
Deep Learning: A Simple Example#
Let’s get back to the Name Gender Classifier.
Contents
Loading Packages#
## Packages Dependencies
import os
import shutil
import numpy as np
import nltk
from nltk.corpus import names
import random
from sklearn.model_selection import train_test_split
from sklearn.manifold import TSNE
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.dpi'] = 150
from lime.lime_text import LimeTextExplainer
import tensorflow
import tensorflow.keras as keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
import keras_tuner
Warning
This tutorial is still based on the legacy keras 2 (tensorflow <= 2.15) Please check TensorFlow + Keras 2 backwards compatibility for more information.
## checking versions
print(tensorflow.__version__)
2.13.0
Data#
labeled_names = ([(name, 1) for name in names.words('male.txt')] +
[(name, 0) for name in names.words('female.txt')])
random.shuffle(labeled_names)
Train-Test Split#
train_set, test_set = train_test_split(labeled_names,
test_size=0.2,
random_state=42)
print(len(train_set), len(test_set))
6355 1589
names = [n for (n, l) in train_set] ## X
labels = [l for (n, l) in train_set] ## y
type(names)
list
len(names)
6355
Tokenizer#
keras.preprocessing.text.Tokenizeris a very useful tokenizer for text processing in deep learning.Tokenizerassumes that the word tokens of the input texts have been delimited by whitespaces.Tokenizerprovides the following functions:It will first create a dictionary for the entire corpus (a mapping of each word token and its unique integer index index) (
Tokenizer.fit_on_text())It can then use the corpus dictionary to convert words in each corpus text into integer sequences (
Tokenizer.texts_to_sequences())The dictionary is in
Tokenizer.word_index
Notes on
Tokenizer:By default, the token index 0 is reserved for padding token.
If
oov_tokenis specified, it is represented by token index 1. (Default:oov_token=False)Specify
num_words=NforTokenizerto include only top N words in converting texts to sequences.Tokenizerwill automatically remove punctuations.Tokenizeruse the whitespace as word-token delimiter.If every character is treated as a token, specify
char_level=True.Please read
Tokenizerdocumentation very carefully. Very important!!
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(names) ## similar to CountVectorizer.fit_transform()
Vocabulary#
After we Tokenizer.fit_on_texts(), we can take a look at the corpus dictionary, i.e., the mapping of the tokens and their unique integer indices.
## Checking dictionary (mapping of tokens vs. integers)
tokenizer.word_index
{'a': 1,
'e': 2,
'i': 3,
'n': 4,
'r': 5,
'l': 6,
'o': 7,
't': 8,
's': 9,
'd': 10,
'y': 11,
'm': 12,
'h': 13,
'c': 14,
'b': 15,
'u': 16,
'g': 17,
'k': 18,
'j': 19,
'v': 20,
'f': 21,
'p': 22,
'w': 23,
'z': 24,
'x': 25,
'q': 26,
'-': 27,
' ': 28,
"'": 29}
## Intuition for the vocabulary size
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d' % vocab_size)
Vocabulary Size: 30
Prepare Input and Output Tensors#
Like in feature-based machine learning, a computational model only accepts numeric values. It is necessary to convert raw texts to numeric tensors for neural network.
After we create the
Tokenizer, we use theTokenizerto perform text vectorization, i.e., converting texts into tensors.In deep learning, words or characters are automatically converted into numeric representations. In other words, the feature engineering step is fully automatic.
Two Ways of Text Vectorization#
Texts to Sequences (Embeddings): This process involves converting textual data into numerical representations suitable for processing in deep learning models.
Tokenization: The first step is tokenization, where each text is split into individual words or tokens. For example, the sentence “The quick brown fox” would be tokenized into [“The”, “quick”, “brown”, “fox”].
Integer Sequences: Next, each word token is mapped to a unique integer identifier. This mapping creates an integer sequence representing the original text. For instance, if we assigned unique integers to each word token, “The quick brown fox” might become [1, 2, 3, 4].
Embeddings: These integer sequences are then transformed into dense vector representations called embeddings. Embeddings capture semantic information about each word in a continuous vector space. This transformation is typically achieved using techniques like word embeddings (e.g., Word2Vec, GloVe) or character embeddings.
Input for Deep Learning Models: These embeddings serve as the input for deep learning sequence models, such as recurrent neural networks (RNNs) or long short-term memory networks (LSTMs). In these models, the embeddings are processed sequentially, with each word embedding influencing the model’s predictions or behavior.
Texts to Matrix (One-hot Encodings): This involves converting textual data into a matrix format that can be used as input for machine learning models.
Bag-of-Words Representation: The first step in the “Texts to Matrix” process is to create a bag-of-words representation for each text. This representation disregards the order and structure of the words in the text and focuses solely on the presence or absence of words. Each text is represented as a vector, where each element corresponds to a unique word in the entire dataset.
One-Hot Encoding: One way to represent the bag-of-words is through one-hot encoding. In this encoding scheme, each word in the entire vocabulary is assigned a unique index. Then, for each text, a vector is created where each element corresponds to a word in the vocabulary. If a word appears in the text, its corresponding element in the vector is set to 1; otherwise, it is set to 0. This results in a sparse binary matrix where each row represents a text and each column represents a word in the vocabulary.
Frequency-Based Representation: Alternatively, instead of using binary values (0 or 1), we can use the frequency of occurrence of each word in the text. This is similar to the functionality provided by the
CountVectorizer()in machine learning libraries. Each element in the vector represents the count or frequency of occurrence of the corresponding word in the text.Matrix Representation: The final output of the “Texts to Matrix” process is a matrix where each row corresponds to a text and each column corresponds to a unique word in the entire dataset. The values in the matrix represent the presence or frequency of words in the texts, depending on the chosen encoding scheme.
Method 1: Text to Sequences#
From Texts and Sequences#
We can convert our corpus texts into integer sequences using
Tokenizer.texts_to_sequences().Because texts vary in lengths, we use
keras.preprocessing.sequence.pad_sequence()to pad all texts into a uniform length.This step is important. This ensures that every text, when pushed into the network, has exactly the same tensor shape.
names_ints = tokenizer.texts_to_sequences(names)
print(names[:5])
print(names_ints[:5])
print(labels[:5])
['Loren', 'Rori', 'Ximenez', 'Jeanelle', 'Loella']
[[6, 7, 5, 2, 4], [5, 7, 5, 3], [25, 3, 12, 2, 4, 2, 24], [19, 2, 1, 4, 2, 6, 6, 2], [6, 7, 2, 6, 6, 1]]
[0, 0, 1, 0, 0]
Padding#
When padding the all texts into uniform lengths, consider whether to pad or remove values from the beginning of the sequence (i.e.,
pre) or the other way (post).Check
paddingandtruncatingparameters inpad_sequencesIn this tutorial, we first identify the longest name, and use its length as the
max_lenand pad all names into themax_len.
## We can check the length distribution of texts in corpus
names_lens = [len(n) for n in names_ints]
names_lens
sns.displot(names_lens)
print(names[np.argmax(names_lens)]) # longest name
Helen-Elizabeth
/Users/alvinchen/anaconda3/envs/python-notes/lib/python3.9/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
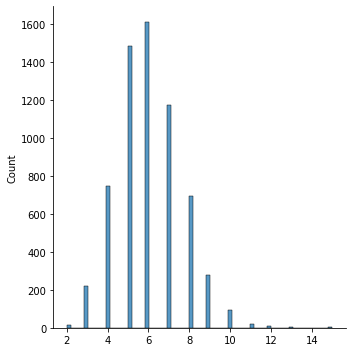
max_len = names_lens[np.argmax(names_lens)]
max_len
15
names_ints_pad = sequence.pad_sequences(names_ints, maxlen=max_len)
names_ints_pad[:10]
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7, 5, 2, 4],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 7, 5, 3],
[ 0, 0, 0, 0, 0, 0, 0, 0, 25, 3, 12, 2, 4, 2, 24],
[ 0, 0, 0, 0, 0, 0, 0, 19, 2, 1, 4, 2, 6, 6, 2],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7, 2, 6, 6, 1],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 7, 4, 3],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 6, 20, 1],
[ 0, 0, 0, 0, 0, 0, 0, 0, 2, 5, 1, 9, 8, 16, 9],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 10, 1, 4, 3, 2],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 1, 4, 2]],
dtype=int32)
Define X and y#
So for names, we convert names into integer sequences, and pad them into the uniform length.
We perform exactly the same processing to the names in testing data.
We convert both the names (X) and labels (y) into
numpy.array.
## training data
X_train = np.array(names_ints_pad).astype('int32')
y_train = np.array(labels)
## testing data
X_test_texts = [n for (n, l) in test_set]
X_test = np.array(
sequence.pad_sequences(tokenizer.texts_to_sequences(X_test_texts),
maxlen=max_len)).astype('int32')
y_test = np.array([l for (n, l) in test_set])
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(6355, 15)
(6355,)
(1589, 15)
(1589,)
Method 2: Text to Matrix#
One-Hot Encoding (Bag-of-Words)#
We can convert each text to a bag-of-words vector using
Tokenzier.texts_to_matrix().In particular, we can specify the parameter
mode:binary,count, ortfidf.When the
mode="binary", the text vector is a one-hot encoding vector, indicating whether a character occurs in the text or not.
names_matrix = tokenizer.texts_to_matrix(names, mode="binary")
print(names_matrix.shape)
(6355, 30)
print(names[2]) ## target name string
print(names_matrix[2,:]) ## one-hot encoding of the name
print(names_matrix[2, ].shape) ## size of the one-hot encoding vector
Ximenez
[0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
1. 1. 0. 0. 0. 0.]
(30,)
tokenizer.word_index
{'a': 1,
'e': 2,
'i': 3,
'n': 4,
'r': 5,
'l': 6,
'o': 7,
't': 8,
's': 9,
'd': 10,
'y': 11,
'm': 12,
'h': 13,
'c': 14,
'b': 15,
'u': 16,
'g': 17,
'k': 18,
'j': 19,
'v': 20,
'f': 21,
'p': 22,
'w': 23,
'z': 24,
'x': 25,
'q': 26,
'-': 27,
' ': 28,
"'": 29}
Define X and Y#
X_train2 = np.array(names_matrix).astype('int32')
y_train2 = np.array(labels)
X_test2 = tokenizer.texts_to_matrix(X_test_texts,
mode="binary").astype('int32')
y_test2 = np.array([l for (n, l) in test_set])
print(X_train2.shape)
print(y_train2.shape)
print(X_test2.shape)
print(y_test2.shape)
(6355, 30)
(6355,)
(1589, 30)
(1589,)
Model Definition#
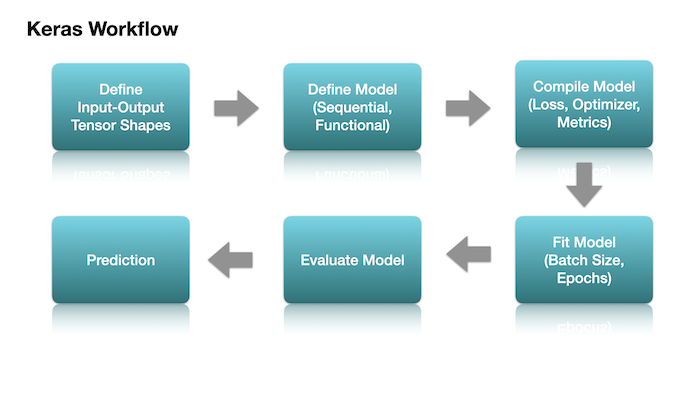
Three important steps for building a deep neural network:
Define the model structure
Compile the model
Fit the model
After we have defined our input and output tensors (X and y), we can define the architecture of our neural network model.
For the two ways of name vectorized representations, we try two different types of networks.
Text to Matrix (One-hot Encodings): Fully connected Dense Layers
Text to Sequences (Embeddings): Embedding + RNN
## Two Versions of Plotting Functions for `history` from `model.fit()`
def plot1(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
## Accuracy plot
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
## Loss plot
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
def plot2(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
#plt.gca().set_ylim(0,1)
plt.show()
Model 1: Fully Connected Dense Layers#
Let’s try a simple neural network with two fully-connected dense layers with the Text-to-Matrix inputs.
That is, the input of this model is the bag-of-words representation of the entire name.
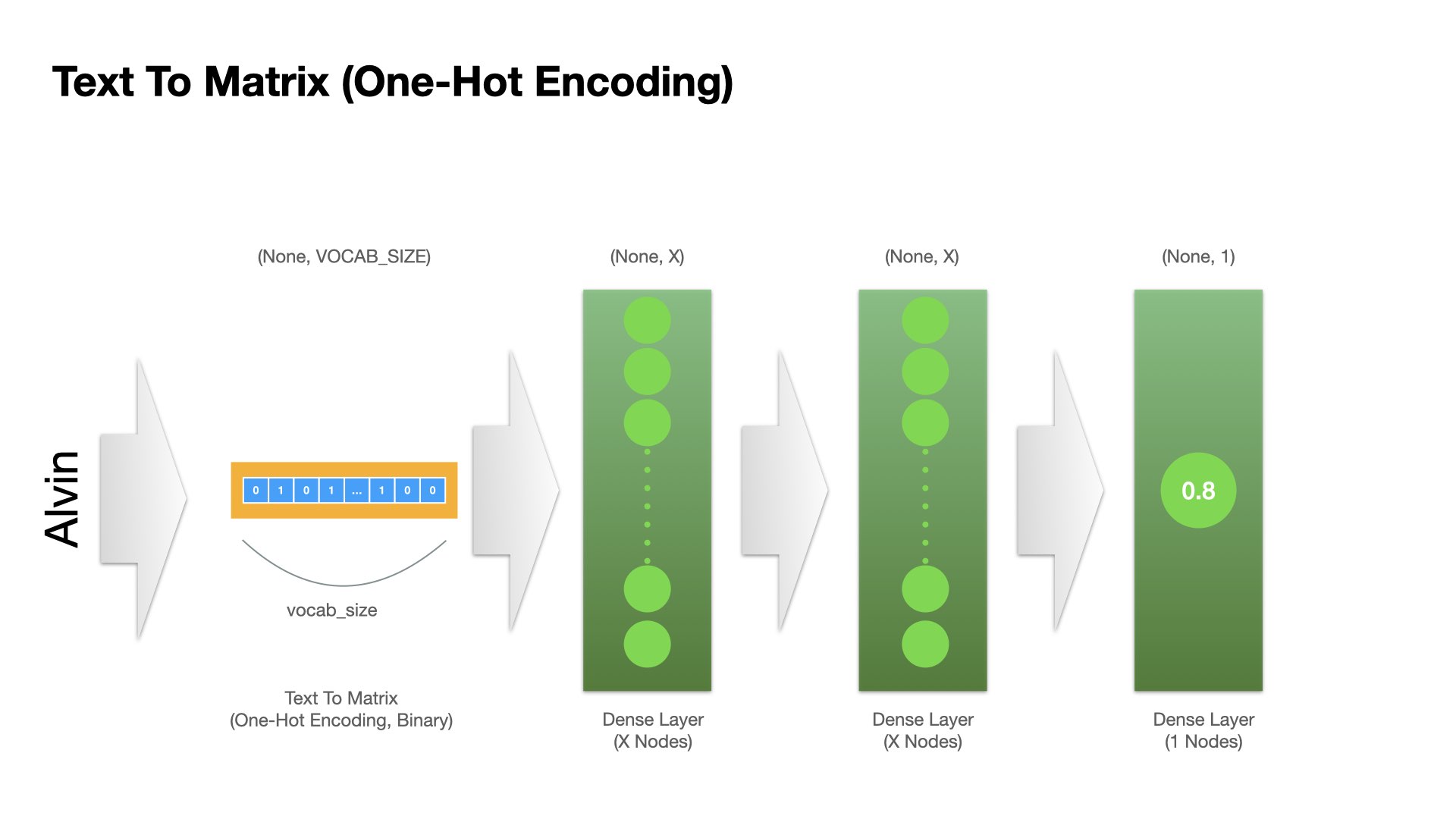
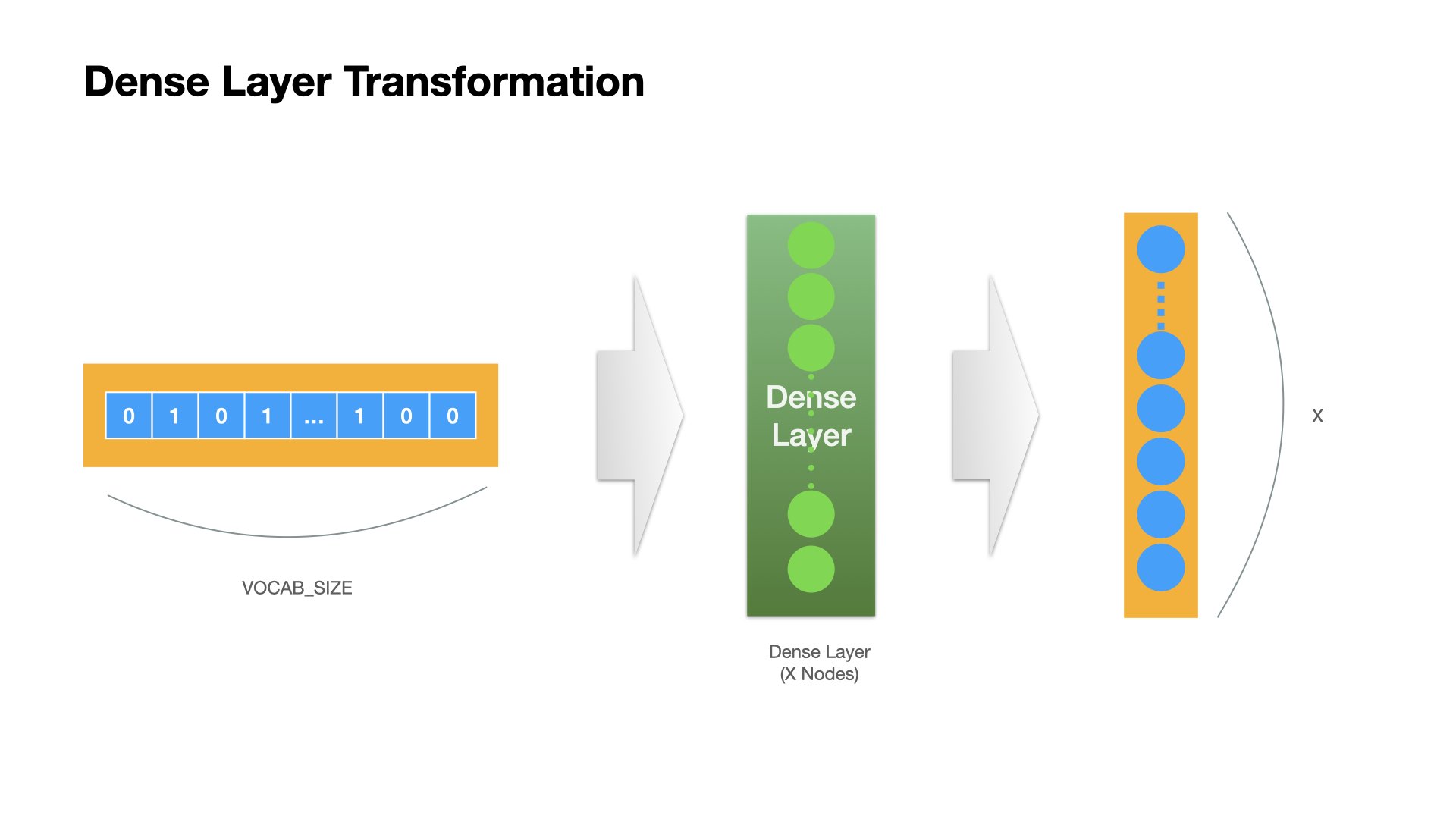
Dense Layer Operation#
The transformation of each Dense layer will transform the input tensor into a tensor whose dimension size is the same as the node number of the Dense layer.
## Define Model
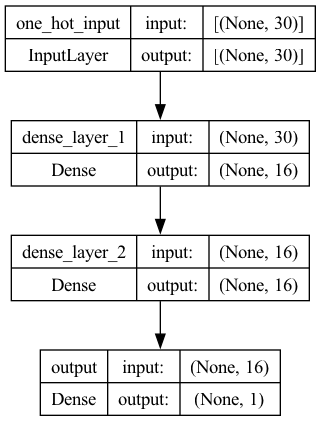
model1 = keras.Sequential() ## initialize a sequential model
model1.add(keras.Input(shape=(vocab_size, ), name="one_hot_input")) ## add input layer
model1.add(layers.Dense(16, activation="relu", name="dense_layer_1")) ## add dense layer 1
model1.add(layers.Dense(16, activation="relu", name="dense_layer_2")) ## add dense layer 2
model1.add(layers.Dense(1, activation="sigmoid", name="output")) ## add final layer
## Compile Model
model1.compile(loss='binary_crossentropy', ## loss function
optimizer='adam', ## optimization method
metrics=["accuracy"]) ## evaluation metrics
plot_model(model1, show_shapes=True)
A few hyperparameters for network training#
Batch Size: The number of inputs needed per update of the model parameter (gradient descent)
Epoch: How many iterations needed for training
Validation Split Ratio: Proportion of validation and training data split
## Hyperparameters
BATCH_SIZE = 128
EPOCHS = 20
VALIDATION_SPLIT = 0.2
## Fit the model
history1 = model1.fit(X_train2,
y_train2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
40/40 - 0s - loss: 0.6806 - accuracy: 0.5692 - val_loss: 0.6560 - val_accuracy: 0.6381 - 235ms/epoch - 6ms/step
Epoch 2/20
40/40 - 0s - loss: 0.6492 - accuracy: 0.6308 - val_loss: 0.6370 - val_accuracy: 0.6389 - 29ms/epoch - 737us/step
Epoch 3/20
40/40 - 0s - loss: 0.6350 - accuracy: 0.6446 - val_loss: 0.6226 - val_accuracy: 0.6570 - 28ms/epoch - 710us/step
Epoch 4/20
40/40 - 0s - loss: 0.6228 - accuracy: 0.6581 - val_loss: 0.6106 - val_accuracy: 0.6766 - 27ms/epoch - 681us/step
Epoch 5/20
40/40 - 0s - loss: 0.6125 - accuracy: 0.6678 - val_loss: 0.6009 - val_accuracy: 0.6900 - 27ms/epoch - 685us/step
Epoch 6/20
40/40 - 0s - loss: 0.6026 - accuracy: 0.6772 - val_loss: 0.5935 - val_accuracy: 0.7034 - 28ms/epoch - 698us/step
Epoch 7/20
40/40 - 0s - loss: 0.5947 - accuracy: 0.6833 - val_loss: 0.5885 - val_accuracy: 0.7113 - 28ms/epoch - 695us/step
Epoch 8/20
40/40 - 0s - loss: 0.5877 - accuracy: 0.6880 - val_loss: 0.5853 - val_accuracy: 0.7073 - 28ms/epoch - 692us/step
Epoch 9/20
40/40 - 0s - loss: 0.5833 - accuracy: 0.6902 - val_loss: 0.5833 - val_accuracy: 0.7089 - 28ms/epoch - 706us/step
Epoch 10/20
40/40 - 0s - loss: 0.5799 - accuracy: 0.6941 - val_loss: 0.5808 - val_accuracy: 0.7120 - 28ms/epoch - 700us/step
Epoch 11/20
40/40 - 0s - loss: 0.5765 - accuracy: 0.6949 - val_loss: 0.5801 - val_accuracy: 0.7105 - 27ms/epoch - 687us/step
Epoch 12/20
40/40 - 0s - loss: 0.5735 - accuracy: 0.6985 - val_loss: 0.5784 - val_accuracy: 0.7120 - 28ms/epoch - 691us/step
Epoch 13/20
40/40 - 0s - loss: 0.5713 - accuracy: 0.7048 - val_loss: 0.5783 - val_accuracy: 0.7089 - 28ms/epoch - 696us/step
Epoch 14/20
40/40 - 0s - loss: 0.5700 - accuracy: 0.7044 - val_loss: 0.5760 - val_accuracy: 0.7113 - 28ms/epoch - 695us/step
Epoch 15/20
40/40 - 0s - loss: 0.5677 - accuracy: 0.7095 - val_loss: 0.5775 - val_accuracy: 0.7010 - 27ms/epoch - 676us/step
Epoch 16/20
40/40 - 0s - loss: 0.5662 - accuracy: 0.7099 - val_loss: 0.5745 - val_accuracy: 0.7057 - 28ms/epoch - 693us/step
Epoch 17/20
40/40 - 0s - loss: 0.5639 - accuracy: 0.7091 - val_loss: 0.5735 - val_accuracy: 0.7057 - 29ms/epoch - 716us/step
Epoch 18/20
40/40 - 0s - loss: 0.5626 - accuracy: 0.7150 - val_loss: 0.5735 - val_accuracy: 0.7057 - 28ms/epoch - 694us/step
Epoch 19/20
40/40 - 0s - loss: 0.5604 - accuracy: 0.7150 - val_loss: 0.5721 - val_accuracy: 0.7057 - 27ms/epoch - 676us/step
Epoch 20/20
40/40 - 0s - loss: 0.5595 - accuracy: 0.7164 - val_loss: 0.5718 - val_accuracy: 0.7081 - 28ms/epoch - 694us/step
plot2(history1)
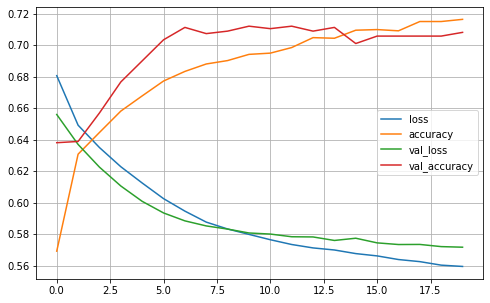
model1.evaluate(X_test2, y_test2, batch_size=BATCH_SIZE, verbose=2)
13/13 - 0s - loss: 0.5500 - accuracy: 0.7225 - 16ms/epoch - 1ms/step
[0.5500425696372986, 0.7224669456481934]
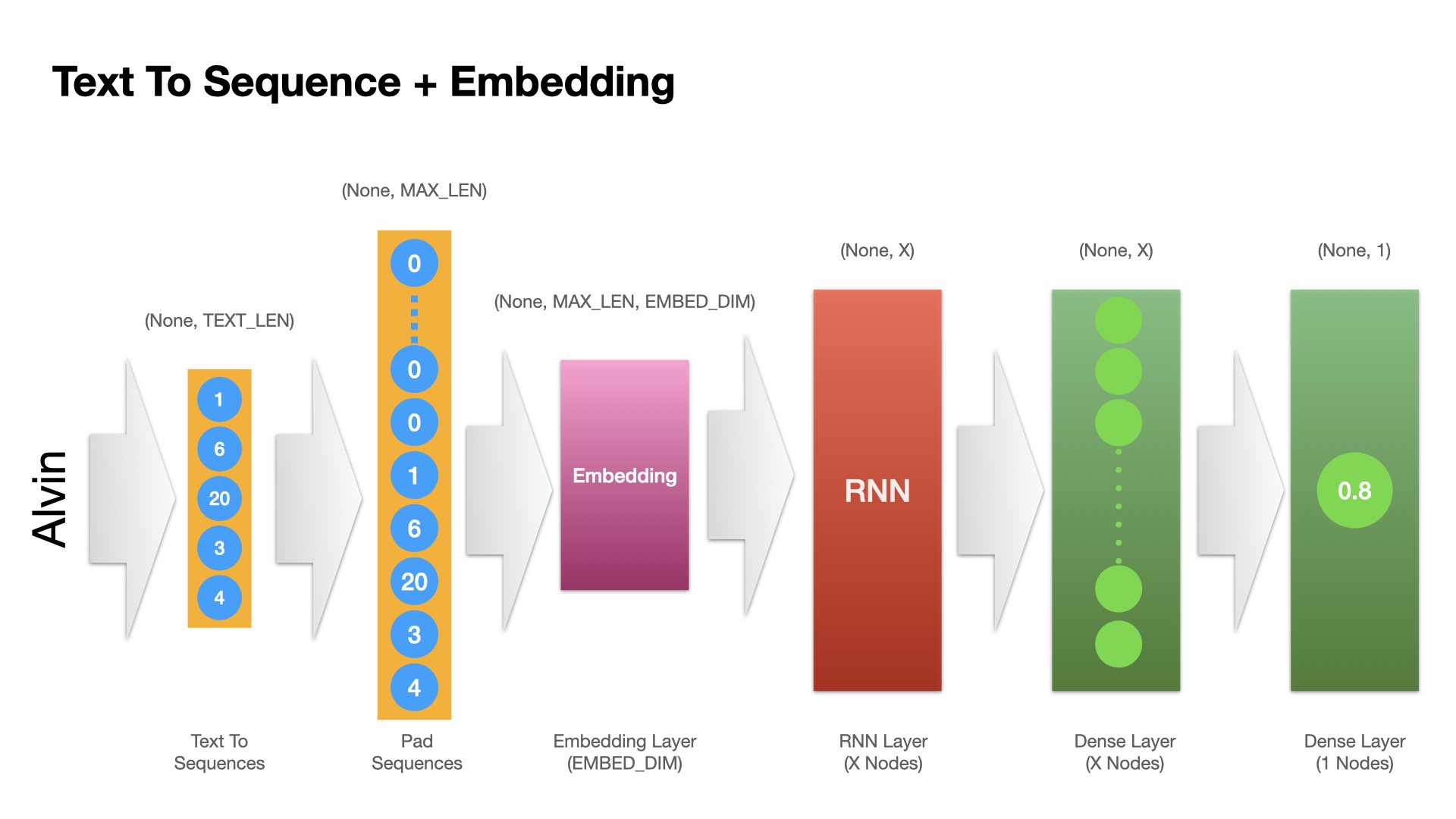
Model 2: Embedding + RNN#
Another possibility is to introduce an embedding layer in the network, which transforms each character token of the name into a tensor (i.e., embeddings), and then we add a Recurrent Neural Network (RNN) layer to process each character sequentially.
The strength of the RNN is that it iterates over the timesteps of a sequence, while maintaining an internal state that encodes information about the timesteps it has seen so far.
It is posited that after the RNN iterates through the entire sequence, it keeps important information of all previously iterated tokens for further operation.
The input of this network is a padded sequence of the original text (name).
## Define the embedding dimension
EMBEDDING_DIM = 128
## Define model
model2 = Sequential()
## add embedding layer
model2.add(
layers.Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
## add RNN layer
model2.add(layers.SimpleRNN(16, return_sequences = False, activation="relu", name="RNN_layer"))
## add Dense layer
model2.add(layers.Dense(16, activation="relu", name="dense_layer"))
## add final layer
model2.add(layers.Dense(1, activation="sigmoid", name="output"))
Note
The
mask_zero =inEmbeddingindicates whether or not the input value 0 is a special “padding” value that should be masked out. This is useful when using recurrent layers which may take variable length input.Adding a Dense layer after the RNN allows for further feature transformation, non-linearity, dimensionality reduction, and task-specific representation learning, which are often crucial for achieving good performance on various deep learning tasks.
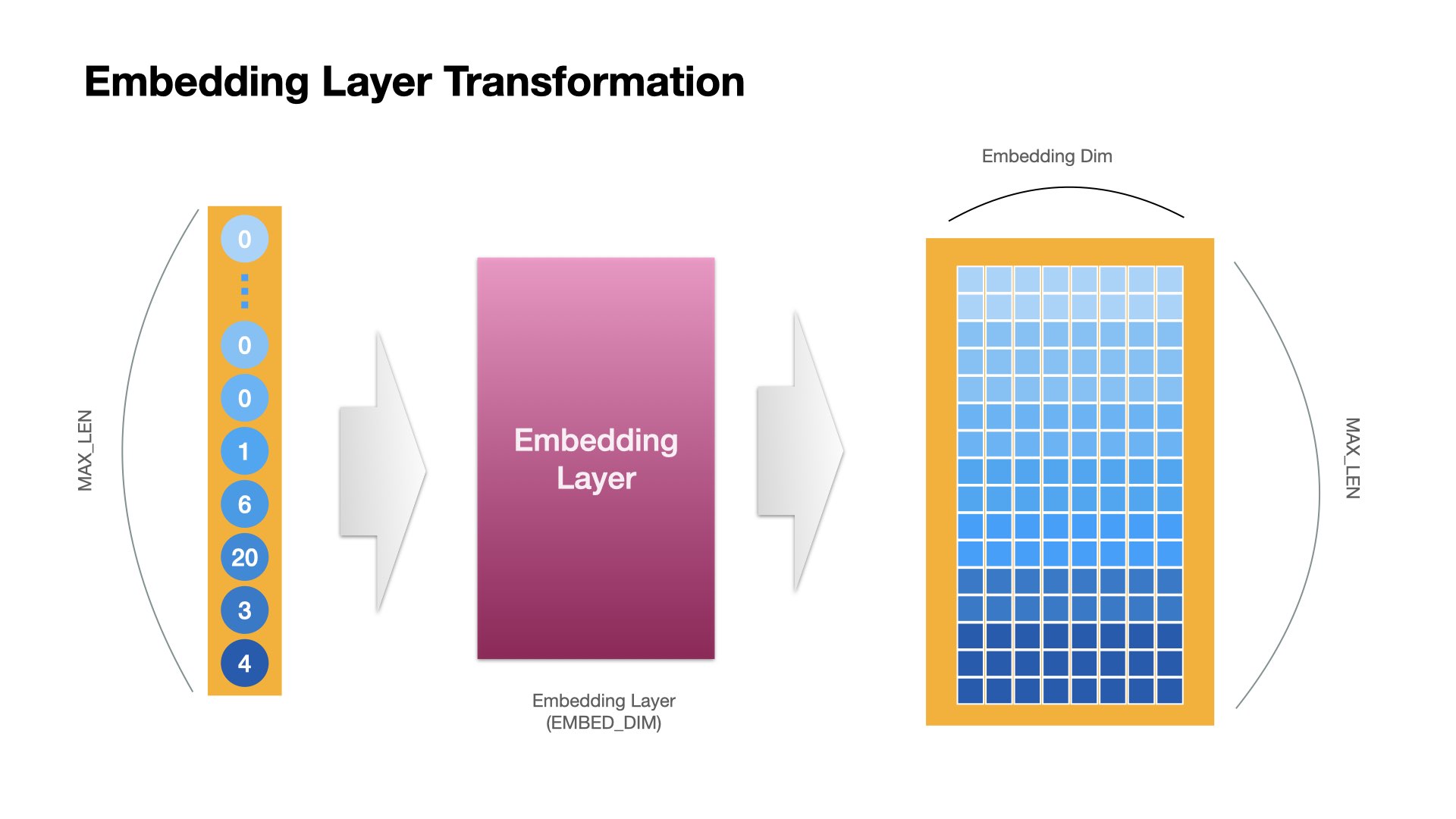
Embedding Layer Operation#
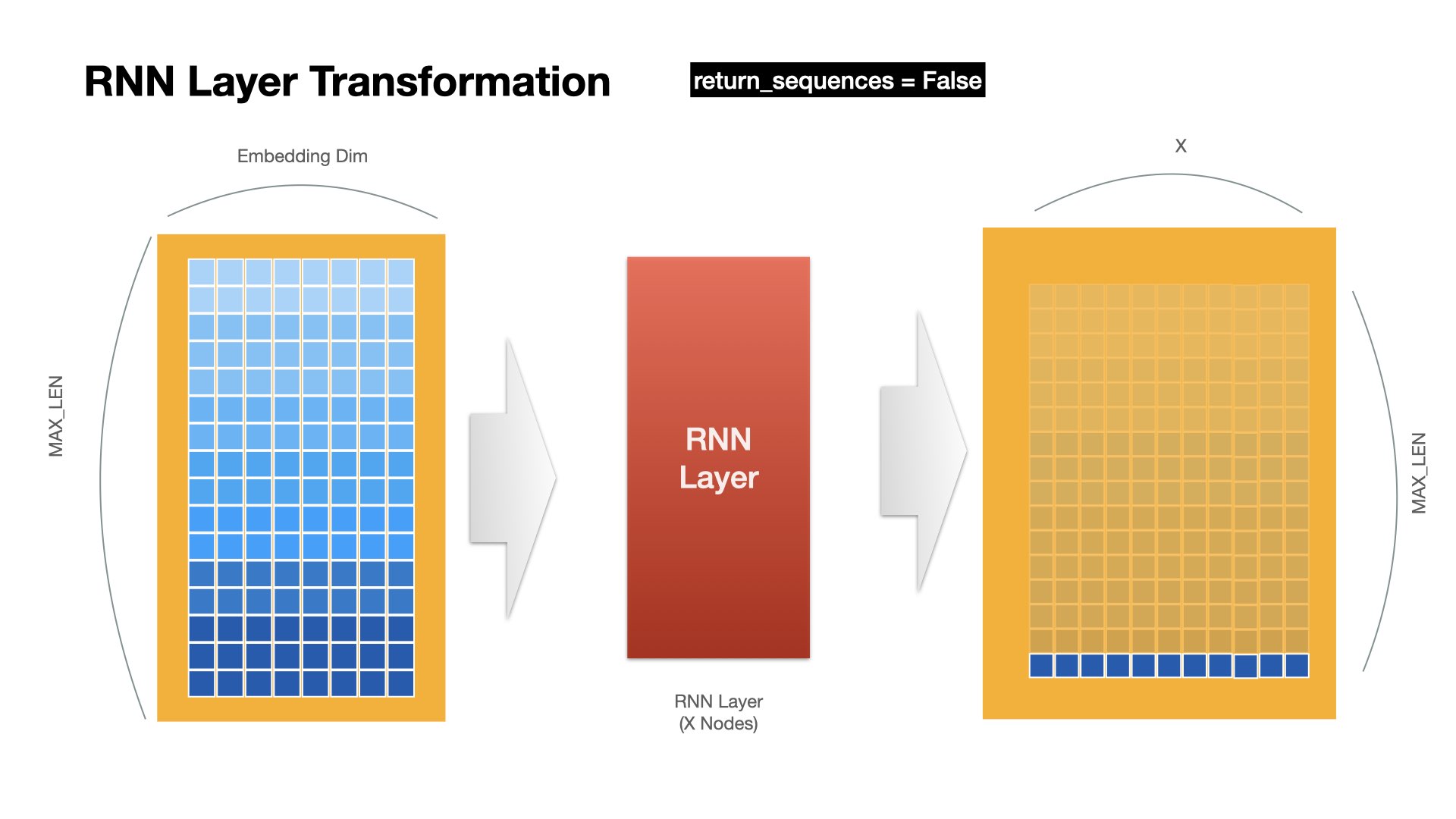
RNN Layer Operation (last)#
RNN returns only the hidden states at the last time step
RNN Layer Operation (all)#
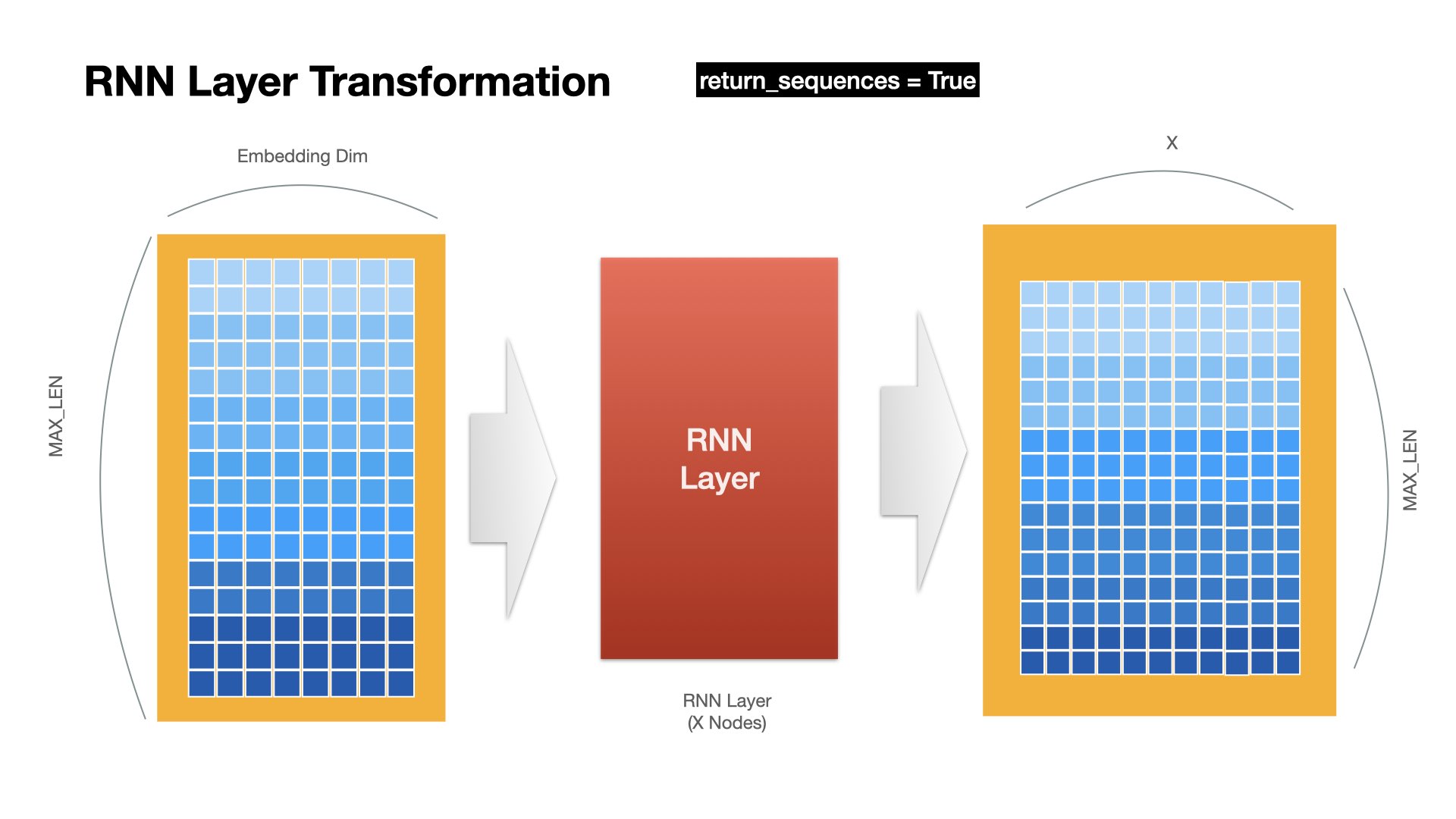
RNN returns the hidden states at all time steps
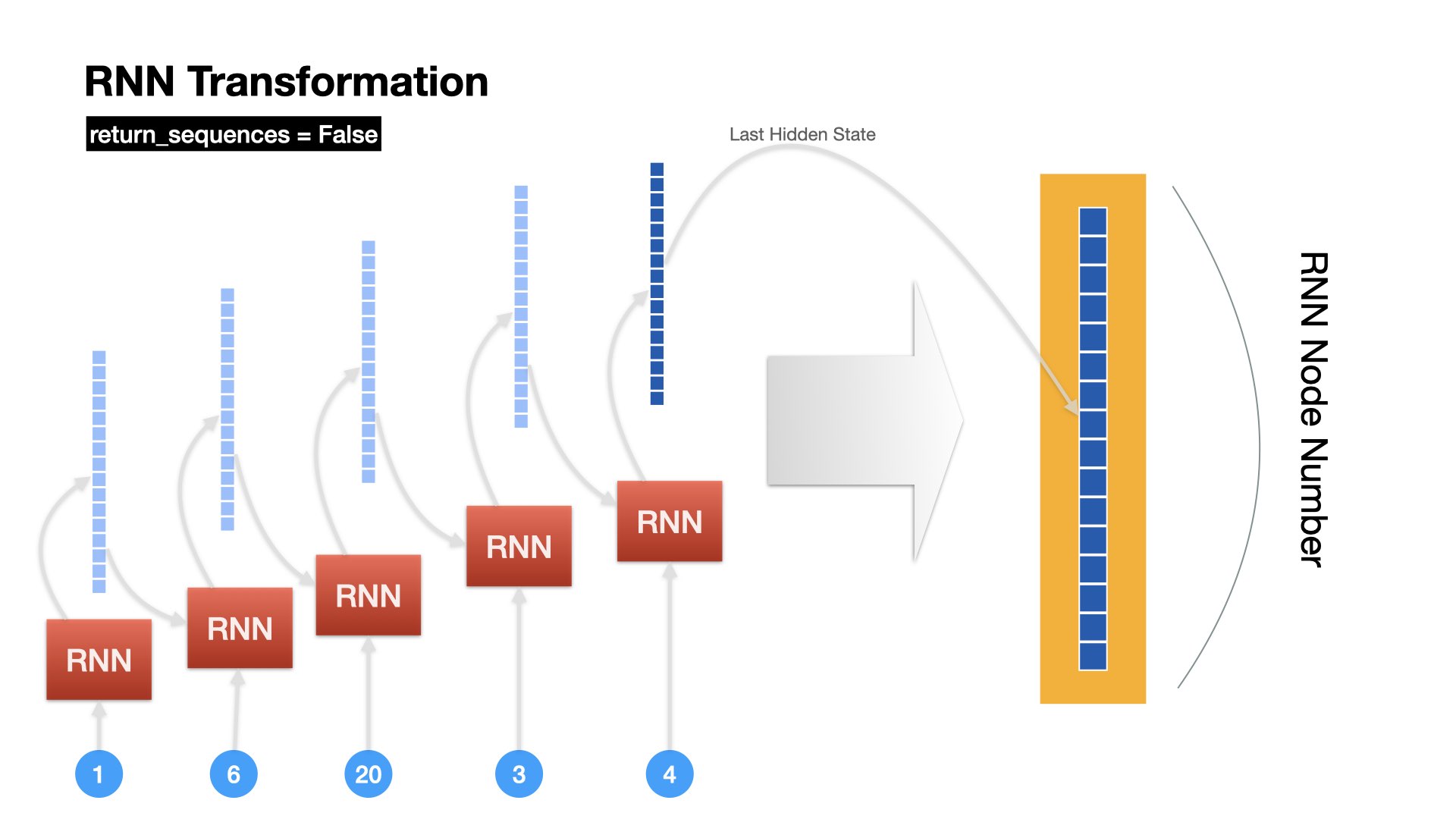
Unrolled Version of RNN Operation (last only)#
RNN returns only the hidden state of the last time step
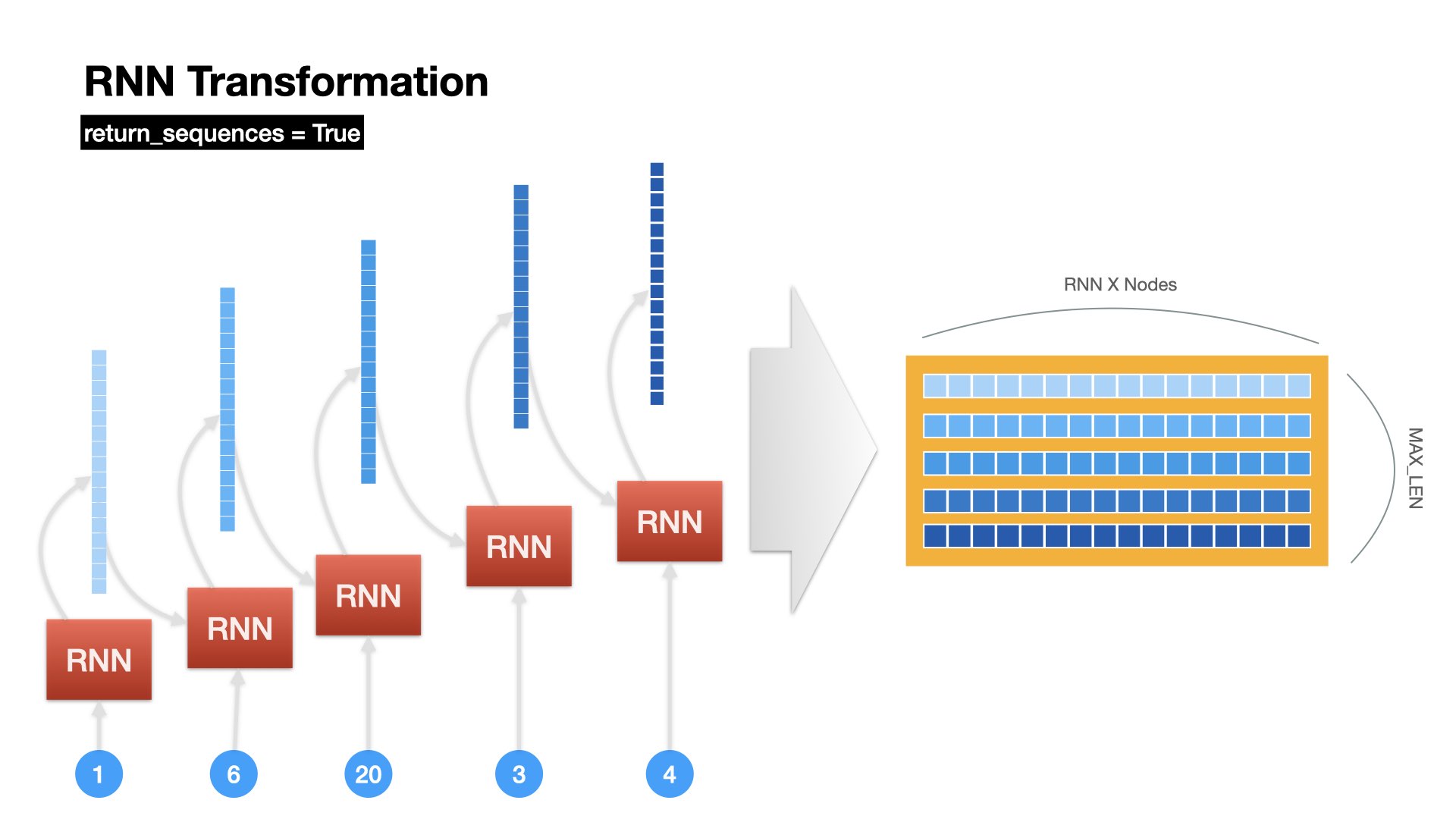
Unrolled Version of RNN Operation (all)#
RNN returns all hidden states at all time steps
plot_model(model2, show_shapes=True)
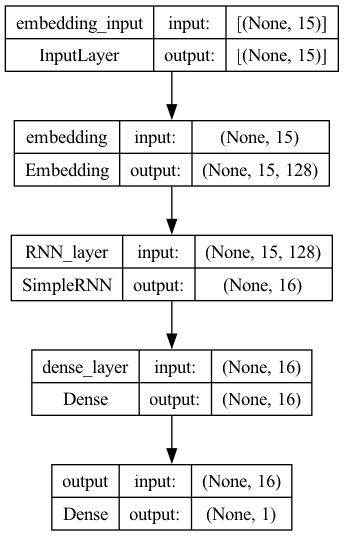
## Compile the model
model2.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
## Fit the model
history2 = model2.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
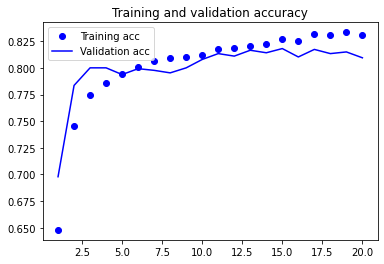
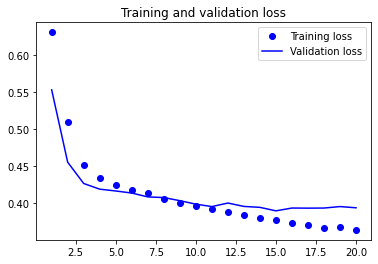
40/40 - 1s - loss: 0.6308 - accuracy: 0.6479 - val_loss: 0.5530 - val_accuracy: 0.6979 - 581ms/epoch - 15ms/step
Epoch 2/20
40/40 - 0s - loss: 0.5095 - accuracy: 0.7455 - val_loss: 0.4553 - val_accuracy: 0.7836 - 114ms/epoch - 3ms/step
Epoch 3/20
40/40 - 0s - loss: 0.4522 - accuracy: 0.7746 - val_loss: 0.4266 - val_accuracy: 0.8002 - 120ms/epoch - 3ms/step
Epoch 4/20
40/40 - 0s - loss: 0.4337 - accuracy: 0.7856 - val_loss: 0.4189 - val_accuracy: 0.8002 - 122ms/epoch - 3ms/step
Epoch 5/20
40/40 - 0s - loss: 0.4252 - accuracy: 0.7945 - val_loss: 0.4165 - val_accuracy: 0.7939 - 121ms/epoch - 3ms/step
Epoch 6/20
40/40 - 0s - loss: 0.4177 - accuracy: 0.8007 - val_loss: 0.4137 - val_accuracy: 0.7994 - 120ms/epoch - 3ms/step
Epoch 7/20
40/40 - 0s - loss: 0.4132 - accuracy: 0.8063 - val_loss: 0.4085 - val_accuracy: 0.7978 - 123ms/epoch - 3ms/step
Epoch 8/20
40/40 - 0s - loss: 0.4063 - accuracy: 0.8092 - val_loss: 0.4076 - val_accuracy: 0.7954 - 126ms/epoch - 3ms/step
Epoch 9/20
40/40 - 0s - loss: 0.4008 - accuracy: 0.8102 - val_loss: 0.4034 - val_accuracy: 0.8002 - 122ms/epoch - 3ms/step
Epoch 10/20
40/40 - 0s - loss: 0.3960 - accuracy: 0.8125 - val_loss: 0.3987 - val_accuracy: 0.8080 - 119ms/epoch - 3ms/step
Epoch 11/20
40/40 - 0s - loss: 0.3923 - accuracy: 0.8175 - val_loss: 0.3954 - val_accuracy: 0.8135 - 121ms/epoch - 3ms/step
Epoch 12/20
40/40 - 0s - loss: 0.3879 - accuracy: 0.8185 - val_loss: 0.4002 - val_accuracy: 0.8112 - 121ms/epoch - 3ms/step
Epoch 13/20
40/40 - 0s - loss: 0.3839 - accuracy: 0.8210 - val_loss: 0.3956 - val_accuracy: 0.8167 - 120ms/epoch - 3ms/step
Epoch 14/20
40/40 - 0s - loss: 0.3805 - accuracy: 0.8230 - val_loss: 0.3944 - val_accuracy: 0.8143 - 119ms/epoch - 3ms/step
Epoch 15/20
40/40 - 0s - loss: 0.3770 - accuracy: 0.8277 - val_loss: 0.3897 - val_accuracy: 0.8183 - 120ms/epoch - 3ms/step
Epoch 16/20
40/40 - 0s - loss: 0.3732 - accuracy: 0.8255 - val_loss: 0.3935 - val_accuracy: 0.8104 - 130ms/epoch - 3ms/step
Epoch 17/20
40/40 - 0s - loss: 0.3706 - accuracy: 0.8316 - val_loss: 0.3933 - val_accuracy: 0.8175 - 123ms/epoch - 3ms/step
Epoch 18/20
40/40 - 0s - loss: 0.3670 - accuracy: 0.8306 - val_loss: 0.3934 - val_accuracy: 0.8135 - 121ms/epoch - 3ms/step
Epoch 19/20
40/40 - 0s - loss: 0.3683 - accuracy: 0.8336 - val_loss: 0.3954 - val_accuracy: 0.8151 - 118ms/epoch - 3ms/step
Epoch 20/20
40/40 - 0s - loss: 0.3639 - accuracy: 0.8306 - val_loss: 0.3938 - val_accuracy: 0.8096 - 121ms/epoch - 3ms/step
plot1(history2)
model2.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
13/13 - 0s - loss: 0.3756 - accuracy: 0.8282 - 25ms/epoch - 2ms/step
[0.37555640935897827, 0.8281938433647156]
Model 3: Regularization and Dropout#
Based on the validation results of the previous two models (esp. the RNN-based model), we can see that they are probably a bit overfit because the model performance on the validation set starts to stall after the first few epochs.
We can add regularization and dropouts in our network definition to avoid overfitting.
Regularization achieves this by adding a penalty term to the loss function, while dropout achieves it by randomly dropping out neurons during training.
## Define embedding dimension
EMBEDDING_DIM = 128
## Define model
model3 = Sequential()
model3.add(
layers.Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model3.add(
layers.SimpleRNN(16,
activation="relu",
name="RNN_layer",
dropout=0.2, ## dropout for input character
recurrent_dropout=0.2)) ## dropout for previous state
model3.add(layers.Dense(16, activation="relu", name="dense_layer"))
model3.add(layers.Dense(1, activation="sigmoid", name="output"))
plot_model(model3, show_shapes=True)
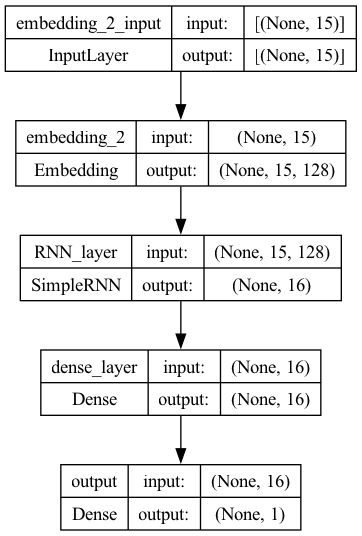
## Compile the model
model3.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
## Fit the model
history3 = model3.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
40/40 - 1s - loss: 0.6375 - accuracy: 0.6452 - val_loss: 0.5566 - val_accuracy: 0.7034 - 718ms/epoch - 18ms/step
Epoch 2/20
40/40 - 0s - loss: 0.5205 - accuracy: 0.7315 - val_loss: 0.4739 - val_accuracy: 0.7710 - 183ms/epoch - 5ms/step
Epoch 3/20
40/40 - 0s - loss: 0.4783 - accuracy: 0.7638 - val_loss: 0.4406 - val_accuracy: 0.7915 - 197ms/epoch - 5ms/step
Epoch 4/20
40/40 - 0s - loss: 0.4617 - accuracy: 0.7646 - val_loss: 0.4247 - val_accuracy: 0.7970 - 200ms/epoch - 5ms/step
Epoch 5/20
40/40 - 0s - loss: 0.4540 - accuracy: 0.7764 - val_loss: 0.4210 - val_accuracy: 0.7978 - 204ms/epoch - 5ms/step
Epoch 6/20
40/40 - 0s - loss: 0.4507 - accuracy: 0.7760 - val_loss: 0.4175 - val_accuracy: 0.8057 - 201ms/epoch - 5ms/step
Epoch 7/20
40/40 - 0s - loss: 0.4464 - accuracy: 0.7803 - val_loss: 0.4126 - val_accuracy: 0.8049 - 203ms/epoch - 5ms/step
Epoch 8/20
40/40 - 0s - loss: 0.4412 - accuracy: 0.7846 - val_loss: 0.4129 - val_accuracy: 0.7978 - 201ms/epoch - 5ms/step
Epoch 9/20
40/40 - 0s - loss: 0.4410 - accuracy: 0.7852 - val_loss: 0.4134 - val_accuracy: 0.8009 - 200ms/epoch - 5ms/step
Epoch 10/20
40/40 - 0s - loss: 0.4329 - accuracy: 0.7893 - val_loss: 0.4053 - val_accuracy: 0.8088 - 203ms/epoch - 5ms/step
Epoch 11/20
40/40 - 0s - loss: 0.4318 - accuracy: 0.7966 - val_loss: 0.4049 - val_accuracy: 0.8041 - 204ms/epoch - 5ms/step
Epoch 12/20
40/40 - 0s - loss: 0.4353 - accuracy: 0.7899 - val_loss: 0.4048 - val_accuracy: 0.8088 - 211ms/epoch - 5ms/step
Epoch 13/20
40/40 - 0s - loss: 0.4287 - accuracy: 0.7927 - val_loss: 0.4030 - val_accuracy: 0.8080 - 206ms/epoch - 5ms/step
Epoch 14/20
40/40 - 0s - loss: 0.4287 - accuracy: 0.7946 - val_loss: 0.4043 - val_accuracy: 0.8112 - 208ms/epoch - 5ms/step
Epoch 15/20
40/40 - 0s - loss: 0.4308 - accuracy: 0.7882 - val_loss: 0.3993 - val_accuracy: 0.8025 - 201ms/epoch - 5ms/step
Epoch 16/20
40/40 - 0s - loss: 0.4232 - accuracy: 0.7941 - val_loss: 0.3983 - val_accuracy: 0.8049 - 199ms/epoch - 5ms/step
Epoch 17/20
40/40 - 0s - loss: 0.4247 - accuracy: 0.7946 - val_loss: 0.3980 - val_accuracy: 0.8057 - 196ms/epoch - 5ms/step
Epoch 18/20
40/40 - 0s - loss: 0.4226 - accuracy: 0.8033 - val_loss: 0.3957 - val_accuracy: 0.8065 - 200ms/epoch - 5ms/step
Epoch 19/20
40/40 - 0s - loss: 0.4233 - accuracy: 0.7966 - val_loss: 0.3983 - val_accuracy: 0.8041 - 197ms/epoch - 5ms/step
Epoch 20/20
40/40 - 0s - loss: 0.4224 - accuracy: 0.8011 - val_loss: 0.3968 - val_accuracy: 0.8025 - 199ms/epoch - 5ms/step
plot1(history3)
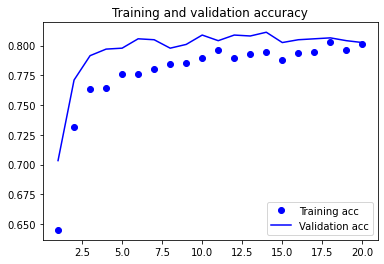
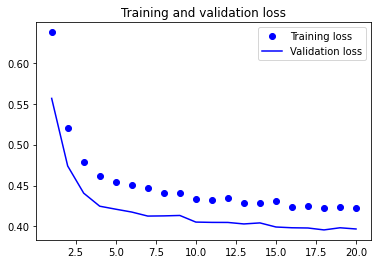
model3.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
13/13 - 0s - loss: 0.3872 - accuracy: 0.8194 - 26ms/epoch - 2ms/step
[0.387204647064209, 0.8193832635879517]
Model 4: Improve the Model by Stacking Multiple RNNs#
In addition to regularization and dropouts, we can further improve the model by increasing the model complexity.
In particular, we can increase the depths and widths of the network layers.
Let’s try stacking two RNN layers.
Tip
When we stack two sequence layers (e.g., RNN), we need to make sure that the hidden states (outputs) of the first sequence layer at all timesteps are properly passed onto the next sequence layer, not just the hidden state (output) of the last timestep.
In keras, this usually means that we need to set the argument return_sequences=True in a sequence layer (e.g., SimpleRNN, LSTM, GRU etc).
## Define embedding dimension
MBEDDING_DIM = 128
## Define model
model4 = Sequential()
model4.add(
layers.Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model4.add(
layers.SimpleRNN(16,
activation="relu",
name="RNN_layer_1",
dropout=0.2,
recurrent_dropout=0.2,
return_sequences=True)
) ## To ensure the hidden states of all timesteps are pased down to next layer
model4.add(
layers.SimpleRNN(16,
activation="relu",
name="RNN_layer_2",
dropout=0.2,
recurrent_dropout=0.2))
model4.add(layers.Dense(1, activation="sigmoid", name="output"))
plot_model(model4, show_shapes=True)
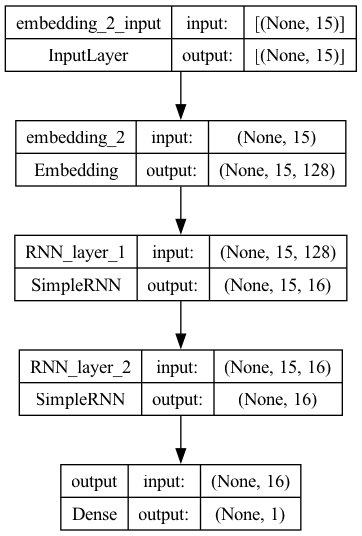
## Compile the model
model3.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
## Fit the model
history4 = model4.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
40/40 - 1s - loss: 0.6380 - accuracy: 0.6355 - val_loss: 0.5946 - val_accuracy: 0.6357 - 1s/epoch - 28ms/step
Epoch 2/20
40/40 - 0s - loss: 0.5810 - accuracy: 0.6591 - val_loss: 0.5310 - val_accuracy: 0.7026 - 270ms/epoch - 7ms/step
Epoch 3/20
40/40 - 0s - loss: 0.5333 - accuracy: 0.7034 - val_loss: 0.4946 - val_accuracy: 0.7663 - 279ms/epoch - 7ms/step
Epoch 4/20
40/40 - 0s - loss: 0.5076 - accuracy: 0.7250 - val_loss: 0.4701 - val_accuracy: 0.7687 - 286ms/epoch - 7ms/step
Epoch 5/20
40/40 - 0s - loss: 0.4920 - accuracy: 0.7455 - val_loss: 0.4480 - val_accuracy: 0.7797 - 285ms/epoch - 7ms/step
Epoch 6/20
40/40 - 0s - loss: 0.4776 - accuracy: 0.7626 - val_loss: 0.4356 - val_accuracy: 0.7876 - 285ms/epoch - 7ms/step
Epoch 7/20
40/40 - 0s - loss: 0.4754 - accuracy: 0.7567 - val_loss: 0.4324 - val_accuracy: 0.7868 - 291ms/epoch - 7ms/step
Epoch 8/20
40/40 - 0s - loss: 0.4670 - accuracy: 0.7642 - val_loss: 0.4291 - val_accuracy: 0.7899 - 297ms/epoch - 7ms/step
Epoch 9/20
40/40 - 0s - loss: 0.4582 - accuracy: 0.7775 - val_loss: 0.4248 - val_accuracy: 0.7907 - 285ms/epoch - 7ms/step
Epoch 10/20
40/40 - 0s - loss: 0.4565 - accuracy: 0.7693 - val_loss: 0.4226 - val_accuracy: 0.7931 - 291ms/epoch - 7ms/step
Epoch 11/20
40/40 - 0s - loss: 0.4615 - accuracy: 0.7705 - val_loss: 0.4280 - val_accuracy: 0.7884 - 290ms/epoch - 7ms/step
Epoch 12/20
40/40 - 0s - loss: 0.4541 - accuracy: 0.7707 - val_loss: 0.4172 - val_accuracy: 0.7986 - 283ms/epoch - 7ms/step
Epoch 13/20
40/40 - 0s - loss: 0.4471 - accuracy: 0.7777 - val_loss: 0.4173 - val_accuracy: 0.8009 - 284ms/epoch - 7ms/step
Epoch 14/20
40/40 - 0s - loss: 0.4532 - accuracy: 0.7768 - val_loss: 0.4247 - val_accuracy: 0.7954 - 285ms/epoch - 7ms/step
Epoch 15/20
40/40 - 0s - loss: 0.4499 - accuracy: 0.7766 - val_loss: 0.4131 - val_accuracy: 0.8025 - 282ms/epoch - 7ms/step
Epoch 16/20
40/40 - 0s - loss: 0.4504 - accuracy: 0.7819 - val_loss: 0.4176 - val_accuracy: 0.8049 - 286ms/epoch - 7ms/step
Epoch 17/20
40/40 - 0s - loss: 0.4406 - accuracy: 0.7797 - val_loss: 0.4117 - val_accuracy: 0.8033 - 285ms/epoch - 7ms/step
Epoch 18/20
40/40 - 0s - loss: 0.4361 - accuracy: 0.7915 - val_loss: 0.4041 - val_accuracy: 0.8096 - 285ms/epoch - 7ms/step
Epoch 19/20
40/40 - 0s - loss: 0.4389 - accuracy: 0.7846 - val_loss: 0.4079 - val_accuracy: 0.8057 - 289ms/epoch - 7ms/step
Epoch 20/20
40/40 - 0s - loss: 0.4345 - accuracy: 0.7919 - val_loss: 0.4089 - val_accuracy: 0.8065 - 284ms/epoch - 7ms/step
plot1(history4)
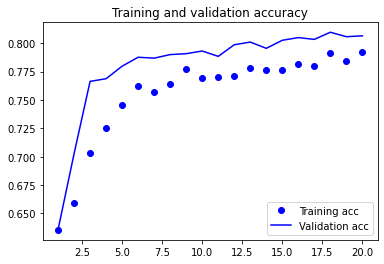
model4.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
13/13 - 0s - loss: 0.3930 - accuracy: 0.8162 - 31ms/epoch - 2ms/step
[0.39304274320602417, 0.8162366151809692]
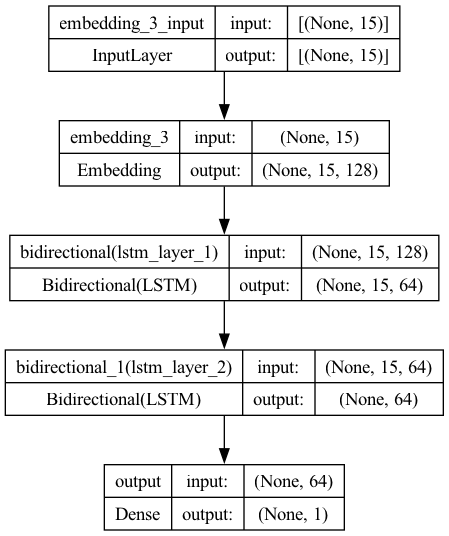
Model 5: Bidirectional RNN#
We can also increase the model complexity in at least two possible ways:
Use more advanced RNNs, such as LSTM or GRU
Process the sequence in two directions
Increase the hidden nodes of the RNN/LSTM
Now let’s try the more sophisticated RNN, LSTM, and with bidirectional sequence processing and add more nodes to the LSTM layer.
## Define embedding dimension
EMBEDDING_DIM = 128
## Define model
model5 = Sequential()
model5.add(
layers.Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model5.add(
layers.Bidirectional( ## Bidirectional sequence processing
layers.LSTM(32,
activation="relu",
name="lstm_layer_1",
dropout=0.2,
recurrent_dropout=0.5,
return_sequences=True)))
model5.add(
layers.Bidirectional( ## Bidirectional sequence processing
layers.LSTM(32,
activation="relu",
name="lstm_layer_2",
dropout=0.2,
recurrent_dropout=0.5)))
model5.add(layers.Dense(1, activation="sigmoid", name="output"))
model5.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model5, show_shapes=True)
history5 = model5.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
40/40 - 5s - loss: 0.6562 - accuracy: 0.6290 - val_loss: 0.6154 - val_accuracy: 0.6310 - 5s/epoch - 131ms/step
Epoch 2/20
40/40 - 2s - loss: 0.5895 - accuracy: 0.6520 - val_loss: 0.5420 - val_accuracy: 0.7105 - 2s/epoch - 48ms/step
Epoch 3/20
40/40 - 2s - loss: 0.5246 - accuracy: 0.7384 - val_loss: 0.4812 - val_accuracy: 0.7781 - 2s/epoch - 57ms/step
Epoch 4/20
40/40 - 2s - loss: 0.4869 - accuracy: 0.7583 - val_loss: 0.4533 - val_accuracy: 0.7852 - 2s/epoch - 57ms/step
Epoch 5/20
40/40 - 2s - loss: 0.4674 - accuracy: 0.7685 - val_loss: 0.4314 - val_accuracy: 0.8025 - 2s/epoch - 59ms/step
Epoch 6/20
40/40 - 2s - loss: 0.4515 - accuracy: 0.7787 - val_loss: 0.4227 - val_accuracy: 0.8017 - 2s/epoch - 59ms/step
Epoch 7/20
40/40 - 2s - loss: 0.4435 - accuracy: 0.7860 - val_loss: 0.4166 - val_accuracy: 0.8151 - 2s/epoch - 59ms/step
Epoch 8/20
40/40 - 2s - loss: 0.4384 - accuracy: 0.7799 - val_loss: 0.4185 - val_accuracy: 0.8080 - 2s/epoch - 59ms/step
Epoch 9/20
40/40 - 2s - loss: 0.4332 - accuracy: 0.7911 - val_loss: 0.4166 - val_accuracy: 0.8096 - 2s/epoch - 60ms/step
Epoch 10/20
40/40 - 2s - loss: 0.4298 - accuracy: 0.7884 - val_loss: 0.4086 - val_accuracy: 0.8120 - 2s/epoch - 60ms/step
Epoch 11/20
40/40 - 2s - loss: 0.4275 - accuracy: 0.7915 - val_loss: 0.4156 - val_accuracy: 0.8080 - 2s/epoch - 62ms/step
Epoch 12/20
40/40 - 2s - loss: 0.4245 - accuracy: 0.7946 - val_loss: 0.4094 - val_accuracy: 0.8175 - 2s/epoch - 60ms/step
Epoch 13/20
40/40 - 2s - loss: 0.4235 - accuracy: 0.7946 - val_loss: 0.4037 - val_accuracy: 0.8167 - 2s/epoch - 59ms/step
Epoch 14/20
40/40 - 2s - loss: 0.4179 - accuracy: 0.7996 - val_loss: 0.4070 - val_accuracy: 0.8175 - 2s/epoch - 57ms/step
Epoch 15/20
40/40 - 2s - loss: 0.4207 - accuracy: 0.7925 - val_loss: 0.4046 - val_accuracy: 0.8198 - 2s/epoch - 57ms/step
Epoch 16/20
40/40 - 2s - loss: 0.4135 - accuracy: 0.8007 - val_loss: 0.4013 - val_accuracy: 0.8198 - 2s/epoch - 57ms/step
Epoch 17/20
40/40 - 2s - loss: 0.4120 - accuracy: 0.8006 - val_loss: 0.3988 - val_accuracy: 0.8190 - 2s/epoch - 58ms/step
Epoch 18/20
40/40 - 2s - loss: 0.4069 - accuracy: 0.8035 - val_loss: 0.3994 - val_accuracy: 0.8261 - 2s/epoch - 58ms/step
Epoch 19/20
40/40 - 2s - loss: 0.4110 - accuracy: 0.8006 - val_loss: 0.3959 - val_accuracy: 0.8269 - 2s/epoch - 59ms/step
Epoch 20/20
40/40 - 2s - loss: 0.4038 - accuracy: 0.8055 - val_loss: 0.3932 - val_accuracy: 0.8245 - 2s/epoch - 58ms/step
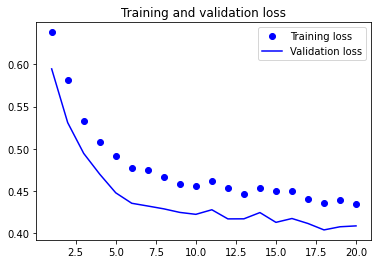
plot1(history5)
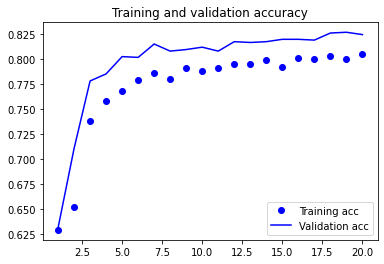
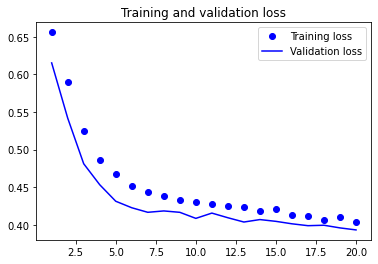
model5.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=2)
13/13 - 0s - loss: 0.3727 - accuracy: 0.8263 - 128ms/epoch - 10ms/step
[0.37272223830223083, 0.8263058662414551]
Check Embeddings#
Compared to one-hot encodings of characters, embeddings may include more “semantic” information relating to the characters.
Here we trained the (character) embeddings through a specific downstream task–namely, the name gender prediction.
In a later section, we will talk about word embeddings and how we can train word embeddings through an unsupervised method. (See Note below.)
We can extract the embedding layer and apply dimensional reduction techniques (i.e., TSNE) to see how embeddings capture the relationships in-between characters.
Note
In this section, the embeddings are trained specifically for characters through a downstream task, which in this case is predicting the gender of names. By doing so, the model learns to represent each character in a way that is most useful for the gender prediction task. For example, certain character embeddings might capture patterns that are indicative of male or female names.
In a later section, we will talk about word embeddings in more detail. We will show you that word embeddings can also be trained using unsupervised methods, where the model learns to capture the semantic meaning and contextual usage of words based on large amounts of text data, without relying on labeled datasets. This allows word embeddings to capture rich semantic relationships between words, such as synonyms, antonyms, and contextual similarity, which can then be used in various natural language processing tasks.
## A name in sequence from test set
print(X_test_texts[10])
print(X_test[10])
Julie
[ 0 0 0 0 0 0 0 0 0 0 19 16 6 3 2]
## Extract Corpus Dictionary (mapping of chars and integer indices)
ind2char = tokenizer.index_word
[ind2char.get(i) for i in X_test[10] if ind2char.get(i) != None]
['j', 'u', 'l', 'i', 'e']
## Extract the embedding layer (its weights matrix)
char_vectors = model5.layers[0].get_weights()[0]
print(char_vectors.shape) ## embedding shape (vocab_size, embed_dim)
(30, 128)
print(char_vectors[1,:]) ## first char "a" embeddings
[-0.15992522 0.05645178 -0.04315206 0.12416992 0.11700559 0.05177825
0.05285569 -0.10417991 0.08343127 -0.12686183 -0.07645164 0.05048661
0.1421134 0.10126915 0.07040089 -0.07332979 -0.10863559 -0.19609785
-0.1544781 0.08884746 0.11749582 0.08488275 -0.08945007 -0.09539443
-0.10592701 0.02802458 0.13229297 -0.07551417 -0.13340451 0.1262035
0.1710831 -0.08040723 0.14523599 -0.03381867 0.09963711 -0.14170279
-0.09306817 -0.02136101 0.14350341 0.13927357 0.13941008 -0.1025657
0.04865289 0.1150365 -0.11289226 -0.03769273 0.02027431 0.11232921
0.028004 0.11998037 -0.13926704 -0.11279164 0.10157219 0.02908029
-0.12495799 -0.11945144 -0.06300262 0.13400976 -0.10544165 -0.0744219
-0.09333702 -0.06476918 0.11507273 -0.17252535 -0.1280283 0.14370987
0.13652849 0.07962001 0.10229256 -0.09411882 0.07762508 0.13112599
0.11418491 0.09336692 -0.08881821 -0.07580823 0.0911902 0.02705303
0.1065502 -0.13841136 -0.10125943 -0.15537463 -0.10116099 0.11237971
0.05255132 0.1316333 -0.07410848 0.11726237 0.10517538 0.00911576
-0.12665565 0.02748597 -0.06122789 -0.11127966 0.02570993 0.09890527
0.10540146 -0.11014765 -0.1178944 0.13583462 0.09026558 0.11064523
-0.05437449 -0.08256266 0.12201258 0.1264016 -0.10868178 0.10844315
-0.11180297 0.00649406 -0.05072703 -0.14490801 0.07790376 -0.06778609
0.09159637 -0.08950711 -0.09174786 -0.01344115 -0.07855707 -0.10236675
0.06262993 0.16302516 -0.1538333 -0.07655141 0.14235222 0.00497586
0.13079578 0.01880324]
labels = [char for (ind, char) in tokenizer.index_word.items()]
labels.insert(0, None)
labels
[None,
'a',
'e',
'i',
'n',
'r',
'l',
'o',
't',
's',
'd',
'y',
'm',
'h',
'c',
'b',
'u',
'g',
'k',
'j',
'v',
'f',
'p',
'w',
'z',
'x',
'q',
'-',
' ',
"'"]
## Visulizing char embeddings via dimensional reduction techniques
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(char_vectors)
labels = labels
plt.figure(figsize=(10, 7), dpi=150)
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label,
xy=(x + 1, y + 1),
xytext=(0, 0),
textcoords='offset points')
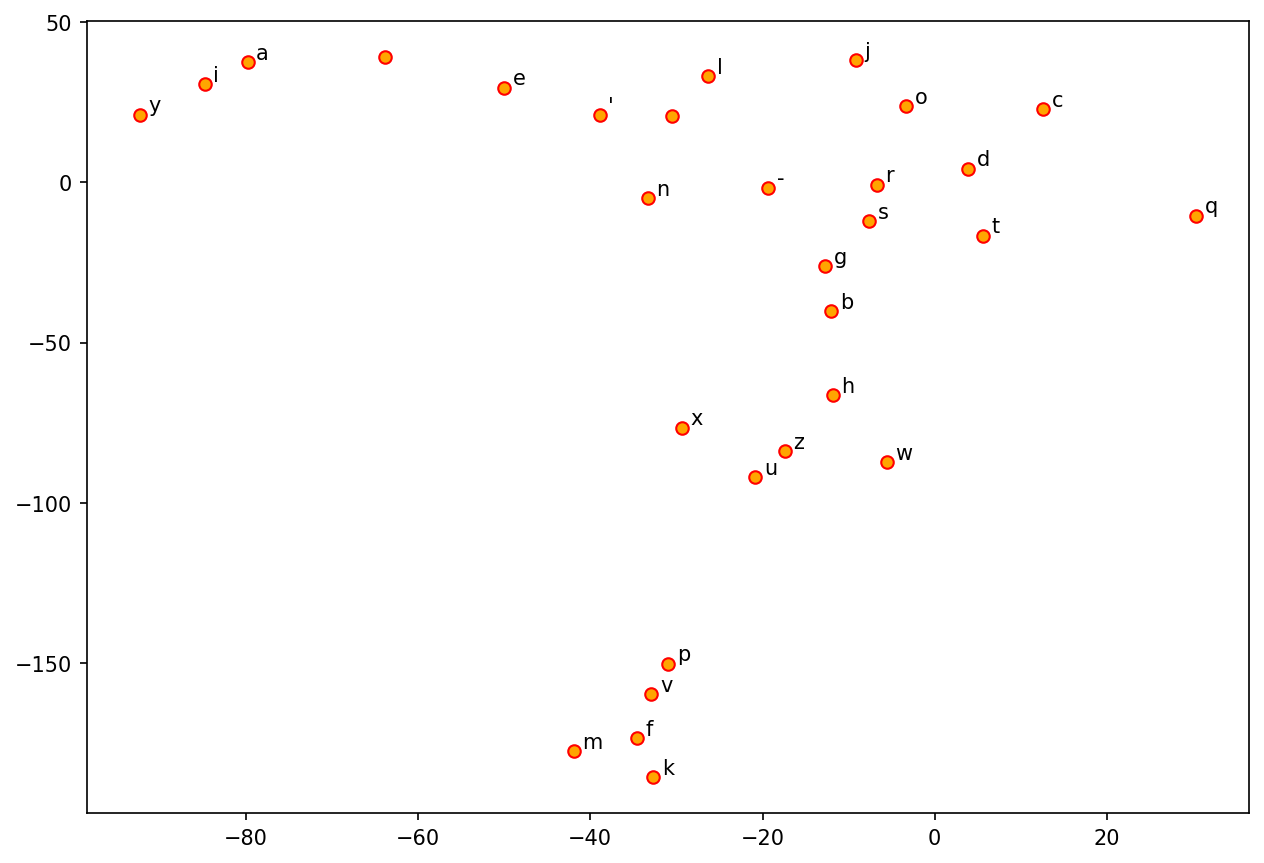
Issues of Word/Character Representations#
One-hot encoding does not indicate semantic relationships between characters.
For deep learning NLP, it is preferred to convert one-hot encodings of words/characters into embeddings, which are argued to include more semantic information of the tokens.
Now the question is how to train and create better word embeddings.
There are at least two alternatives:
We can train the embeddings along with our current NLP task.
We can use pre-trained embeddings from other unsupervised learning (transfer learning).
We will come back to this issue later.
Hyperparameter Tuning#
Note
Please install keras tuner module in your current conda:
pip install -U keras-tuner
or
conda install -c conda-forge keras-tuner
Like feature-based ML methods, neural networks also come with many hyperparameters, which require default values.
Typical hyperparameters include:
Number of nodes for the layer
Learning Rates
We can utilize the module,
keras-tuner, to fine-tune these hyperparameters (i.e., to find the values that optimize the model performance).
Steps for Keras Tuner
First, wrap the model definition in a function, which takes a single
hpargument.Inside this function, replace any value we want to tune with a call to hyperparameter sampling methods, e.g.
hp.Int()orhp.Choice(). The function should return a compiled model.Next, instantiate a
tunerobject specifying our optimization objective and other search parameters.Finally, start the search with the
search()method, which takes the same arguments asModel.fit()in keras.When the search is over, we can retrieve the best model and a summary of the results from the
tunner.
## Wrap model definition in a function
## and specify the parameters needed for tuning
# def build_model(hp):
# model1 = keras.Sequential()
# model1.add(keras.Input(shape=(max_len,)))
# model1.add(layers.Dense(hp.Int('units', min_value=32, max_value=128, step=32), activation="relu", name="dense_layer_1"))
# model1.add(layers.Dense(hp.Int('units', min_value=32, max_value=128, step=32), activation="relu", name="dense_layer_2"))
# model1.add(layers.Dense(2, activation="softmax", name="output"))
# model1.compile(
# optimizer=keras.optimizers.Adam(
# hp.Choice('learning_rate',
# values=[1e-2, 1e-3, 1e-4])),
# loss='sparse_categorical_crossentropy',
# metrics=['accuracy'])
# return model1
## wrap model definition and compiling
def build_model(hp):
m = Sequential()
m.add(
layers.Embedding(
input_dim=vocab_size,
output_dim=hp.Int(
'output_dim', ## tuning 2
min_value=32,
max_value=128,
step=32),
input_length=max_len,
mask_zero=True))
m.add(
layers.Bidirectional(
layers.LSTM(
hp.Int('units', min_value=16, max_value=64,
step=16), ## tuning 1
activation="relu",
dropout=0.2,
recurrent_dropout=0.2)))
m.add(layers.Dense(1, activation="sigmoid", name="output"))
m.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
return m
## This is to clean up the temp dir from the tuner
## Every time we re-start the tunner, it's better to keep the temp dir clean
if os.path.isdir('my_dir'):
shutil.rmtree('my_dir')
The
max_trialsvariable represents the maximum number of the hyperparameter combinations that will be tested by the tuner (because sometimes the combinations are too many and the max number can limit the time in fine-tuning).The
execution_per_trialvariable is the number of models that should be built and fit for each trial for robustness purposes (i.e., consistent results).
## Instantiate the tunner
import keras_tuner
tuner = keras_tuner.RandomSearch(build_model,
objective='val_accuracy',
max_trials=10,
executions_per_trial=2,
directory='my_dir')
## Check the tuner's search space
tuner.search_space_summary()
Show code cell output
Search space summary
Default search space size: 2
output_dim (Int)
{'default': None, 'conditions': [], 'min_value': 32, 'max_value': 128, 'step': 32, 'sampling': 'linear'}
units (Int)
{'default': None, 'conditions': [], 'min_value': 16, 'max_value': 64, 'step': 16, 'sampling': 'linear'}
%%time
## Start tuning with the tuner
tuner.search(X_train, y_train, validation_split=VALIDATION_SPLIT, batch_size=BATCH_SIZE)
Show code cell output
Trial 10 Complete [00h 00m 06s]
val_accuracy: 0.6302124261856079
Best val_accuracy So Far: 0.6309992074966431
Total elapsed time: 00h 01m 00s
INFO:tensorflow:Oracle triggered exit
CPU times: user 1min 11s, sys: 7.99 s, total: 1min 19s
Wall time: 59.9 s
## Retrieve the best models from the tuner
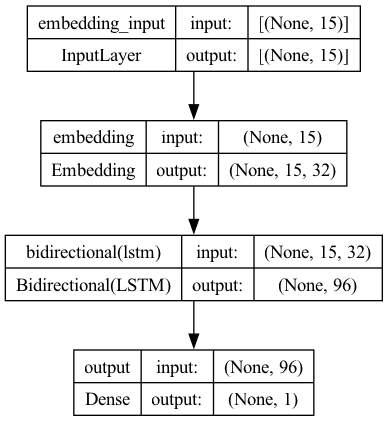
models = tuner.get_best_models(num_models=2)
plot_model(models[0], show_shapes=True)
## Retrieve the summary of results from the tuner
tuner.results_summary()
Results summary
Results in my_dir/untitled_project
Showing 10 best trials
Objective(name="val_accuracy", direction="max")
Trial 00 summary
Hyperparameters:
output_dim: 32
units: 48
Score: 0.6309992074966431
Trial 01 summary
Hyperparameters:
output_dim: 96
units: 16
Score: 0.6309992074966431
Trial 03 summary
Hyperparameters:
output_dim: 32
units: 32
Score: 0.6309992074966431
Trial 04 summary
Hyperparameters:
output_dim: 32
units: 16
Score: 0.6309992074966431
Trial 08 summary
Hyperparameters:
output_dim: 96
units: 32
Score: 0.6309992074966431
Trial 02 summary
Hyperparameters:
output_dim: 128
units: 64
Score: 0.6306058168411255
Trial 07 summary
Hyperparameters:
output_dim: 96
units: 48
Score: 0.6306058168411255
Trial 09 summary
Hyperparameters:
output_dim: 128
units: 32
Score: 0.6302124261856079
Trial 06 summary
Hyperparameters:
output_dim: 128
units: 16
Score: 0.6298190355300903
Trial 05 summary
Hyperparameters:
output_dim: 96
units: 64
Score: 0.6290322542190552
Explanation#
Train Model with the Tuned Hyperparameters#
EMBEDDING_DIM = 128
HIDDEN_STATE=32
model6 = Sequential()
model6.add(
layers.Embedding(input_dim=vocab_size,
output_dim=EMBEDDING_DIM,
input_length=max_len,
mask_zero=True))
model6.add(
layers.Bidirectional(
layers.LSTM(HIDDEN_STATE,
activation="relu",
name="lstm_layer",
dropout=0.2,
recurrent_dropout=0.5)))
model6.add(layers.Dense(1, activation="sigmoid", name="output"))
model6.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=["accuracy"])
plot_model(model6)
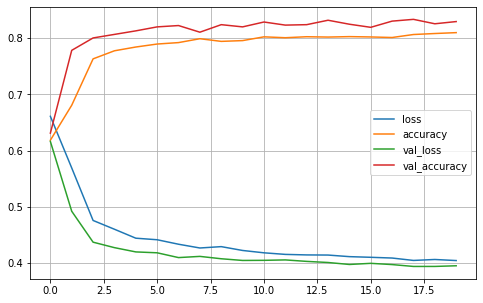
history6 = model6.fit(X_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=2,
validation_split=VALIDATION_SPLIT)
Epoch 1/20
40/40 - 3s - loss: 0.6609 - accuracy: 0.6184 - val_loss: 0.6163 - val_accuracy: 0.6310 - 3s/epoch - 72ms/step
Epoch 2/20
40/40 - 1s - loss: 0.5691 - accuracy: 0.6806 - val_loss: 0.4921 - val_accuracy: 0.7781 - 1s/epoch - 32ms/step
Epoch 3/20
40/40 - 1s - loss: 0.4758 - accuracy: 0.7630 - val_loss: 0.4372 - val_accuracy: 0.8002 - 1s/epoch - 33ms/step
Epoch 4/20
40/40 - 1s - loss: 0.4602 - accuracy: 0.7773 - val_loss: 0.4275 - val_accuracy: 0.8065 - 1s/epoch - 33ms/step
Epoch 5/20
40/40 - 1s - loss: 0.4443 - accuracy: 0.7840 - val_loss: 0.4199 - val_accuracy: 0.8127 - 1s/epoch - 36ms/step
Epoch 6/20
40/40 - 1s - loss: 0.4415 - accuracy: 0.7893 - val_loss: 0.4183 - val_accuracy: 0.8198 - 1s/epoch - 37ms/step
Epoch 7/20
40/40 - 1s - loss: 0.4335 - accuracy: 0.7919 - val_loss: 0.4098 - val_accuracy: 0.8222 - 1s/epoch - 37ms/step
Epoch 8/20
40/40 - 1s - loss: 0.4268 - accuracy: 0.7988 - val_loss: 0.4119 - val_accuracy: 0.8104 - 1s/epoch - 33ms/step
Epoch 9/20
40/40 - 1s - loss: 0.4293 - accuracy: 0.7941 - val_loss: 0.4077 - val_accuracy: 0.8238 - 1s/epoch - 34ms/step
Epoch 10/20
40/40 - 1s - loss: 0.4224 - accuracy: 0.7954 - val_loss: 0.4047 - val_accuracy: 0.8198 - 1s/epoch - 33ms/step
Epoch 11/20
40/40 - 1s - loss: 0.4183 - accuracy: 0.8021 - val_loss: 0.4049 - val_accuracy: 0.8285 - 1s/epoch - 36ms/step
Epoch 12/20
40/40 - 1s - loss: 0.4155 - accuracy: 0.8006 - val_loss: 0.4057 - val_accuracy: 0.8230 - 1s/epoch - 36ms/step
Epoch 13/20
40/40 - 1s - loss: 0.4145 - accuracy: 0.8023 - val_loss: 0.4030 - val_accuracy: 0.8238 - 1s/epoch - 35ms/step
Epoch 14/20
40/40 - 2s - loss: 0.4143 - accuracy: 0.8017 - val_loss: 0.4011 - val_accuracy: 0.8316 - 2s/epoch - 40ms/step
Epoch 15/20
40/40 - 2s - loss: 0.4115 - accuracy: 0.8025 - val_loss: 0.3976 - val_accuracy: 0.8245 - 2s/epoch - 39ms/step
Epoch 16/20
40/40 - 1s - loss: 0.4103 - accuracy: 0.8019 - val_loss: 0.3996 - val_accuracy: 0.8190 - 1s/epoch - 36ms/step
Epoch 17/20
40/40 - 1s - loss: 0.4090 - accuracy: 0.8009 - val_loss: 0.3974 - val_accuracy: 0.8301 - 1s/epoch - 35ms/step
Epoch 18/20
40/40 - 1s - loss: 0.4047 - accuracy: 0.8063 - val_loss: 0.3940 - val_accuracy: 0.8332 - 1s/epoch - 36ms/step
Epoch 19/20
40/40 - 1s - loss: 0.4064 - accuracy: 0.8080 - val_loss: 0.3941 - val_accuracy: 0.8253 - 1s/epoch - 33ms/step
Epoch 20/20
40/40 - 1s - loss: 0.4045 - accuracy: 0.8096 - val_loss: 0.3952 - val_accuracy: 0.8293 - 1s/epoch - 35ms/step
plot2(history6)
explainer = LimeTextExplainer(class_names=['female','male'], char_level=True)
## Creating a pipeline object for LIME
def model_predict_pipeline(text_list):
## text_list: a list of training tokens (1d)
## output: a [d, k] array, d = number of input strings; k = 2 (probs of the two classes)
## Note: To use `explainer.explain_instance`, we need a predictor, which takes a LIST of tokens as input, and returns a list of (1-x, x) class probablities
_seq = tokenizer.texts_to_sequences(text_list) ## treat the entire string as one unit
_seq_pad = keras.preprocessing.sequence.pad_sequences(_seq, maxlen=max_len)
_out_prob = model6.predict(_seq_pad)[:,0].tolist() ## predict() requires a 2d array as input and returns a 2D array
return np.array([[float(1-x), float(x)] for x in _out_prob])
#return model6.predict(np.array(_seq_pad))
text_id = 13
print(X_test_texts[text_id]) ## Suset of a specific string from a list
model_predict_pipeline([X_test_texts[text_id]]) ## Remember to convert STRING to LIST (length=1)
Crystal
1/1 [==============================] - 0s 191ms/step
array([[0.75932784, 0.24067216]])
exp = explainer.explain_instance(X_test_texts[text_id], ## requires a raw string
model_predict_pipeline, ## reqires a predictor with list as input
num_features=10,
top_labels=1)
157/157 [==============================] - 0s 2ms/step
exp.show_in_notebook(text=True)
y_test[text_id]
0
exp = explainer.explain_instance('Tim',
model_predict_pipeline,
num_features=10,
top_labels=1)
exp.show_in_notebook(text=True)
157/157 [==============================] - 0s 2ms/step
exp = explainer.explain_instance('Michaelis',
model_predict_pipeline,
num_features=10,
top_labels=1)
exp.show_in_notebook(text=True)
1/157 [..............................] - ETA: 2s
157/157 [==============================] - 0s 2ms/step
exp = explainer.explain_instance('Sidney',
model_predict_pipeline,
num_features=10,
top_labels=1)
exp.show_in_notebook(text=True)
157/157 [==============================] - 0s 2ms/step
exp = explainer.explain_instance('Timber',
model_predict_pipeline,
num_features=10,
top_labels=1)
exp.show_in_notebook(text=True)
157/157 [==============================] - 0s 2ms/step
exp = explainer.explain_instance('Alvin',
model_predict_pipeline,
num_features=10,
top_labels=1)
exp.show_in_notebook(text=True)
157/157 [==============================] - 0s 2ms/step
References#
Chollet (2017), Ch 3 and Ch 4