
Word Embeddings#
The state-of-art method of vectorizing texts is to learn the numeric representations of words using deep learning methods.
These deep-learning based numeric representations of linguistic units are commonly referred to as embeddings.
Word embeddings can be learned either along with the target NLP task (e.g., the
Embeddinglayer in RNN Language Model) or via an unsupervised method based on a large number of texts.In this tutorial, we will look at two main algorithms in
word2vecthat allow us to learn the word embeddings in an unsupervised manner from a large collection of texts.
Strengths of word embeddings
They can be learned using unsupervised methods.
They include quite a proportion of the lexical semantics.
They can be learned by batch. We don’t have to process the entire corpus and create the word-by-document matrix for vectorization.
Therefore, it is less likely to run into the memory capacity issue for huge corpora.
Contents
Overview#
What is word2vec?#
Word2vecis one of the most popular techniques to learn word embeddings using a two-layer neural network.The input is a text corpus and the output is a set of word vectors.
Research has shown that these embeddings include rich semantic information of words, which allow us to perform interesting semantic computation (See Mikolov et al’s works in References).
Tip
Word embeddings can be trained using different methods under various objectives.
Downstream Sentiment Classifier:
Objective: In this approach, word embeddings are trained as a byproduct of training a sentiment classifier. The primary goal is to classify text sentiments (e.g., positive or negative).
Training Process: Word embeddings are learned as part of the neural network’s optimization process while training the sentiment classifier. The network learns to represent words in a way that facilitates the sentiment classification task.
Recurrent Language Model (RNN):
Objective: RNNs are used to model sequences of words, predicting the next word in a sequence given previous words. The goal is to capture semantic and syntactic relationships between words.
Training Process: The RNN is trained on a large corpus of text data by predicting the next word in a sequence. Word embeddings are updated during backpropagation to minimize the prediction error.
Word2Vec:
Objective: Word2Vec aims to learn distributed representations of words in a continuous vector space. These embeddings capture semantic similarities between words.
Training Process: Word2Vec uses either the Skip-gram or Continuous Bag of Words (CBOW) architectures. Skip-gram predicts context words given a target word, while CBOW predicts a target word given context words. Word embeddings are learned by optimizing a loss function that measures the likelihood of context words given the target word (or vice versa).
BERT (Bidirectional Encoder Representations from Transformers):
Objective: BERT is designed to generate contextualized word embeddings that capture the meaning of words within the context of a sentence. It excels in various NLP tasks, including question answering, sentiment analysis, and named entity recognition.
Training Process: BERT is pre-trained on large-scale corpora using a masked language model (MLM) and next sentence prediction (NSP) objectives. During pre-training, BERT learns to predict masked words within a sentence and to determine whether two sentences follow each other in a given text.
And of course there are more methods…
Basis of Word Embeddings: Distributional Semantics#
“You shall know a word by the company it keeps” (Firth, 1975).
Word distributions show a considerable amount of lexical semantics.
Construction/Pattern distributions show a considerable amount of the constructional semantics.
Semantics of linguistic units are implicitly or explicitly embedded in their distributions (i.e., occurrences and co-occurrences) in language use (Distributional Semantics).
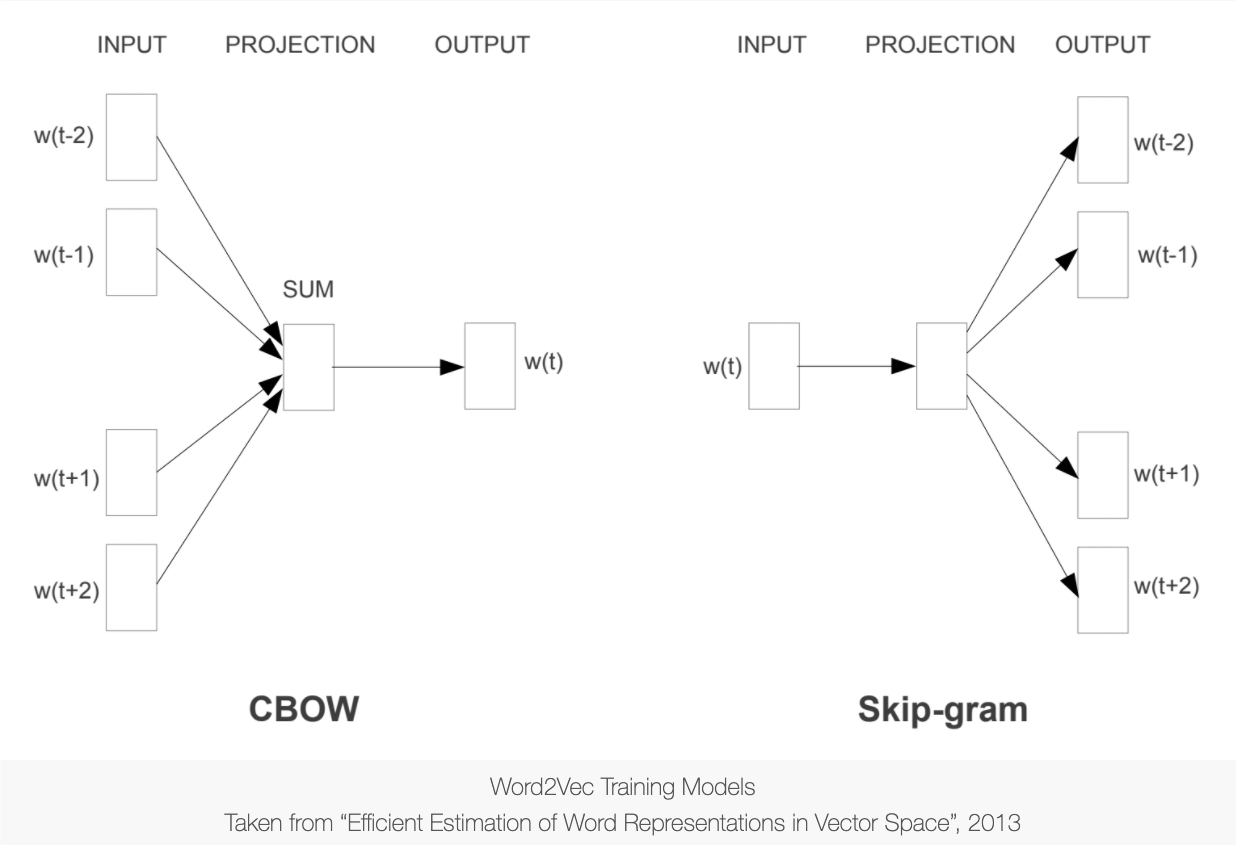
Main training algorithms of word2vec#
Continuous Bag-of-Words (CBOW): The general language modeling task for embeddings training is to learn a model that is capable of using the context words to predict a target word.
Skip-Gram: The general language modeling task for embeddings training is to learn a model that is capable of using a target word to predict its context words.
Other variants of embeddings training:
fasttextfrom FacebookGloVefrom Stanford NLP Group
There are many ways to train work embeddings.
gensim: Simplest and straightforward implementation ofword2vec.Training based on deep learning packages (e.g.,
keras,tensorflow)spacy(It comes with the pre-trained embeddings models, using GloVe.)
See Sarkar (2019), Chapter 4, for more comprehensive reviews.
An Intuitive Understanding of CBOW#


An Intuitive Understanding of Skip-gram#

Import necessary dependencies and settings#
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.dpi'] = 300
pd.options.display.max_colwidth = 200
# # Google Colab Adhoc Setting
# !nvidia-smi
# nltk.download(['gutenberg','punkt','stopwords'])
# !pip show spacy
# !pip install --upgrade spacy
# #!python -m spacy download en_core_web_trf
# !python -m spacy download en_core_web_lg
Sample Corpus: A Naive Example#
corpus = [
'The sky is blue and beautiful.', 'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans",
'I love green eggs, ham, sausages and bacon!',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
]
labels = [
'weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather',
'animals'
]
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'Category': labels})
corpus_df = corpus_df[['Document', 'Category']]
corpus_df
| Document | Category | |
|---|---|---|
| 0 | The sky is blue and beautiful. | weather |
| 1 | Love this blue and beautiful sky! | weather |
| 2 | The quick brown fox jumps over the lazy dog. | animals |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food |
| 4 | I love green eggs, ham, sausages and bacon! | food |
| 5 | The brown fox is quick and the blue dog is lazy! | animals |
| 6 | The sky is very blue and the sky is very beautiful today | weather |
| 7 | The dog is lazy but the brown fox is quick! | animals |
Simple text pre-processing#
Usually for unsupervised
word2veclearning, we don’t really need much text preprocessing.So we keep our preprocessing to the minimum.
Remove only symbols/punctuations, as well as redundant whitespaces.
Perform word tokenization, which would also determine the base units for embeddings learning.
Suggestions#
If you are using
kerasto build the network for embeddings training, please prepare your input corpus data forTokenizer()in the format where each token is delimited by a whitespace.If you are using
gensimto train word embeddings, please tokenize your corpus data first. That is, thegensimonly requires a tokenized version of the corpus and it will learn the word embeddings for you.
wpt = nltk.WordPunctTokenizer()
# stop_words = nltk.corpus.stopwords.words('english')
def preprocess_document(doc):
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I | re.A)
doc = doc.lower()
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
doc = ' '.join(tokens)
return doc
corpus_norm = [preprocess_document(text) for text in corpus]
corpus_tokens = [preprocess_document(text).split(' ') for text in corpus]
print(corpus_norm)
print(corpus_tokens)
['the sky is blue and beautiful', 'love this blue and beautiful sky', 'the quick brown fox jumps over the lazy dog', 'a kings breakfast has sausages ham bacon eggs toast and beans', 'i love green eggs ham sausages and bacon', 'the brown fox is quick and the blue dog is lazy', 'the sky is very blue and the sky is very beautiful today', 'the dog is lazy but the brown fox is quick']
[['the', 'sky', 'is', 'blue', 'and', 'beautiful'], ['love', 'this', 'blue', 'and', 'beautiful', 'sky'], ['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog'], ['a', 'kings', 'breakfast', 'has', 'sausages', 'ham', 'bacon', 'eggs', 'toast', 'and', 'beans'], ['i', 'love', 'green', 'eggs', 'ham', 'sausages', 'and', 'bacon'], ['the', 'brown', 'fox', 'is', 'quick', 'and', 'the', 'blue', 'dog', 'is', 'lazy'], ['the', 'sky', 'is', 'very', 'blue', 'and', 'the', 'sky', 'is', 'very', 'beautiful', 'today'], ['the', 'dog', 'is', 'lazy', 'but', 'the', 'brown', 'fox', 'is', 'quick']]
Training Embeddings Using word2vec#
The expected inputs of
gensim.model.word2vecis token-based corpus object.
%%time
from gensim.models import word2vec
# Set values for various parameters
feature_size = 10
window_context = 5
min_word_count = 1
w2v_model = word2vec.Word2Vec(
corpus_tokens,
vector_size=feature_size, # Word embeddings dimensionality
window=window_context, # Context window size
min_count=min_word_count, # Minimum word count
sg=1, # `1` for skip-gram; otherwise CBOW.
seed = 123, # random seed
workers=1, # number of cores to use
negative = 5, # how many negative samples should be drawn
cbow_mean = 1, # whether to use the average of context word embeddings or sum(concat)
epochs=10000, # number of epochs for the entire corpus
batch_words=10000, # batch size
)
CPU times: user 906 ms, sys: 549 ms, total: 1.45 s
Wall time: 1.23 s
Visualizing Word Embeddings#
Embeddings represent words in multidimensional space.
We can inspect the quality of embeddings using dimensional reduction and visualize words in a 2D plot.
from sklearn.manifold import TSNE
words = w2v_model.wv.index_to_key ## get the word forms of voculary
wvs = w2v_model.wv[words] ## get embeddings of all word forms
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label,
xy=(x + 1, y + 1),
xytext=(0, 0),
textcoords='offset points')

All trained word embeddings are included in
w2v_model.wv.We can extract all word forms in the vocabulary from
w2v_model.wv.index2word.We can easily extract embeddings for any specific words from
w2v_model.wv.
w2v_model.wv.index_to_key[:5]
['the', 'is', 'and', 'sky', 'blue']
[w2v_model.wv[w] for w in w2v_model.wv.index_to_key[:5]]
[array([-1.0949969 , 0.28954926, -1.114496 , -0.42258066, 0.66788393,
-1.3750594 , -0.70987606, 0.11280105, 0.05580178, -0.6932866 ],
dtype=float32),
array([-0.88506925, 0.9598221 , -1.5771676 , -0.1170712 , 0.42075434,
-1.6401567 , -0.19193946, 0.34415627, 0.61294013, -0.7693054 ],
dtype=float32),
array([-0.8441105 , 0.55627626, -0.44809738, -0.00006142, -0.5046599 ,
0.58909607, -0.5197542 , -0.83424497, 0.6392552 , 0.27922842],
dtype=float32),
array([-1.9151906 , 0.02310654, -0.37337798, 1.1486837 , -1.944635 ,
-0.89013064, -0.15339209, 0.06195976, 0.87404585, -0.88589054],
dtype=float32),
array([-0.49760106, 0.33475614, -1.5774511 , 0.16075088, -1.2333795 ,
-0.64314014, -0.9123499 , 0.9150968 , -0.01311138, -0.1773322 ],
dtype=float32)]
From Word Embeddings to Document Embeddings#
With word embeddings, we can compute the average embeddings for the entire document, i.e., the document embeddings.
These document embeddings are also assumed to have included considerable semantic information of the document.
We can for example use them for document classification/clustering.
def average_word_vectors(words, model, vocabulary, num_features):
feature_vector = np.zeros((num_features, ), dtype="float64")
nwords = 0.
for word in words:
if word in vocabulary:
nwords = nwords + 1.
feature_vector = np.add(feature_vector, model.wv[word])
if nwords:
feature_vector = np.divide(feature_vector, nwords)
return feature_vector
def averaged_word_vectorizer(corpus, model, num_features):
vocabulary = set(model.wv.index_to_key)
features = [
average_word_vectors(tokenized_sentence, model, vocabulary,
num_features) for tokenized_sentence in corpus
]
return np.array(features)
w2v_feature_array = averaged_word_vectorizer(corpus=corpus_tokens,
model=w2v_model,
num_features=feature_size)
pd.DataFrame(w2v_feature_array, index=corpus_norm)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| the sky is blue and beautiful | -1.025673 | 0.385626 | -1.049794 | 0.510430 | -0.660862 | -0.868236 | -0.548901 | 0.089492 | 0.567460 | -0.425037 |
| love this blue and beautiful sky | -1.204774 | 0.458085 | -0.833338 | 1.104553 | -0.919012 | -0.179183 | -0.639440 | 0.066505 | 0.541388 | -0.689463 |
| the quick brown fox jumps over the lazy dog | -0.392979 | -0.568204 | -1.745686 | -0.445058 | 0.459197 | -1.097641 | -0.019236 | -0.410119 | 0.395439 | -1.143568 |
| a kings breakfast has sausages ham bacon eggs toast and beans | 0.403289 | 0.133352 | 0.090500 | -0.387340 | -0.589835 | 0.508636 | -1.155621 | -0.795676 | 1.076691 | -1.408591 |
| i love green eggs ham sausages and bacon | -0.260290 | -0.112252 | -0.215950 | 0.544712 | -0.439302 | 1.108033 | -1.191799 | -0.361297 | 0.810694 | -1.341653 |
| the brown fox is quick and the blue dog is lazy | -0.655273 | -0.112480 | -1.412061 | -0.171668 | 0.275225 | -1.128703 | -0.291054 | -0.052113 | 0.424552 | -0.763964 |
| the sky is very blue and the sky is very beautiful today | -1.168732 | 0.556899 | -0.959907 | 0.521333 | -0.719075 | -1.211951 | -0.400086 | 0.057257 | 0.723485 | -0.610505 |
| the dog is lazy but the brown fox is quick | -0.651009 | -0.233851 | -1.622870 | -0.251843 | 0.412877 | -1.314846 | -0.215856 | -0.195488 | 0.437747 | -0.867432 |
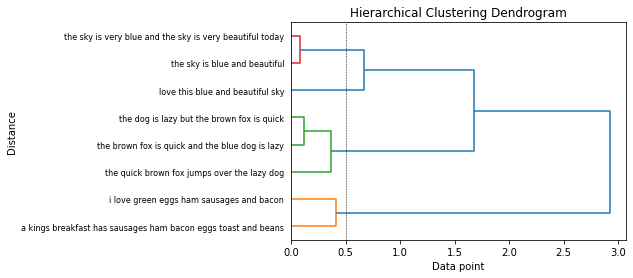
Let’s cluster these documents based on their document embeddings.
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
similarity_doc_matrix = cosine_similarity(w2v_feature_array)
similarity_doc_df = pd.DataFrame(similarity_doc_matrix)
similarity_doc_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 0.901241 | 0.561713 | 0.202711 | 0.330573 | 0.767413 | 0.983230 | 0.708357 |
| 1 | 0.901241 | 1.000000 | 0.313854 | 0.301785 | 0.583546 | 0.509708 | 0.864261 | 0.437844 |
| 2 | 0.561713 | 0.313854 | 1.000000 | 0.208633 | 0.144338 | 0.942269 | 0.561763 | 0.966901 |
| 3 | 0.202711 | 0.301785 | 0.208633 | 1.000000 | 0.822919 | 0.156876 | 0.196729 | 0.138610 |
| 4 | 0.330573 | 0.583546 | 0.144338 | 0.822919 | 1.000000 | 0.145031 | 0.266458 | 0.103276 |
| 5 | 0.767413 | 0.509708 | 0.942269 | 0.156876 | 0.145031 | 1.000000 | 0.766367 | 0.994382 |
| 6 | 0.983230 | 0.864261 | 0.561763 | 0.196729 | 0.266458 | 0.766367 | 1.000000 | 0.711530 |
| 7 | 0.708357 | 0.437844 | 0.966901 | 0.138610 | 0.103276 | 0.994382 | 0.711530 | 1.000000 |
from scipy.cluster.hierarchy import dendrogram, linkage
Z = linkage(similarity_doc_matrix, 'ward')
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
dendrogram(Z,
labels=corpus_norm,
leaf_rotation=0,
leaf_font_size=8,
orientation='right',
color_threshold=0.5)
plt.axvline(x=0.5, c='k', ls='--', lw=0.5)
<matplotlib.lines.Line2D at 0x15b363790>
## Other Clustering Methods
from sklearn.cluster import AffinityPropagation
ap = AffinityPropagation()
ap.fit(w2v_feature_array)
cluster_labels = ap.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
## PCA Plotting
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=0)
pcs = pca.fit_transform(w2v_feature_array)
labels = ap.labels_
categories = list(corpus_df['Category'])
plt.figure(figsize=(8, 6))
for i in range(len(labels)):
label = labels[i]
color = 'orange' if label == 0 else 'blue' if label == 1 else 'green'
annotation_label = categories[i]
x, y = pcs[i]
plt.scatter(x, y, c=color, edgecolors='k')
plt.annotate(annotation_label,
xy=(x + 1e-4, y + 1e-3),
xytext=(0, 0),
textcoords='offset points')

Using Pre-trained Embeddings: GloVe in spacy#
import spacy
nlp = spacy.load('en_core_web_sm',disable=['parse','entity'])
total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)
Total word vectors: 0
print(spacy.__version__)
3.5.4
Visualize GloVe word embeddings#
Let’s extract the GloVe pretrained embeddings for all the words in our simple corpus.
And we visualize their embeddings in a 2D plot via dimensional reduction.
Warning
When using pre-trained embeddings, there are two important things:
Be very careful of the tokenization methods used in your text preprocessing. If you use a very different word tokenization method, you may find a lot of unknown words that are not included in the pretrained model.
Always check the proportion of the unknown words when vectorizing your corpus texts with pre-trained embeddings.
# get vocab of the corpus
unique_words = set(sum(corpus_tokens,[]))
# extract pre-trained embeddings of all words
word_glove_vectors = np.array([nlp(word).vector for word in unique_words])
pd.DataFrame(word_glove_vectors, index=list(unique_words))
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| eggs | -1.297392 | 1.158260 | -0.816274 | 1.056100 | 0.815064 | -0.748527 | 1.410166 | 0.772055 | 0.981865 | -0.946172 | ... | -0.929507 | 0.640614 | -0.525295 | 0.420553 | -1.224993 | -0.113389 | 1.944303 | 0.202356 | 0.006850 | 0.784401 |
| beautiful | -1.981197 | -1.085511 | -0.495878 | 0.908991 | -0.765072 | 0.368210 | 0.533828 | 0.598339 | 0.157835 | -1.119861 | ... | 0.119182 | 0.332911 | -1.044088 | 0.527054 | 0.264596 | 0.141068 | 1.396086 | 0.909145 | -0.375545 | 0.587217 |
| a | 0.445624 | 0.040820 | -1.044201 | 0.977903 | 0.343366 | 0.434702 | -0.532973 | 0.914784 | 0.640789 | 1.057252 | ... | 0.890635 | -0.494442 | -0.669522 | 0.849890 | -0.475511 | -0.044901 | -1.019666 | -0.434723 | -0.855158 | -0.277925 |
| sausages | -1.551236 | 1.381497 | -0.690470 | 0.578089 | 1.516763 | -0.319808 | 1.896638 | 0.390757 | 0.864699 | -0.613225 | ... | -0.803906 | -0.313376 | -0.481047 | -0.324135 | -1.256292 | 0.100420 | 1.357908 | 0.602705 | 0.325189 | 0.501014 |
| sky | -1.052380 | -0.623966 | -1.247646 | 0.173334 | -0.280415 | 0.423770 | 1.136191 | 1.594746 | -0.112143 | 0.024372 | ... | -0.081687 | -0.557614 | -1.442796 | 1.067169 | -0.304729 | -0.230831 | 1.200994 | 0.827422 | 0.558651 | 1.421518 |
| jumps | -0.809289 | 1.028575 | 0.142154 | 1.195198 | -0.892427 | -0.613777 | 1.158633 | 0.491403 | 0.826156 | -0.908024 | ... | -0.968901 | 0.572921 | 0.224079 | -0.167506 | 0.545909 | 0.819458 | -0.053826 | 0.179755 | -0.520523 | 1.177554 |
| bacon | -1.484836 | -0.526327 | -0.839054 | -0.176428 | 0.484847 | 0.140633 | 0.748910 | 1.224433 | 0.124089 | 0.034701 | ... | 0.007322 | -0.371588 | -1.953568 | 1.160531 | -0.463557 | -0.028599 | 1.411305 | 0.775448 | 0.868626 | 1.153851 |
| i | -1.993811 | -0.266061 | -0.210171 | -0.306936 | -0.040057 | -0.104719 | 2.012425 | 0.467140 | 0.367587 | -0.688097 | ... | -0.367412 | -0.188884 | 0.805614 | 0.037096 | 1.218038 | -0.012631 | 0.766386 | -0.338247 | -0.670582 | 1.593813 |
| quick | -0.808211 | -1.721902 | -0.849621 | -0.323724 | -0.733217 | -0.200044 | 0.316565 | 1.306867 | -0.375950 | -0.764119 | ... | -0.344666 | 0.631241 | -0.250259 | 1.216615 | 1.283587 | 0.036267 | 1.192510 | 1.531458 | -1.331324 | 0.637828 |
| dog | -1.680668 | -1.266374 | -0.712555 | 0.221439 | 0.285816 | 0.239243 | 1.299264 | 1.068364 | -0.166650 | -0.593021 | ... | 0.311112 | -0.469987 | -2.129951 | 1.172860 | -1.284266 | -1.117903 | 1.596463 | 0.511931 | 0.220327 | 1.620028 |
| beans | -1.068852 | 1.167118 | -0.484017 | 0.891425 | 1.399791 | -0.477653 | 1.326169 | 0.747473 | 1.092705 | -0.092148 | ... | -1.138134 | -0.107772 | 0.300590 | 0.501320 | -0.806155 | 0.883533 | 1.994725 | 0.569794 | 0.480497 | 0.148873 |
| lazy | -1.349924 | -1.008392 | -0.377253 | -0.534368 | -0.737286 | 0.438626 | 0.275777 | 0.426540 | -0.384914 | -1.091949 | ... | -0.174180 | 0.558309 | -0.641799 | 1.153933 | 1.125221 | 0.256873 | 0.825007 | 1.489886 | 0.163207 | 0.548744 |
| has | -0.816400 | -0.586754 | -1.149105 | 0.388758 | 0.561820 | 1.324211 | 0.726742 | 0.121942 | 0.886533 | 1.260011 | ... | -1.520276 | 0.172569 | 1.202618 | -0.608210 | -0.100047 | -0.234273 | 0.720248 | 0.204601 | -1.233299 | -0.132075 |
| ham | -0.952584 | -0.859383 | -0.512346 | -0.397440 | -0.272660 | 0.141939 | -0.206824 | 1.338140 | 0.240586 | -0.777376 | ... | 0.466846 | -0.185779 | -1.645292 | 0.239415 | -0.960014 | 0.846002 | 0.562277 | 0.380782 | 0.955904 | 0.844923 |
| today | -0.818719 | -1.463490 | -0.576256 | -1.777408 | -0.816109 | -1.116335 | -0.125725 | 2.077141 | -0.168442 | -0.217695 | ... | 2.928388 | 1.940016 | -0.906605 | 1.027404 | -1.825106 | 0.496492 | 0.637674 | 0.839445 | 0.745934 | -0.141063 |
| toast | -0.511126 | -1.450968 | -0.677772 | -0.366755 | -0.637132 | -0.223210 | -0.398685 | 1.043328 | 0.483847 | -0.570177 | ... | 0.803359 | 0.164432 | -1.173489 | 0.853854 | -1.316678 | 0.347120 | 0.963565 | 1.096257 | 0.741654 | 0.422103 |
| very | 0.179364 | -0.142232 | -1.542073 | -0.390681 | 0.221738 | -0.352646 | 1.095366 | 0.634386 | 0.249361 | -0.077876 | ... | 0.737402 | -0.546005 | -0.673379 | 0.705251 | 1.651500 | -0.794369 | 0.578590 | 1.237230 | -1.189028 | -1.221863 |
| and | -0.749836 | -0.864052 | -1.123196 | 0.288821 | -0.685820 | 2.549688 | -0.118120 | 0.279010 | -0.123277 | 1.001370 | ... | 0.707131 | 1.457647 | -0.714177 | -0.498196 | -0.281577 | 0.980062 | -0.475814 | 0.466685 | -0.855074 | -0.479473 |
| the | 0.171047 | -0.199269 | -0.745276 | 0.178762 | -0.363477 | 0.347444 | -1.003620 | 0.021227 | 0.238515 | 1.270073 | ... | 1.609505 | -0.592565 | -0.546699 | 1.053596 | -0.962386 | 0.352104 | -0.288018 | -0.706722 | -0.514224 | -0.020832 |
| green | -1.185332 | -1.172187 | -0.342883 | 0.147804 | -0.441741 | -0.421923 | -0.664020 | 0.015956 | 0.544560 | -1.225485 | ... | 0.885219 | 1.026413 | -0.446825 | 1.726705 | 0.148405 | 0.407081 | 0.922681 | 1.281653 | -1.018726 | 0.706706 |
| brown | -0.876515 | -1.404033 | -0.920570 | 0.893428 | 0.632113 | -0.000901 | -0.270705 | 1.450482 | 1.094554 | -1.343019 | ... | 0.900336 | 0.143640 | -0.650320 | 0.453211 | -0.052952 | 0.508944 | 1.487840 | 0.490526 | 0.128303 | 1.059052 |
| blue | -1.241533 | -1.403888 | -0.906116 | 0.713846 | 0.730656 | -0.184642 | -0.275212 | 1.047278 | 0.211378 | -0.573579 | ... | 0.483817 | 1.536532 | -0.535280 | 0.327238 | -0.723836 | 0.332048 | 0.652643 | 1.130325 | -0.458007 | 0.830703 |
| fox | -1.063213 | -1.183251 | 0.301696 | 0.807676 | -0.038768 | 0.154243 | 0.943619 | 1.364023 | 0.090330 | -0.779429 | ... | -0.005095 | -0.514685 | -1.359398 | 1.482487 | -0.727252 | -0.679084 | 1.143468 | 0.792078 | 0.315267 | 1.307671 |
| is | -0.686803 | 1.201411 | -0.365061 | 0.023410 | -0.911158 | -0.636755 | 0.201880 | 0.615606 | 1.178941 | 0.296924 | ... | -0.182100 | 0.782834 | -0.252753 | -0.966379 | 0.038495 | -0.473968 | -0.116784 | -0.699781 | -0.844511 | 0.400906 |
| but | -0.617007 | -1.335470 | -1.274921 | 0.456699 | 0.492685 | 0.975719 | -0.089738 | 0.473519 | 0.433252 | 1.396277 | ... | 0.546477 | 0.888823 | -0.181895 | -0.218617 | -0.720275 | 0.372221 | -0.464548 | 0.677568 | -1.169354 | -0.445014 |
| this | -0.923892 | -0.346465 | -0.935396 | 0.642046 | 0.873360 | 0.107631 | 1.653424 | 0.126784 | -0.441882 | 0.085917 | ... | 1.577924 | 0.150236 | 0.281095 | -0.267720 | -0.851461 | -0.777931 | 0.251027 | -0.263745 | -0.962156 | 0.877665 |
| over | -0.440351 | -0.957340 | -0.288660 | -0.784095 | -0.453102 | -0.260627 | -0.156899 | 1.161451 | 0.216041 | -0.119296 | ... | 0.818817 | -0.112223 | 0.002978 | 0.198639 | -0.664964 | 1.044688 | -0.332886 | 1.113894 | -0.737988 | -1.248392 |
| kings | -0.871058 | 1.877413 | -0.446523 | 0.939120 | 1.882271 | -0.894365 | 1.959913 | 0.237614 | 1.054103 | -0.776251 | ... | -0.663307 | 0.486514 | 0.542900 | -0.114815 | -0.053794 | 0.501748 | 1.782944 | 0.394344 | -0.109745 | 0.131947 |
| love | -2.062335 | -0.436482 | -0.819275 | 0.988686 | 0.089922 | -0.325258 | 1.581294 | 1.765489 | 0.431824 | -0.991082 | ... | -0.014793 | -0.220141 | -1.260573 | -0.073471 | -0.762526 | -0.953943 | 0.655179 | 1.407103 | 0.392512 | 0.337918 |
| breakfast | -0.829254 | -0.406226 | -0.967018 | 0.675861 | -0.075334 | 0.707547 | 0.685737 | 2.209723 | 0.268043 | -0.333843 | ... | -0.162341 | -1.037519 | -1.418477 | 0.797511 | -0.989848 | -0.342162 | 1.093951 | 0.917619 | 0.077850 | 0.654152 |
30 rows × 96 columns
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=1)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_glove_vectors)
labels = unique_words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label,
xy=(x + 1, y + 1),
xytext=(0, 0),
textcoords='offset points')

It is clear to see that when embeddings are trained based on a larger corpus, they reflect more lexical semantic contents.
Semantically similar words are indeed closer to each other in the 2D plot.
We can of course perform the document-level clustering again using the GloVe embeddings.
The good thing about
spacyis that it can compute the document average embeddings automatically.
doc_glove_vectors = np.array([nlp(str(doc)).vector for doc in corpus_norm])
import sklearn
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=0)
km.fit_transform(doc_glove_vectors)
cluster_labels = km.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
/Users/alvinchen/anaconda3/envs/python-notes/lib/python3.9/site-packages/sklearn/cluster/_kmeans.py:1412: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
super()._check_params_vs_input(X, default_n_init=10)
| Document | Category | ClusterLabel | |
|---|---|---|---|
| 0 | The sky is blue and beautiful. | weather | 1 |
| 1 | Love this blue and beautiful sky! | weather | 2 |
| 2 | The quick brown fox jumps over the lazy dog. | animals | 1 |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food | 0 |
| 4 | I love green eggs, ham, sausages and bacon! | food | 0 |
| 5 | The brown fox is quick and the blue dog is lazy! | animals | 1 |
| 6 | The sky is very blue and the sky is very beautiful today | weather | 1 |
| 7 | The dog is lazy but the brown fox is quick! | animals | 1 |
fasttext#
This section shows a quick example how to train word embeddings based on the
nltk.corpus.brownusing another algorithm, i.e.,fasttext.The FastText model was introduced by Facebook in 2016 as an improved and extended version of the
word2vec(See Bojanowski et al [2017] in References below).We will focus more on the implementation. Please see the Bojanowski et al (2017) as well as Sarkar (2019) Chapter 4 for more comprehensive descriptions of the method.
Pretrained FastText Embeddings are available here.
from gensim.models.fasttext import FastText
from nltk.corpus import brown
brown_tokens = [brown.words(fileids=f) for f in brown.fileids()]
%%time
# Set values for various parameters
feature_size = 128 # Word vector dimensionality
window_context = 5 # Context window size
min_word_count = 5 # Minimum word count
ft_model = FastText(brown_tokens,
vector_size=feature_size,
window=window_context,
min_count=min_word_count,
sg=1,
epochs=50)
CPU times: user 5min 34s, sys: 5.79 s, total: 5min 39s
Wall time: 2min 2s
Tip
Please check the documentation for more detailed use:
help(FastText)
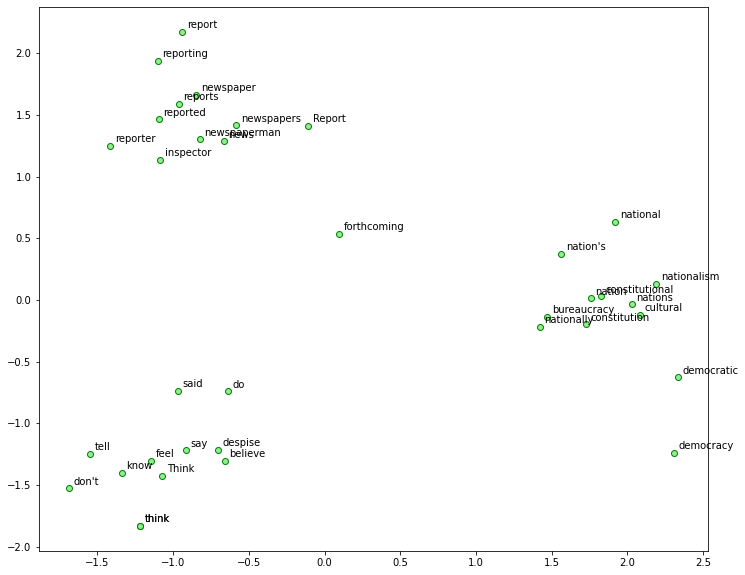
We can use the trained embeddings model to identify words that are similar to a set of seed words.
And then we plot all these words (i.e., the seed words and their semantic neighbors) in one 2D plot based on the dimensional reduction of their embeddings.
# view similar words based on gensim's model
similar_words = {
search_term:
[item[0] for item in ft_model.wv.most_similar([search_term], topn=5)]
for search_term in
['think', 'say','news', 'report','nation', 'democracy']
}
similar_words
{'think': ['know', 'Think', 'tell', "don't", 'feel'],
'say': ['said', 'think', 'do', 'believe', 'despise'],
'news': ['newspapers',
'newspaperman',
'newspaper',
'forthcoming',
'inspector'],
'report': ['reports', 'reporting', 'Report', 'reporter', 'reported'],
'nation': ['nations', 'national', 'nationalism', "nation's", 'nationally'],
'democracy': ['democratic',
'cultural',
'constitutional',
'constitution',
'bureaucracy']}
from sklearn.decomposition import PCA
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = ft_model.wv[words]
pca = PCA(n_components=2)
np.set_printoptions(suppress=True)
P = pca.fit_transform(wvs)
labels = words
plt.figure(figsize=(12, 10))
plt.scatter(P[:, 0], P[:, 1], c='lightgreen', edgecolors='g')
for label, x, y in zip(labels, P[:, 0], P[:, 1]):
plt.annotate(label,
xy=(x + 0.03, y + 0.03),
xytext=(0, 0),
textcoords='offset points')
ft_model.wv['democracy']
array([-0.2523766 , 1.2344824 , 0.28590804, -0.18874285, -0.12484555,
-0.49433994, 0.1602066 , -0.31401044, 0.22249952, -0.16373059,
0.5416111 , 0.17930526, 0.33985358, 0.33994997, -0.27761728,
0.295529 , 0.30032286, -0.16337612, 0.2726979 , 0.286383 ,
0.05036034, -0.4099072 , 1.1245147 , -0.43144313, -0.12164368,
-0.43757993, 0.3907696 , -0.506607 , 0.8151896 , -0.1673889 ,
-0.12556757, 0.4687364 , 0.38069835, 0.29146397, 0.17975552,
0.00345719, 0.3428171 , -0.5179925 , 0.25784668, -0.2876231 ,
0.2736586 , -0.32872424, -0.41551793, -0.39329693, 0.16495731,
0.22620523, 0.22976732, -0.30155176, 0.12755516, -0.05715791,
-0.47991446, 0.6938182 , -0.69235647, -0.27857274, 0.20222324,
-0.5334721 , 0.5623266 , 0.2074901 , -0.0281765 , -0.15348567,
1.3333222 , 0.5020892 , -0.2768525 , 0.11414671, 0.194682 ,
-0.33986622, 0.47148588, -0.3239075 , -0.31997842, 0.41093224,
0.511632 , -0.0720844 , -0.13437022, -0.58273226, 0.36699748,
-0.10058013, -0.41690606, -0.12419936, 0.3415619 , 0.05605935,
-0.31064925, -0.09939189, -0.20340547, 0.7773749 , 0.3970421 ,
0.00630904, -0.29208088, 0.06216234, -0.01027498, 0.10407776,
0.63741744, 0.05946476, 0.23245631, 0.09461077, 0.44289067,
0.40805987, -0.08794071, 0.02890253, 0.3359511 , -0.28606507,
-0.7213146 , 0.6503062 , 0.36324272, 0.3368714 , -0.01722197,
0.25369242, 0.44865412, -0.03442893, -0.644235 , 0.28318068,
-0.7213056 , 0.02290851, 0.22658262, 0.03600961, -0.38349828,
0.01788636, -0.01218169, 0.7510187 , -0.40153882, -0.21668746,
-0.04060327, 0.5902806 , -0.05519979, -0.20750351, 0.3325783 ,
0.11138923, -0.12826458, -0.91107947], dtype=float32)
print(ft_model.wv.similarity(w1='taiwan', w2='freedom'))
print(ft_model.wv.similarity(w1='china', w2='freedom'))
0.2915468
0.1772014
Wrap-up#
Two fundamental deep-learning-based models of word representation learning: CBOW and Skip-Gram.
From word embeddings to document embeddings
More advanced representation learning models: GloVe and FastText.
What is more challenging is how to assess the quality of the learned representations (embeddings). Usually embedding models can be evaluated based on their performance on semantics related tasks, such as word similarity and analogy. For those who are interested, you can start with the following two papers on Chinese embeddings:
Chi-Yen Chen, Wei-Yun Ma. 2018. “Word Embedding Evaluation Datasets and Wikipedia Title Embedding for Chinese,” Language Resources and Evaluation Conference.
Chi-Yen Chen, Wei-Yun Ma. 2017. “Embedding Wikipedia Title Based on Its Wikipedia Text and Categories,” International Conference on Asian Language Processing.
From word embeddings, we can extend this idea of vectorized representation to sentence or document embeddings. Please check Sentence Transformers for more information.
References#
Sarkar (2020) Ch 4 Feature Engineering for Text Representation
Major Readings:
Harris,Zellig. 1956. Distributional structure.
Bengio, Yoshuan, et. al. 2003. A Neural Probabilistic Language Model.
Collobert, Ronana and Jason Weston. 2008. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning.
Schwenk, Holger. 2007.Continuous space language models.
Mikolov, Tomas, et al. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Mikolov, Tomas, et al. 2013. Distributed representations of words and phrases and their compositionally. Advances in neural information processing systems. 2013.
Baroni, Marco, et. al. 2014. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. ACL(1).
Pennington, Jeffrey, et al. 2014. GloVe: Global Vectors for Word Representation. EMNLP. Vol. 14.
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135-146.
GloVe Project Official Website: You can download their pre-trained GloVe models.
FastText Project Website: You can download the English pre-trained FastText models.