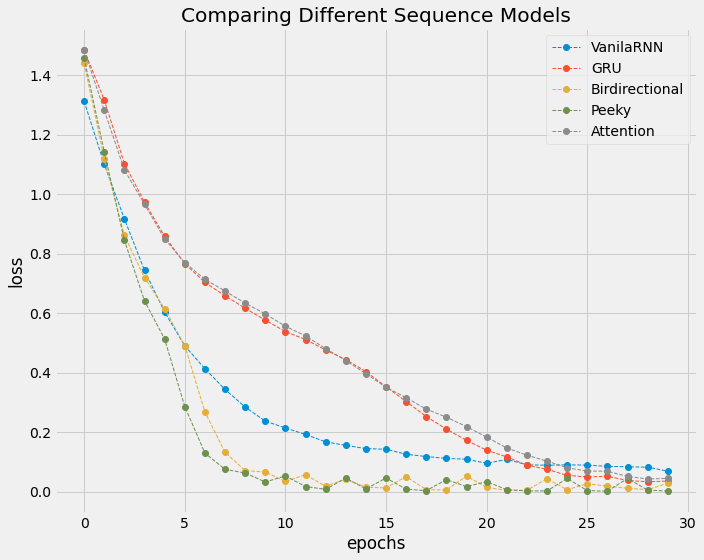
loss = [i['loss'] for i in history]
plt.figure(figsize=(10, 8))
plt.style.use('fivethirtyeight')
for i, a in enumerate(loss):
plt.plot(range(len(a)),
a,
linestyle='--',
marker='o',
linewidth=1,
label=model_names[i])
plt.legend()
plt.title('Comparing Different Sequence Models')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.tight_layout()
plt.show()
Attention Model Analysis#
# ## If the model is loaded via external files
# ## Load the encoder_model, decoder_model this way
# from keras.models import load_model
# full_model5.load_weights('keras_models/s2s-addition-attention.h5')
# full_model5.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
## Let's look at the attention-based model
full_model = full_model5
Inference#
At the inference stage, we use the trained model to decode input sequences.
In decoding, it should be noted that Decoder would decode one word at a time.
We set up Inference-Encoder and Inference-Decoder based on the trained model. We need to identify the right layer from the trained model for the use in inference.
full_model.summary()
Model: "model_5"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer [(None, 7, 12)] 0 []
)
decoder_inputs (InputLayer [(None, 5, 12)] 0 []
)
encoder_gru (GRU) [(None, 7, 256), 207360 ['encoder_inputs[0][0]']
(None, 256)]
decoder_gru (GRU) [(None, 5, 256), 207360 ['decoder_inputs[0][0]',
(None, 256)] 'encoder_gru[0][1]']
attention_layer (Attention ((None, 5, 256), 0 ['decoder_gru[0][0]',
) (None, 5, 7)) 'encoder_gru[0][0]']
concat_layer (Concatenate) (None, 5, 512) 0 ['decoder_gru[0][0]',
'attention_layer[0][0]']
time_distributed_layer (Ti (None, 5, 12) 6156 ['concat_layer[0][0]']
meDistributed)
==================================================================================================
Total params: 420876 (1.61 MB)
Trainable params: 420876 (1.61 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
Inference Encoder#
## Inference-Encoder
encoder_inf_inputs = full_model.input[0]
encoder_inf_out, encoder_inf_state = full_model.layers[2].output
encoder_inf_model = Model(inputs=encoder_inf_inputs,
outputs=[encoder_inf_out, encoder_inf_state])
plot_model(encoder_inf_model)
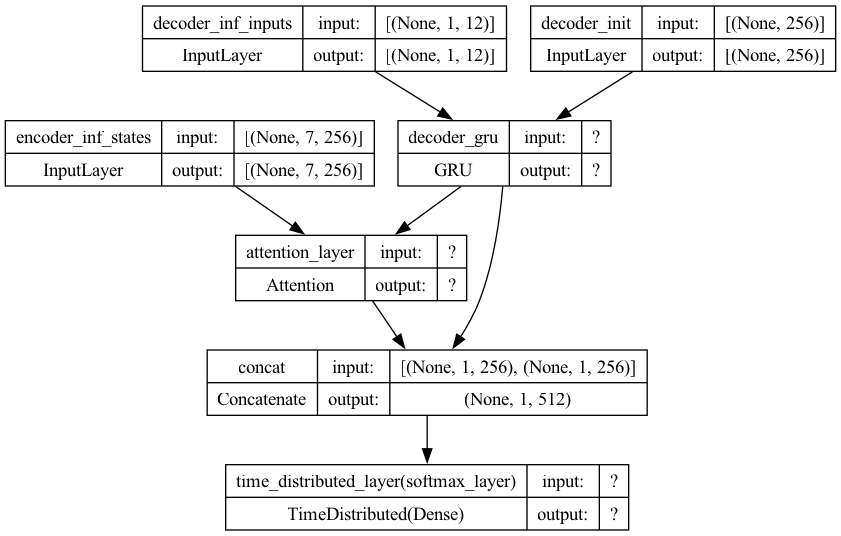
Inference Decoder#
Inference-Decoder requires two inputs:
Encoder’s last hidden state as its initial hidden state
The input token of the target sequence (default start token:
_)
Inference-Attention requires two inputs:
Encoder’s all hidden states as the values and keys
Inference-Decoder’s hidden state as the query
## Inference-Decoder Input (1): The input token from the target sequence
## one token at each time
## the default is the start token '_'
decoder_inf_inputs = Input(
shape=(1, target_vsize),
name='decoder_inf_inputs') ## Initial Decoder's Output Token '_'
## Inference-Decoder Input (2): All hidden states from Inference-Encoder
encoder_inf_states = Input(
shape=(input_maxlen, latent_dim),
name='encoder_inf_states')
## Inference-Decoder Initial Hidden State = Inference-Encoder's last h
decoder_init_state = Input(shape=(latent_dim),
name='decoder_init') ## initial c from encoder
## Inference-Decoder
decoder_inf_gru = full_model.layers[3]
decoder_inf_out, decoder_inf_state = decoder_inf_gru(
decoder_inf_inputs, initial_state=decoder_init_state)
## Inference-Attention
decoder_inf_attention = full_model.layers[4]
attn_inf_out, attn_inf_weights = decoder_inf_attention(
[decoder_inf_out, encoder_inf_states], return_attention_scores=True)
## Inference-Concatenate
decoder_inf_concat = Concatenate(
axis=-1, name='concat')([decoder_inf_out, attn_inf_out])
## Inference-Dense
decoder_inf_timedense = full_model.layers[6]
decoder_inf_pred = decoder_inf_timedense(decoder_inf_concat)
## Inference-Model
decoder_inf_model = Model(
inputs=[encoder_inf_states, decoder_init_state, decoder_inf_inputs],
outputs=[decoder_inf_pred, attn_inf_weights, decoder_inf_state])
plot_model(decoder_inf_model, show_shapes=True)
Decoding Input Sequences#
The Inference-Encoder processes the tokens of input sequences to get (a) all hidden states, and (b) the last hidden state.
The Inference-Decoder uses the Inference-Encoder’s last hidden state as the initial hidden state.
The Inference-Decoder uses the token
_as the initial token of the target sequence for decoding.At the subsequent decoding steps, Inference-Decoder updates its hidden state and the decoded token as inputs for the next-round decoding.
Inference-Decoder is different from the training Decoder in that:
The latter takes in all the correct target sequences (i.e.,
decoder_input_onehot) for teacher forcing.The former takes in one target token, which is predicted by the Inference-Decoder at the previous decoding step.
def decode_sequence(input_seq):
## Initialize target output character "_"
initial_text = '_'
initial_seq = target_tokenizer.texts_to_sequences(initial_text)
test_dec_onehot_seq = np.expand_dims(
to_categorical(initial_seq, num_classes=target_vsize), 1)
## Inference-Encoder processes input sequence
enc_outs, enc_last_state = encoder_inf_model.predict(input_seq)
## Update Inference-Decoder initial hidden state
dec_state = enc_last_state
## Holder for attention weights and decoded texts
attention_weights = []
dec_text = ''
## Inference-Decoder decoding step-by-step
for i in range(target_maxlen):
dec_out, attention, dec_state = decoder_inf_model.predict(
[enc_outs, dec_state, test_dec_onehot_seq])
## Decoded Output (one-hot to integer)
dec_ind = np.argmax(dec_out, axis=-1)[0, 0]
## Stopping Condition
if dec_ind == 0:
break
## Decoded Output (integer to char)
initial_text = dec_index2word[dec_ind]
## Decoded Output for next-round decoding
initial_seq = [dec_ind] #target_tokenizer.texts_to_sequences(initial_text)
test_dec_onehot_seq = np.expand_dims(
to_categorical(initial_seq, num_classes=target_vsize), 1)
## Keep track of attention weights for current decoded output
attention_weights.append((dec_ind, attention))
## Append the predicted char
dec_text += dec_index2word[dec_ind]
return dec_text, attention_weights
## Test sequence-decoding function
## on first 20 training samples
for seq_index in range(20):
decoded_sentence, _ = decode_sequence(
encoder_input_onehot[seq_index:seq_index + 1, :, :])
print('-')
print('Input sentence:', tr_input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
1/1 [==============================] - 0s 122ms/step
1/1 [==============================] - 0s 118ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 27+673
Decoded sentence: 700_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 153+27
Decoded sentence: 180_
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 93+901
Decoded sentence: 994_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 243+678
Decoded sentence: 921_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 269+46
Decoded sentence: 315_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 235+891
Decoded sentence: 1125_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 46+290
Decoded sentence: 336_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 324+947
Decoded sentence: 1271_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 721+49
Decoded sentence: 770_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 535+7
Decoded sentence: 542_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
-
Input sentence: 45+117
Decoded sentence: 162_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 669+174
Decoded sentence: 843_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 904+7
Decoded sentence: 911_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 22+731
Decoded sentence: 753_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 83+742
Decoded sentence: 825_
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
-
Input sentence: 678+983
Decoded sentence: 1661_
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 11ms/step
1/1 [==============================] - 0s 9ms/step
-
Input sentence: 240+42
Decoded sentence: 282_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 18+44
Decoded sentence: 62_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 4+166
Decoded sentence: 170_
1/1 [==============================] - 0s 7ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
-
Input sentence: 731+13
Decoded sentence: 744_
Plotting Attention#
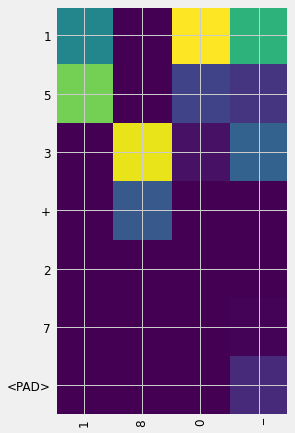
ind = 1
doc_inputs, attention_weights = decode_sequence(encoder_input_onehot[ind:ind +
1, :, :])
mats = []
dec_inputs = []
for dec_ind, attn in attention_weights:
mats.append(attn.reshape(-1))
dec_inputs.append(dec_ind)
attention_mat = np.transpose(np.array(mats))
fig, ax = plt.subplots(figsize=(5, 7))
ax.imshow(attention_mat)
ax.set_xticks(np.arange(attention_mat.shape[1]))
ax.set_yticks(np.arange(attention_mat.shape[0]))
ax.set_xticklabels(
[dec_index2word[inp] if inp != 0 else "<PAD>" for inp in dec_inputs])
ax.set_yticklabels([
enc_index2word[inp] if inp != 0 else "<PAD>"
for inp in encoder_input_sequences[ind]
])
ax.tick_params(labelsize=12)
ax.tick_params(axis='x', labelrotation=90)
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 8ms/step
Evaluation on Testing Data#
Wrap text vectorization in a function.
Vectorize the testing data in the same way as the training data
Texts to sequences
Pad sequences
One-hot encode sequences
def preprocess_data(enc_tokenizer, dec_tokenizer, enc_text, dec_text,
enc_maxlen, dec_maxlen, enc_vsize, dec_vsize):
enc_seq = enc_tokenizer.texts_to_sequences(enc_text)
enc_seq = pad_sequences(enc_seq, padding='post', maxlen=enc_maxlen)
enc_onehot = to_categorical(enc_seq, num_classes=enc_vsize)
dec_seq = dec_tokenizer.texts_to_sequences(dec_text)
dec_seq = pad_sequences(dec_seq, padding='post', maxlen=dec_maxlen)
dec_onehot = to_categorical(dec_seq, num_classes=dec_vsize)
return enc_onehot, dec_onehot
ts_encoder_input_onehot, ts_decoder_target_onehot = preprocess_data(
input_tokenizer, target_tokenizer, ts_input_texts, ts_target_texts,
input_maxlen, target_maxlen, input_vsize, target_vsize)
print(ts_encoder_input_onehot.shape)
print(ts_decoder_target_onehot.shape)
(5000, 7, 12)
(5000, 6, 12)
full_model5.evaluate(
[ts_encoder_input_onehot, ts_decoder_target_onehot[:, :-1, :]],
ts_decoder_target_onehot[:, 1:, :],
batch_size=batch_size,
verbose=2)
40/40 - 1s - loss: 0.0752 - accuracy: 0.9746 - 522ms/epoch - 13ms/step
[0.07519256323575974, 0.9746000170707703]
References#
This unit is based on Chapter 7 of Deep Learning 2用 Python 進行自然語言處理的基礎理論實作 and the original dataset is provided in the book and modified for this unit.