
Text Vectorization Using Traditional Methods#
Traditionally, in linguistic studies, experts would analyze text by manually labeling it with linguistic characteristics they deemed relevant. These labels are then converted into numeric values, making it easier to process the text computationally.
However, this approach requires a lot of manual effort. In statistical language processing, the focus is on automating this process by developing techniques to automatically convert text into numeric representations. One popular method for this is the bag-of-words approach, which we’ll explore in this tutorial.
Feature Engineering#
Feature engineering is the process of selecting, transforming, or creating features from raw text data to improve the performance of machine learning models. In the context of natural language processing (NLP), feature engineering involves converting textual data into a numerical format that machine learning algorithms can understand and process effectively.
The bag-of-words (BoW) model is a common (yet naive) technique used in feature engineering for NLP. It represents text data as a collection of unique words (or tokens) present in the corpus, ignoring grammar and word order. Each document in the corpus is then represented as a vector, where each dimension corresponds to a unique word in the vocabulary, and the value in each dimension represents the frequency or presence of that word in the document.
So, the connection between feature engineering and bag of words lies in the fact that the bag-of-words model is a method used in feature engineering to convert textual data into a structured numerical format that can be used as input for machine learning algorithms. It allows us to extract meaningful features from text data, making it suitable for tasks such as classification, clustering, and sentiment analysis.
Import necessary dependencies and settings#
# import warnings
# warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib
import matplotlib.pyplot as plt
## Default Style Settings
matplotlib.rcParams['figure.dpi'] = 150
pd.options.display.max_colwidth = 200
#%matplotlib inline
Sample Corpus of Text Documents#
To have a quick intuition of how bag-of-words work, we start with a naive corpus, which consists of only eight short documents. Each document is in fact a simple sentence.
Each document in the corpus has a label. Let’s assume that the label refers to the topic of each document.
## documents
corpus = [
'The sky is blue and beautiful.', 'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans",
'I love green eggs, ham, sausages and bacon!',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
]
## labels
labels = [
'weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather',
'animals'
]
## DF
corpus = np.array(corpus) # np.array better than list
corpus_df = pd.DataFrame({'Document': corpus, 'Category': labels})
corpus_df
| Document | Category | |
|---|---|---|
| 0 | The sky is blue and beautiful. | weather |
| 1 | Love this blue and beautiful sky! | weather |
| 2 | The quick brown fox jumps over the lazy dog. | animals |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food |
| 4 | I love green eggs, ham, sausages and bacon! | food |
| 5 | The brown fox is quick and the blue dog is lazy! | animals |
| 6 | The sky is very blue and the sky is very beautiful today | weather |
| 7 | The dog is lazy but the brown fox is quick! | animals |
Tip
In text processing, people often cast list into np.array for efficiency. A numpy array is a lot faster than the native list in Python.
If you are interested, please check this YouTube Numpy Crash Course.
Simple Text Preprocessing#
A few steps for text preprocessing
Remove special characters
Normalize letter case
Remove redundant spaces
Tokenize each document into word-tokens
Remove stop words
All these preprocessing steps are wrapped in one function,
normalize_document().
## Colab Only
nltk.download("stopwords")
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
True
wpt = nltk.WordPunctTokenizer()
stop_words = nltk.corpus.stopwords.words('english')
def normalize_document(doc):
"""
Normalize the document.
Parameters:
- doc (list): A list of documents
Returns:
list: a list of preprocessed documents
"""
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I | re.A)
doc = doc.lower()
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
# filter stopwords out of document
filtered_tokens = [token for token in tokens if token not in stop_words]
# re-create document from filtered tokens
doc = ' '.join(filtered_tokens)
return doc
normalize_corpus = np.vectorize(normalize_document)
norm_corpus = normalize_corpus(corpus)
print(corpus)
print("="*50)
print(norm_corpus)
['The sky is blue and beautiful.' 'Love this blue and beautiful sky!'
'The quick brown fox jumps over the lazy dog.'
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans"
'I love green eggs, ham, sausages and bacon!'
'The brown fox is quick and the blue dog is lazy!'
'The sky is very blue and the sky is very beautiful today'
'The dog is lazy but the brown fox is quick!']
==================================================
['sky blue beautiful' 'love blue beautiful sky'
'quick brown fox jumps lazy dog'
'kings breakfast sausages ham bacon eggs toast beans'
'love green eggs ham sausages bacon' 'brown fox quick blue dog lazy'
'sky blue sky beautiful today' 'dog lazy brown fox quick']
Bag of Words Model#
Bag-of-words model is the simplest way (i.e., easy to be automated) to vectorize texts into numeric representations.
In short, it is a method to represent a text using its word frequency list.

CountVectorizer() from sklearn#
from sklearn.feature_extraction.text import CountVectorizer
# get bag of words features in sparse format
cv = CountVectorizer(min_df=0., max_df=1.)
cv_matrix = cv.fit_transform(norm_corpus)
cv_matrix
<8x20 sparse matrix of type '<class 'numpy.int64'>'
with 42 stored elements in Compressed Sparse Row format>
# view non-zero feature positions in the sparse matrix
print(cv_matrix)
(0, 17) 1
(0, 3) 1
(0, 2) 1
(1, 17) 1
(1, 3) 1
(1, 2) 1
(1, 14) 1
(2, 15) 1
(2, 5) 1
(2, 8) 1
(2, 11) 1
(2, 13) 1
(2, 6) 1
(3, 12) 1
(3, 4) 1
(3, 16) 1
(3, 10) 1
(3, 0) 1
(3, 7) 1
(3, 18) 1
(3, 1) 1
(4, 14) 1
(4, 16) 1
(4, 10) 1
(4, 0) 1
(4, 7) 1
(4, 9) 1
(5, 3) 1
(5, 15) 1
(5, 5) 1
(5, 8) 1
(5, 13) 1
(5, 6) 1
(6, 17) 2
(6, 3) 1
(6, 2) 1
(6, 19) 1
(7, 15) 1
(7, 5) 1
(7, 8) 1
(7, 13) 1
(7, 6) 1
# view dense representation
# warning might give a memory error if data is too big
cv_matrix = cv_matrix.toarray()
cv_matrix
array([[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0],
[1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0],
[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 1],
[0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0]])
# get all unique words in the corpus
vocab = cv.get_feature_names_out()
# show document feature vectors
pd.DataFrame(cv_matrix, columns=vocab)
| bacon | beans | beautiful | blue | breakfast | brown | dog | eggs | fox | green | ham | jumps | kings | lazy | love | quick | sausages | sky | toast | today | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 1 |
| 7 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
Issues with Bag-of-Words Text Representation
Word order is ignored.
Raw absolute frequency counts of words do not necessarily represent the meaning of the text properly.
Marginal frequencies play important roles. (Row and Columns)
Improving Bag-of-Words Text Representation#
To enhance the Bag of Words (BOW) representation of texts, we can consider the following approaches:
Utilize n-grams: Instead of just using individual words (unigrams), we can include sequences of words (n-grams) in the BOW model. This helps capture partial word order information in the text, which can provide richer semantics.
Filter words: We can filter out words based on certain criteria such as their distributional characteristics (e.g., term frequencies, document frqeuencies) or morphosyntactic patterns (e.g., morphological endings). This can help remove noisy or irrelevant words from the BOW representation, making it more focused on the essential semantic content.
Weighting: Instead of just counting the frequency of each word in the text, we can apply weights to the raw frequency counts. Various weighting schemes such as Term Frequency-Inverse Document Frequency (TF-IDF) can be employed to assign higher weights to words that are more informative and less common across the entire corpus. This helps prioritize important words and downplay the significance of common words that may not carry much semantic meaning.
In CountVectorizer(), we can utilize its parameters:
max_df: When building the vocabulary, the vectorizer will ignore terms that have a document frequency strictly higher than the given threshold (corpus-specific stop words).float= the parameter represents a proportion of documents;integer= absolute counts.min_df: When building the vocabulary, the vectorizer will ignore terms that have a document frequency strictly lower than the given threshold.float= the parameter represents a proportion of documents;integer= absolute counts.max_features: Build a vocabulary that only consider the topmax_featuresordered by term frequency across the corpus.ngram_range: The lower and upper boundary of the range of n-values for different word n-grams.tuple(min_n, max_n), default=(1, 1).token_pattern: Regular expression denoting what constitutes a “token” in vocabulary. The default regexp select tokens of 2 or more alphanumeric characters (Note: punctuation is completely ignored and always treated as a token separator). If there is a capturing group in token_pattern then the captured group content, not the entire match, becomes the token. At most one capturing group is permitted.
Warning
The token_pattern parameter in CountVectorizer is crucial for specifying the pattern used to extract tokens (words) from the text data. By default, token_pattern is set to a regular expression that captures words consisting of 2 or more alphanumeric characters. This default setting works well for English text where words are typically separated by whitespace and punctuation.
However, when working with languages like Chinese, where words are not separated by whitespace, it becomes necessary to adjust the token_pattern parameter to ensure that the tokenizer recognizes the individual words correctly. In the case of Chinese text data that has been word-segmented (i.e., split into individual words), specifying the appropriate token_pattern is essential for preserving the integrity of the original word tokens.
Without specifying the token_pattern, the default behavior of CountVectorizer may not correctly identify the segmented words in Chinese text, leading to incorrect tokenization and potentially impacting the accuracy of the analysis or modeling tasks performed using the vectorized data.
import jieba
## raw corpus (list)
corpus_zh = [
'對這個世界如果你有太多的抱怨',
'跌倒了就不敢繼續往前走',
'為什麼人要這麼的脆弱墮落',
'請你打開電視看看',
'多少人為生命在努力勇敢的走下去',
'我們是不是該知足',
'珍惜一切就算沒有擁有'
]
## np.array
corpus_zh = np.array(corpus_zh)
## vectorize
cv_zh = CountVectorizer(min_df=0., max_df=1.)
cv_zh_matrix = cv_zh.fit_transform(corpus_zh)
# get all unique words in the corpus
vocab = cv_zh.get_feature_names_out()
print(vocab)
['多少人為生命在努力勇敢的走下去' '對這個世界如果你有太多的抱怨' '我們是不是該知足' '為什麼人要這麼的脆弱墮落' '珍惜一切就算沒有擁有'
'請你打開電視看看' '跌倒了就不敢繼續往前走']
## Define language/task-specific word tokenizer
def jieba_tokenizer(text):
# Use Jieba to tokenize the text
tokens = jieba.lcut(text)
return list(tokens)
## vectorizer with self-defined tokenizer
cv_zh = CountVectorizer(min_df=0., max_df=1.,
tokenizer = jieba_tokenizer)
cv_zh_matrix = cv_zh.fit_transform(corpus_zh)
# get all unique words in the corpus
vocab = cv_zh.get_feature_names_out()
print(vocab)
/Users/alvinchen/anaconda3/envs/python-notes/lib/python3.9/site-packages/sklearn/feature_extraction/text.py:525: UserWarning: The parameter 'token_pattern' will not be used since 'tokenizer' is not None'
warnings.warn(
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/70/qfdgs0k52qj24jtjcz7d0dkm0000gn/T/jieba.cache
Loading model cost 0.261 seconds.
Prefix dict has been built successfully.
['一切' '下去' '不敢' '世界' '了' '人為' '人要' '什麼' '你' '努力' '勇敢' '在' '墮落' '多' '多少'
'太' '如果' '對' '就' '就算' '往前走' '我們' '打' '抱怨' '擁有' '是不是' '有' '沒有' '為' '珍惜'
'生命' '的' '看看' '知足' '繼續' '脆弱' '該' '請' '走' '跌倒' '這個' '這麼' '開電視']
N-gram Bag-of-Words Text Representation#
# you can set the n-gram range to 1,2 to get unigrams as well as bigrams
bv = CountVectorizer(ngram_range=(2, 2))
bv_matrix = bv.fit_transform(norm_corpus)
bv_matrix = bv_matrix.toarray()
vocab = bv.get_feature_names_out()
pd.DataFrame(bv_matrix, columns=vocab)
| bacon eggs | beautiful sky | beautiful today | blue beautiful | blue dog | blue sky | breakfast sausages | brown fox | dog lazy | eggs ham | ... | lazy dog | love blue | love green | quick blue | quick brown | sausages bacon | sausages ham | sky beautiful | sky blue | toast beans | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
8 rows × 29 columns
TF-IDF Model#
TF-IDF model is an extension of the bag-of-words model, whose main objective is to adjust the raw frequency counts of the lexical features by considering the dispersion of the words in the corpus.
Disperson refers to how evenly each word/term is distributed across different documents of the corpus.
Interaction between Word Raw Frequency Counts and Dispersion:
Given a high-frequency word:
If the word is widely dispersed across different documents of the corpus (i.e., high dispersion)
it is more likely to be semantically general.
If the word is mostly centralized in a limited set of documents in the corpus (i.e., low dispersion)
it is more likely to be topic-specific.
Dispersion rates of words can be used as weights for the importance of word frequency counts.
Document Frequency (DF) is an intuitive metric for measuring word dispersion across the corpus. DF refers to the number of documents where the word occurs (at least once).
The inverse of the DF is referred to as Inverse Document Frequency (IDF). IDF is usually computed as follows:
Note
All these plus-1’s in the above formula are to avoid potential division-by-zero errors.
The raw absolute frequency counts of words in the BOW model are referred to as Term Frequency (TF).
The TF-IDF Weighting Scheme:
The
tfidfis normalized using the L2 norm, i.e., the Euclidean norm (taking the square root of the sum of the square oftfidfmetrics).
See also
The L1 and L2 norms are mathematical techniques used in machine learning for regularization, specifically in the context of linear models like linear regression or logistic regression. They are used to penalize the size of the coefficients (weights) of the model to prevent overfitting and improve generalization performance.
L1 Norm (Lasso Regularization):
The L1 norm calculates the absolute values of the coefficients and sums them up. It is also known as the Manhattan distance or taxicab norm.
The L1 norm tends to drive some weights to exactly 0 during the optimization process. This induces sparsity in the weights, meaning that some features are completely ignored in the model. As a result, L1 regularization can be beneficial for memory efficiency and feature selection. It helps in reducing the model complexity by eliminating irrelevant features and focusing only on the most important ones.
L2 Norm (Ridge Regularization):
The L2 norm calculates the square of the coefficients, sums them up, and takes the square root of the result. It is also known as the Euclidean distance or the Frobenius norm.
Unlike the L1 norm, the L2 norm does not force the weights to be exactly 0 but instead reduces them towards 0. It penalizes large weights more severely than small ones, but it rarely forces them to be exactly 0.
The L2 norm regularization is less aggressive in inducing sparsity compared to L1 regularization. It is generally used when we want to retain all parameters and avoid overfitting by preventing any of the weights from becoming too large.
In summary, L1 regularization tends to produce sparse models by driving some coefficients to exactly 0, while L2 regularization reduces the magnitude of all coefficients without necessarily eliminating any of them. The choice between L1 and L2 regularization depends on the specific problem and the desired properties of the resulting model.
The L1 norm will drive some weights to 0, inducing sparsity in the weights. This can be beneficial for memory efficiency or when feature selection is needed (i.e., we want to select only certain weights).
The L2 norm instead will reduce all weights but not all the way to 0. This is less memory efficient but can be useful if we want/need to retain all parameters.
TfidfTransformer() from sklearn#
from sklearn.feature_extraction.text import TfidfTransformer
tt = TfidfTransformer(norm='l2', use_idf=True, smooth_idf=True)
tt_matrix = tt.fit_transform(cv_matrix)
tt_matrix = tt_matrix.toarray()
vocab = cv.get_feature_names_out()
pd.DataFrame(np.round(tt_matrix, 2), columns=vocab)
| bacon | beans | beautiful | blue | breakfast | brown | dog | eggs | fox | green | ham | jumps | kings | lazy | love | quick | sausages | sky | toast | today | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.60 | 0.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.60 | 0.00 | 0.0 |
| 1 | 0.00 | 0.00 | 0.49 | 0.43 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.57 | 0.00 | 0.00 | 0.49 | 0.00 | 0.0 |
| 2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.38 | 0.38 | 0.00 | 0.38 | 0.00 | 0.00 | 0.53 | 0.00 | 0.38 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 | 0.0 |
| 3 | 0.32 | 0.38 | 0.00 | 0.00 | 0.38 | 0.00 | 0.00 | 0.32 | 0.00 | 0.00 | 0.32 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 | 0.32 | 0.00 | 0.38 | 0.0 |
| 4 | 0.39 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.39 | 0.00 | 0.47 | 0.39 | 0.00 | 0.00 | 0.00 | 0.39 | 0.00 | 0.39 | 0.00 | 0.00 | 0.0 |
| 5 | 0.00 | 0.00 | 0.00 | 0.37 | 0.00 | 0.42 | 0.42 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 0.42 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.0 |
| 6 | 0.00 | 0.00 | 0.36 | 0.32 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.72 | 0.00 | 0.5 |
| 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.45 | 0.45 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.00 | 0.45 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.0 |
TfidfVectorizer() from sklearn#
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(min_df=0.,
max_df=1.,
norm='l2',
use_idf=True,
smooth_idf=True)
tv_matrix = tv.fit_transform(norm_corpus)
tv_matrix = tv_matrix.toarray()
vocab = tv.get_feature_names_out()
pd.DataFrame(np.round(tv_matrix, 2), columns=vocab)
| bacon | beans | beautiful | blue | breakfast | brown | dog | eggs | fox | green | ham | jumps | kings | lazy | love | quick | sausages | sky | toast | today | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.60 | 0.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.60 | 0.00 | 0.0 |
| 1 | 0.00 | 0.00 | 0.49 | 0.43 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.57 | 0.00 | 0.00 | 0.49 | 0.00 | 0.0 |
| 2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.38 | 0.38 | 0.00 | 0.38 | 0.00 | 0.00 | 0.53 | 0.00 | 0.38 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 | 0.0 |
| 3 | 0.32 | 0.38 | 0.00 | 0.00 | 0.38 | 0.00 | 0.00 | 0.32 | 0.00 | 0.00 | 0.32 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 | 0.32 | 0.00 | 0.38 | 0.0 |
| 4 | 0.39 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.39 | 0.00 | 0.47 | 0.39 | 0.00 | 0.00 | 0.00 | 0.39 | 0.00 | 0.39 | 0.00 | 0.00 | 0.0 |
| 5 | 0.00 | 0.00 | 0.00 | 0.37 | 0.00 | 0.42 | 0.42 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 0.42 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.0 |
| 6 | 0.00 | 0.00 | 0.36 | 0.32 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.72 | 0.00 | 0.5 |
| 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.45 | 0.45 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.00 | 0.45 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.0 |
Intuition of TF-IDF (Self-Study)#
The following shows the creation and computation of the TFIDF matrix step by step. Please go over the codes on your own if you are interested.
Create Vocabulary Dictionary of the Corpus#
# get unique words as feature names
unique_words = list(
set([word for doc in [doc.split() for doc in norm_corpus]
for word in doc]))
# default dict
def_feature_dict = {w: 0 for w in unique_words}
print('Feature Names:', unique_words)
print('Default Feature Dict:', def_feature_dict)
Feature Names: ['jumps', 'sky', 'dog', 'today', 'lazy', 'kings', 'breakfast', 'sausages', 'brown', 'blue', 'love', 'beautiful', 'beans', 'eggs', 'fox', 'toast', 'green', 'quick', 'ham', 'bacon']
Default Feature Dict: {'jumps': 0, 'sky': 0, 'dog': 0, 'today': 0, 'lazy': 0, 'kings': 0, 'breakfast': 0, 'sausages': 0, 'brown': 0, 'blue': 0, 'love': 0, 'beautiful': 0, 'beans': 0, 'eggs': 0, 'fox': 0, 'toast': 0, 'green': 0, 'quick': 0, 'ham': 0, 'bacon': 0}
Create Document-Word Matrix (Bag-of-Word Frequencies)#
from collections import Counter
# build bag of words features for each document - term frequencies
bow_features = []
for doc in norm_corpus:
bow_feature_doc = Counter(doc.split())
# initialize default corpus dictionary
all_features = Counter(def_feature_dict)
# update default dict with current doc words
bow_feature_doc.update(all_features)
# append cur doc dict
bow_features.append(bow_feature_doc)
bow_features = pd.DataFrame(bow_features)
bow_features
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| 5 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 6 | 2 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
Compute Document Frequency of Words#
import scipy.sparse as sp
feature_names = list(bow_features.columns)
# build the document frequency matrix
df = np.diff(sp.csc_matrix(bow_features, copy=True).indptr)
# `csc_matrix()` compress `bow_features` into sparse matrix based on columns
# `csc_matrix.indices` stores the matrix value indices in each column
# `csc_matrix.indptr` stores the accumulative numbers of values from column-0 to the right-most column
df = 1 + df # adding 1 to smoothen idf later
# show smoothened document frequencies
pd.DataFrame([df], columns=feature_names)
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 5 | 4 | 2 | 4 | 2 | 4 | 2 | 2 | 3 | 4 | 3 | 2 | 3 | 4 | 2 | 2 | 4 | 3 | 3 |
Create Inverse Document Frequency of Words#
# compute inverse document frequencies for each term
total_docs = 1 + len(norm_corpus)
idf = 1.0 + np.log(float(total_docs) / df)
# show smoothened idfs
pd.DataFrame([np.round(idf, 2)], columns=feature_names)
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.81 | 1.59 | 1.81 | 2.5 | 1.81 | 2.5 | 1.81 | 2.5 | 2.5 | 2.1 | 1.81 | 2.1 | 2.5 | 2.1 | 1.81 | 2.5 | 2.5 | 1.81 | 2.1 | 2.1 |
Compute Raw TF-IDF for Each Document#
# compute tfidf feature matrix
tf = np.array(bow_features, dtype='float64')
tfidf = tf * idf ## `tf.shape` = (8,20), `idf.shape`=(20,)
# view raw tfidf feature matrix
pd.DataFrame(np.round(tfidf, 2), columns=feature_names)
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.81 | 1.59 | 1.81 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 |
| 1 | 1.81 | 1.59 | 1.81 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 2.1 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 |
| 2 | 0.00 | 0.00 | 0.00 | 2.5 | 1.81 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 |
| 3 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.0 | 0.00 | 2.5 | 2.5 | 2.1 | 0.00 | 0.0 | 2.5 | 2.1 | 0.00 | 2.5 | 0.0 | 0.00 | 2.1 | 2.1 |
| 4 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 2.1 | 0.00 | 2.1 | 0.0 | 2.1 | 0.00 | 0.0 | 2.5 | 0.00 | 2.1 | 2.1 |
| 5 | 0.00 | 1.59 | 0.00 | 0.0 | 1.81 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 |
| 6 | 3.62 | 1.59 | 1.81 | 0.0 | 0.00 | 2.5 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 |
| 7 | 0.00 | 0.00 | 0.00 | 0.0 | 1.81 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 | 1.81 | 0.0 | 0.0 |
Get L2 Norms of TF-IDF#
from numpy.linalg import norm
# compute L2 norms
norms = norm(tfidf, axis=1) # get the L2 forms of tfidf according to columns
# print norms for each document
print(np.round(norms, 3))
[3.013 3.672 4.761 6.534 5.319 4.35 5.019 4.049]
Compute Normalized TF-IDF for Each Document#
# compute normalized tfidf
norm_tfidf = tfidf / norms[:, None]
# show final tfidf feature matrix
pd.DataFrame(np.round(norm_tfidf, 2), columns=feature_names)
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.60 | 0.53 | 0.60 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 0.49 | 0.43 | 0.49 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.57 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.00 | 0.00 | 0.53 | 0.38 | 0.0 | 0.38 | 0.00 | 0.00 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 | 0.38 | 0.00 | 0.00 | 0.38 | 0.00 | 0.00 |
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.38 | 0.38 | 0.32 | 0.00 | 0.00 | 0.38 | 0.32 | 0.00 | 0.38 | 0.00 | 0.00 | 0.32 | 0.32 |
| 4 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 | 0.00 | 0.39 | 0.00 | 0.39 | 0.00 | 0.39 | 0.00 | 0.00 | 0.47 | 0.00 | 0.39 | 0.39 |
| 5 | 0.00 | 0.37 | 0.00 | 0.00 | 0.42 | 0.0 | 0.42 | 0.00 | 0.00 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.42 | 0.00 | 0.00 | 0.42 | 0.00 | 0.00 |
| 6 | 0.72 | 0.32 | 0.36 | 0.00 | 0.00 | 0.5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.45 | 0.0 | 0.45 | 0.00 | 0.00 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.45 | 0.00 | 0.00 | 0.45 | 0.00 | 0.00 |
new_doc = 'the sky is green today'
pd.DataFrame(np.round(tv.transform([new_doc]).toarray(), 2),
columns=tv.get_feature_names_out())
| bacon | beans | beautiful | blue | breakfast | brown | dog | eggs | fox | green | ham | jumps | kings | lazy | love | quick | sausages | sky | toast | today | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.63 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.46 | 0.0 | 0.63 |
Document Similarity#
Now each document in our corpus has been transformed into a vectorized representation using the naive Bag-of-Words method.
And we believe that these vectorized representations are indicators of textual semantics.
This vectorized text vectorization allows us to perform mathematical computation of the semantic relationships between documents.
Similarity/Distance Metrics and Intuition#
Take a two-dimensional space for instance. If we have vectors on this space, we can compute their distance/similarity mathematically:
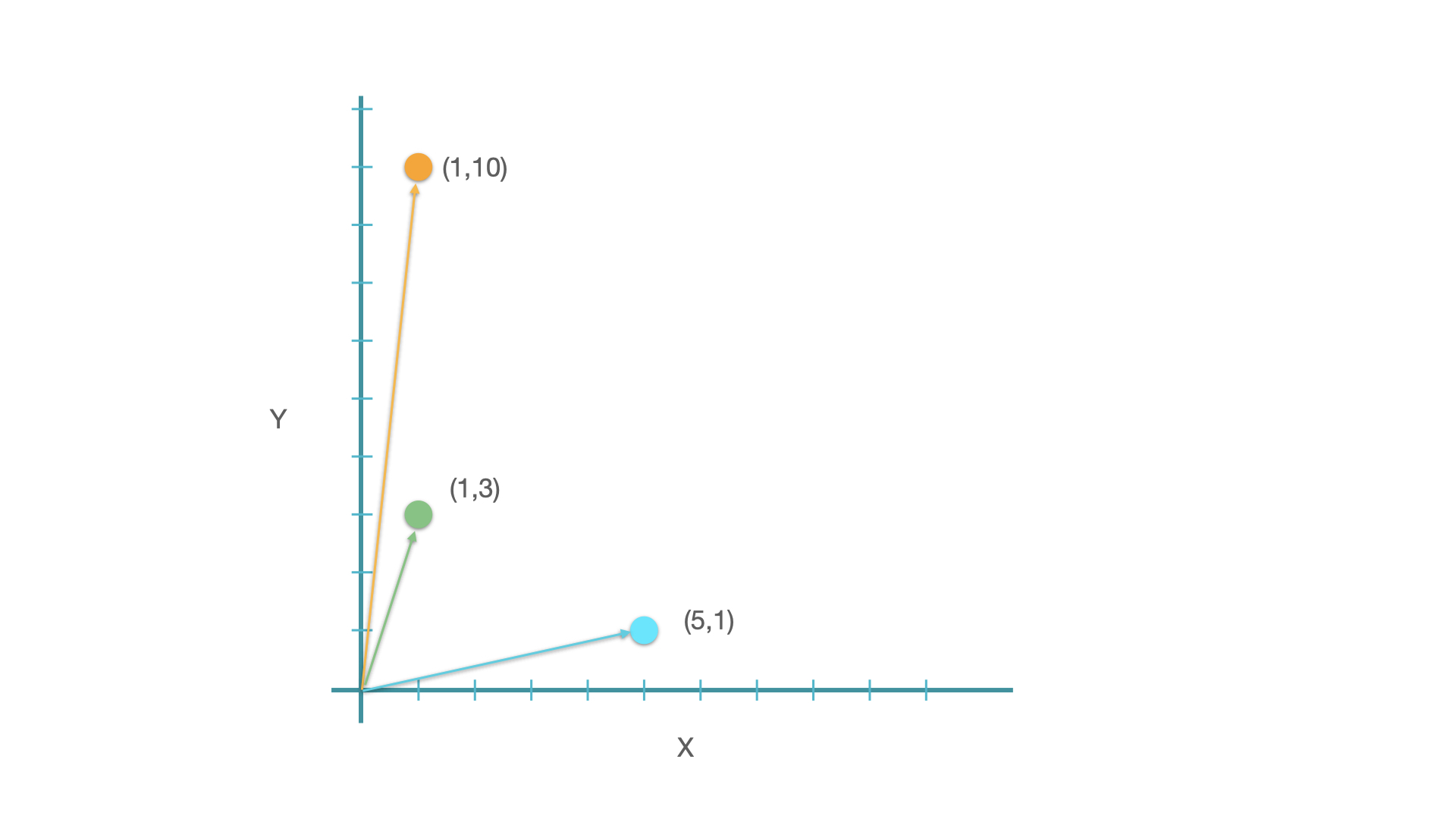
from sklearn.metrics.pairwise import manhattan_distances, euclidean_distances, cosine_similarity
xyz = np.array([[1, 9], [1, 3], [5, 1]])
xyz
array([[1, 9],
[1, 3],
[5, 1]])
In Math, there are in general two types of metrics to measure the relationship between vectors: distance-based vs. similarity-based metrics.
Distance-based Metrics#
Many distance measures of vectors are based on the following formula and differ in individual parameter settings.
The n in the above formula refers to the number of dimensions of the vectors. (In other words, all the concepts we discuss here can be easily extended to vectors in multidimensional spaces.)
When y is set to 2, it computes the famous Euclidean distance of two vectors, i.e., the direct spatial distance between two points on the n-dimensional space.
euclidean_distances(xyz)
array([[0. , 6. , 8.94427191],
[6. , 0. , 4.47213595],
[8.94427191, 4.47213595, 0. ]])
The geometrical meanings of the Euclidean distance are easy to conceptualize.
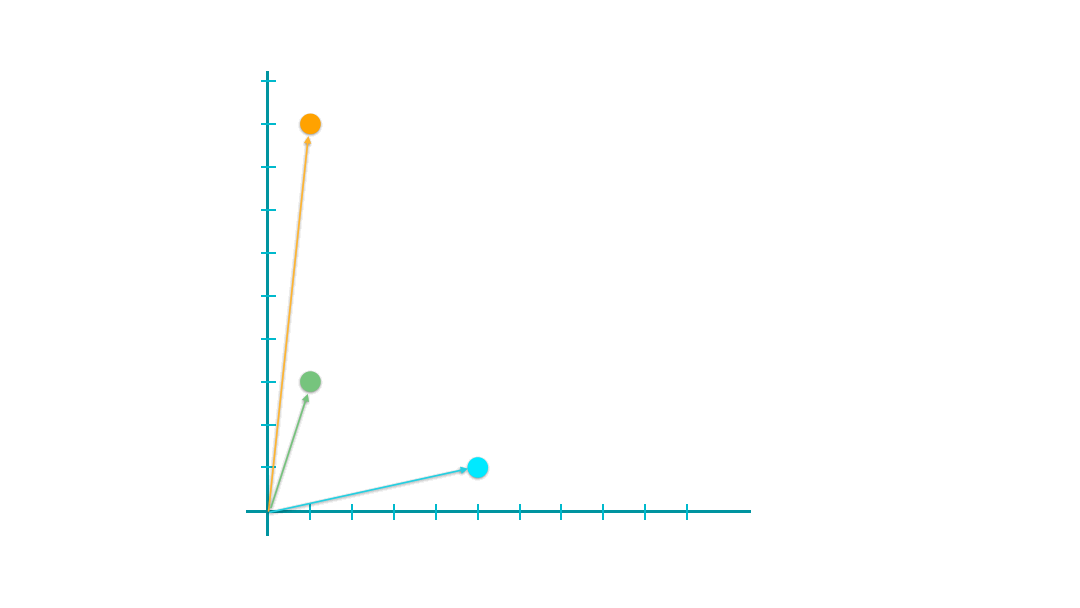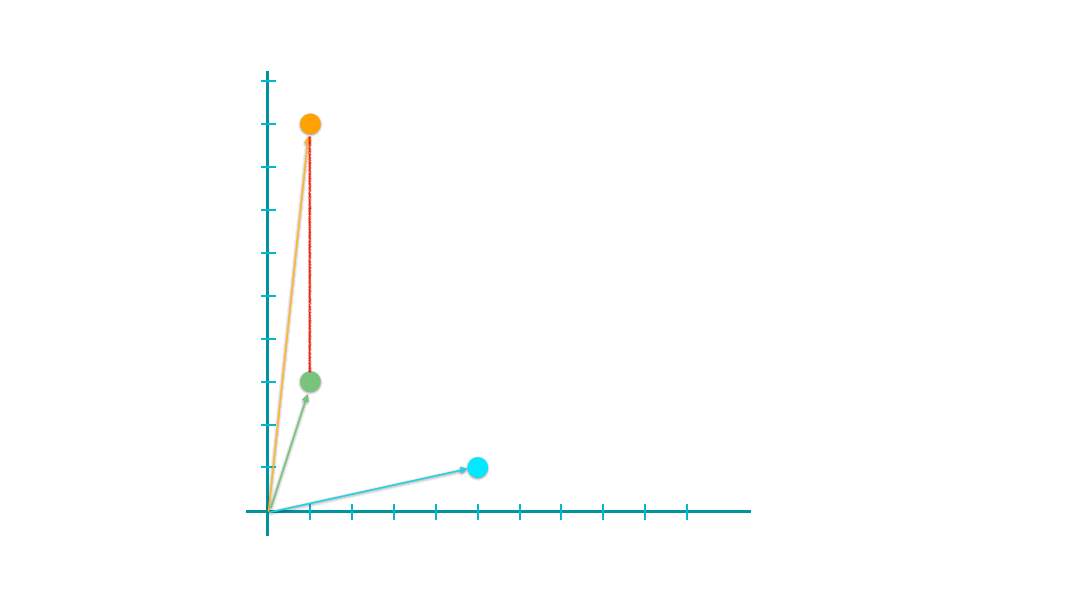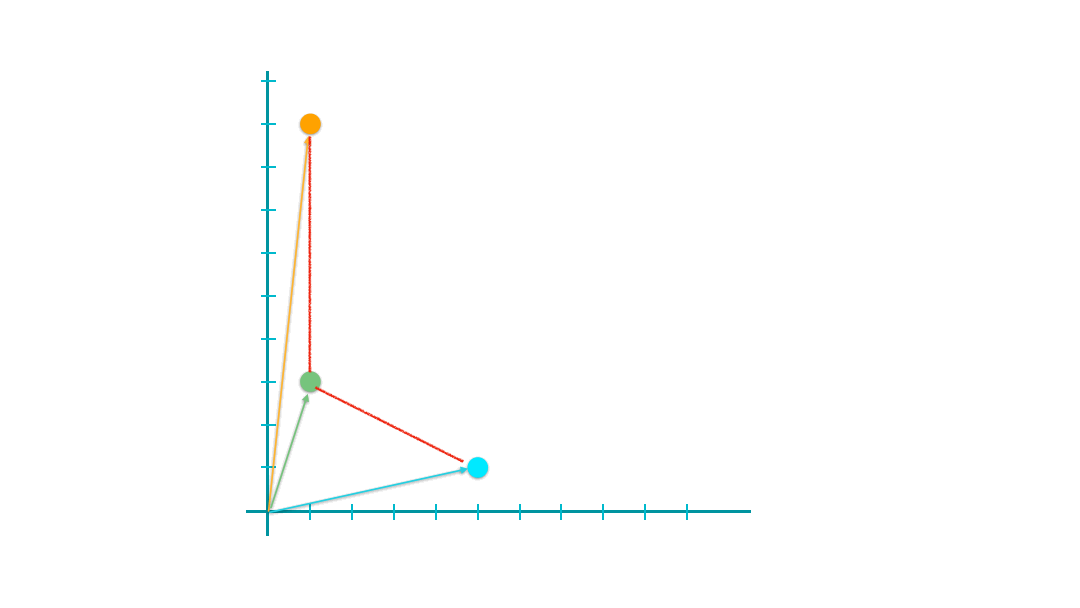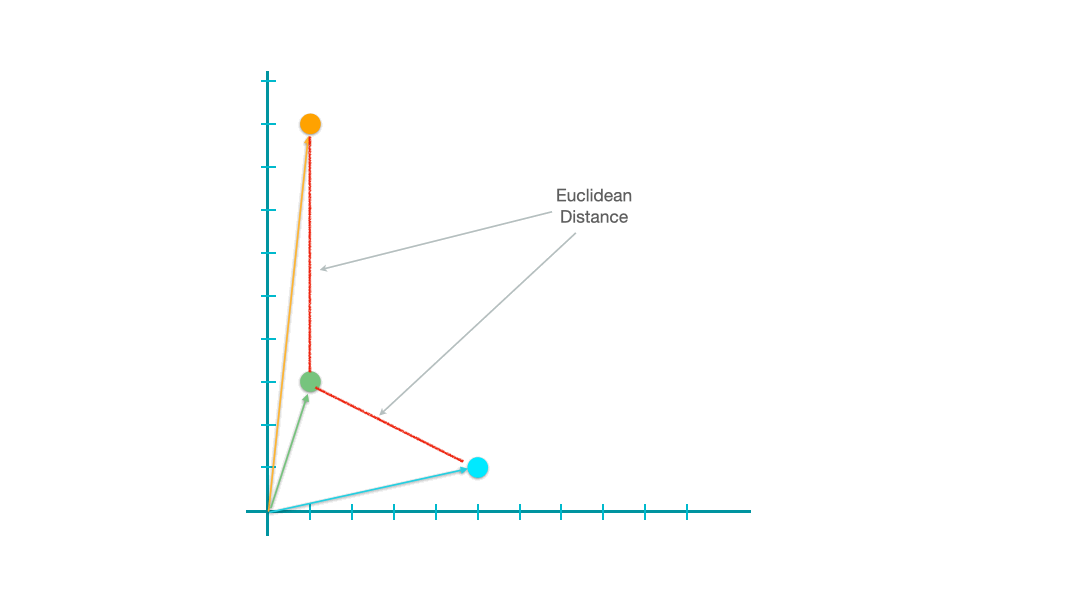
Similarity-based Metrics#
In addition to distance-based metrics, the other type is similarity-based metric, which often utilizes the idea of correlations.
The most commonly used one is Cosine Similarity, which can be computed as follows:
cosine_similarity(xyz)
array([[1. , 0.97780241, 0.30320366],
[0.97780241, 1. , 0.49613894],
[0.30320366, 0.49613894, 1. ]])
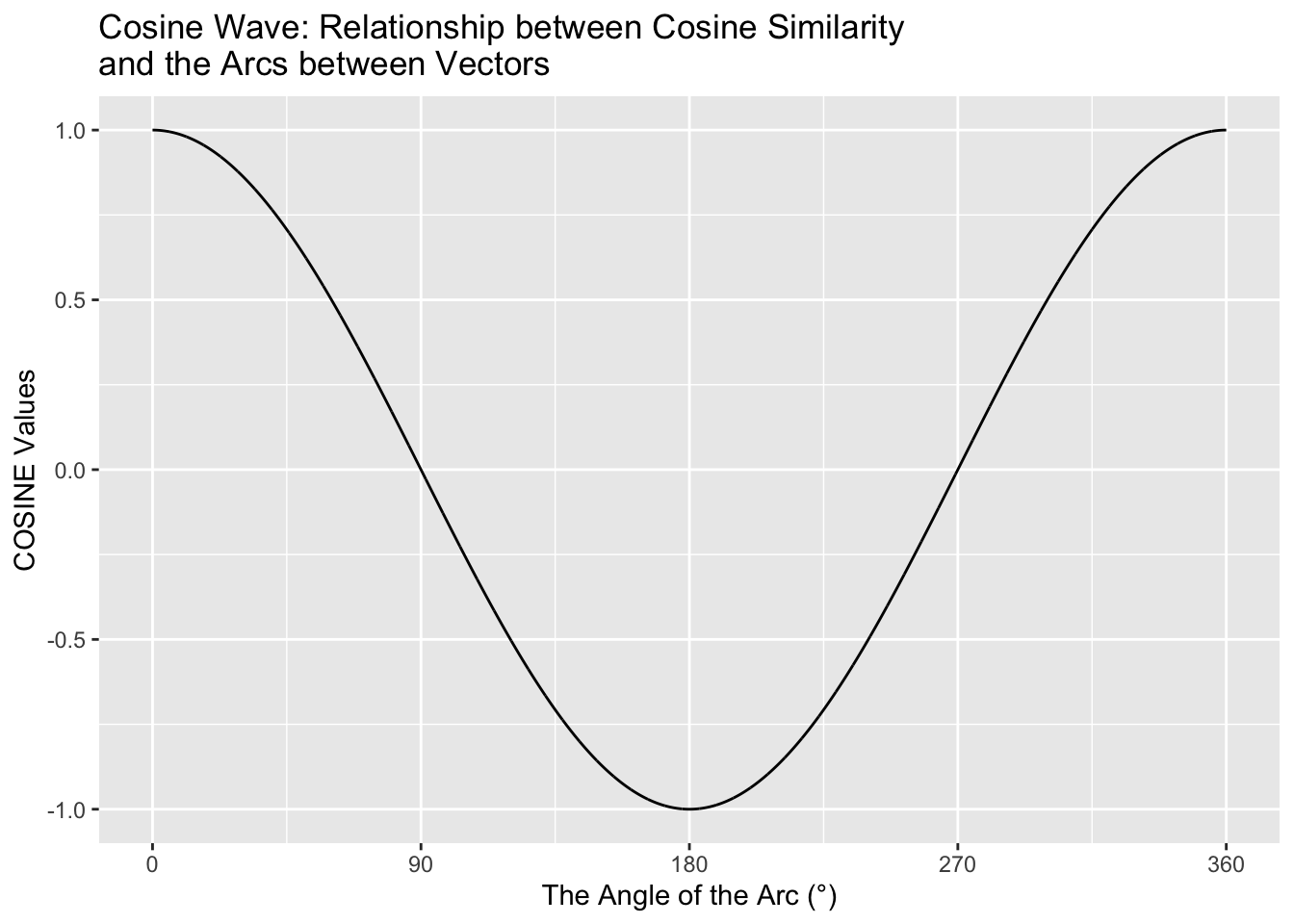
The geometric meanings of cosines of two vectors are connected to the arcs between the vectors.
The greater their cosine similarity, the smaller the arcs, the closer (i.e., the more similar) they are.
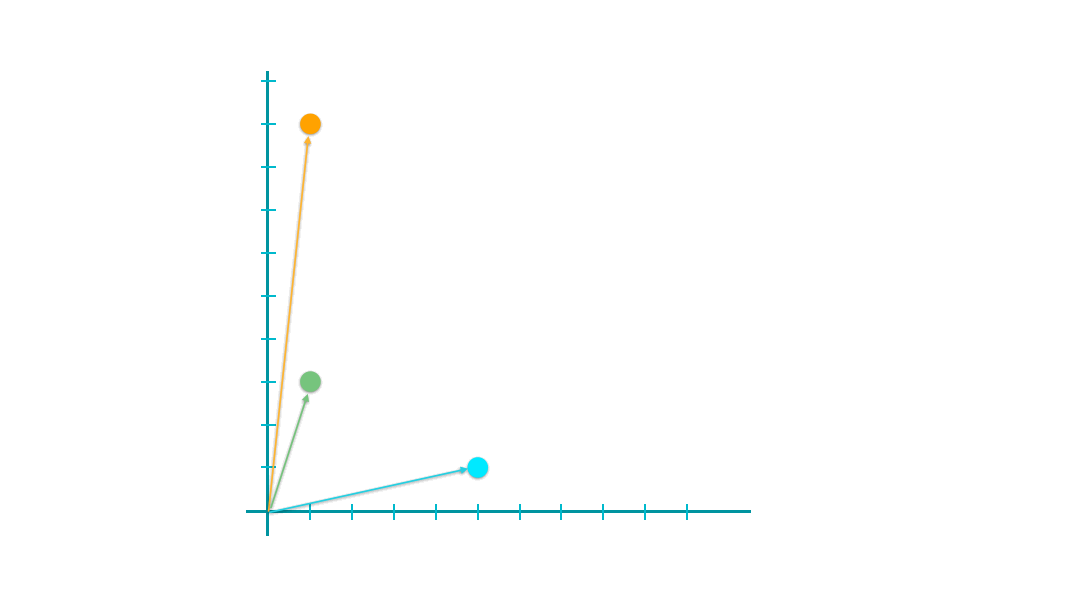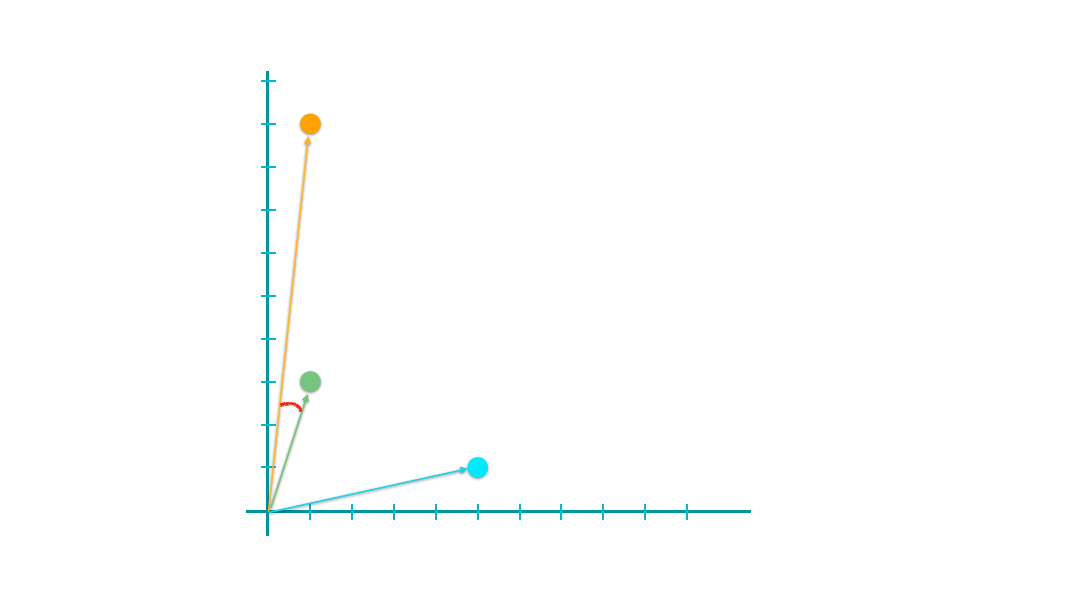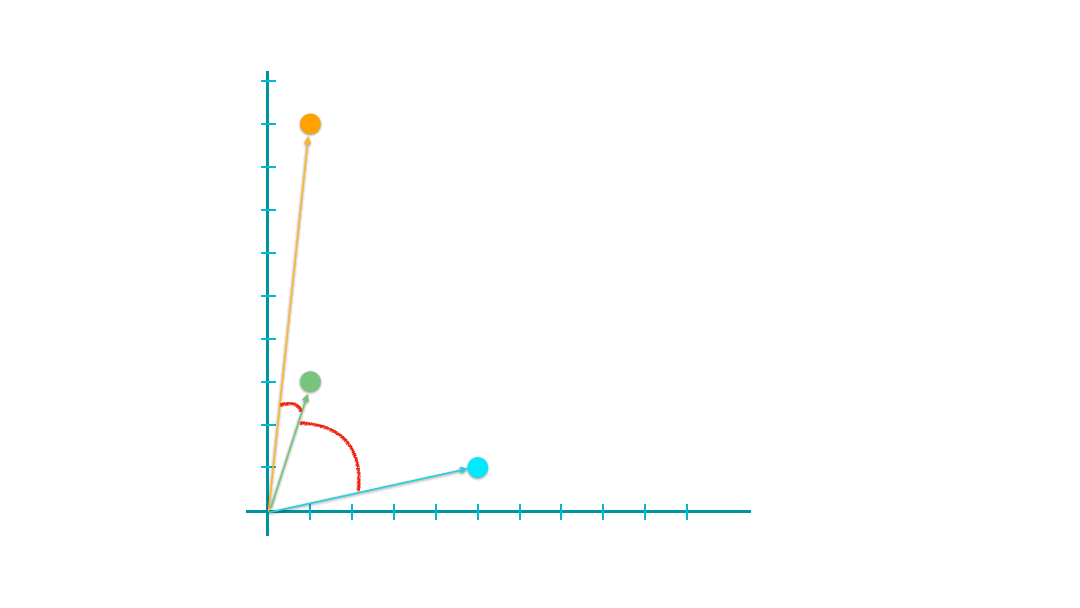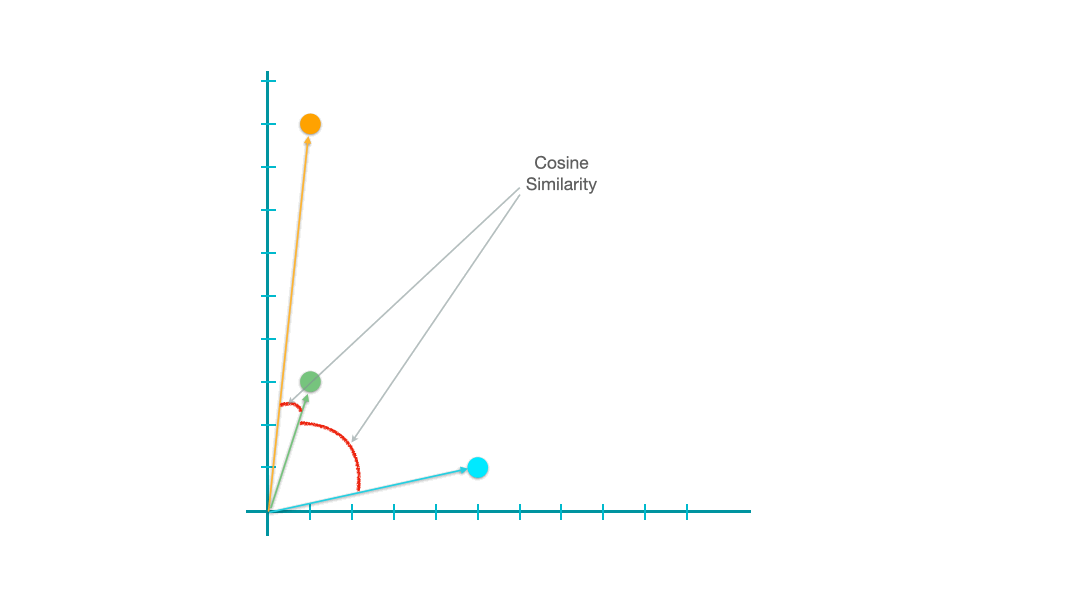
Which Metrics to Use then?#
Please note that different metrics may lead to very different results.
In our earlier examples, if we adopt euclidean distance, then y is closer to z than is to x.
But if we adopt cosine similarity, then y is closer to x than is to z.
The choice of distance/similarity metrics depends on:
Whether the magnitude of value differences on each dimension of the vectors matters (distance-based preferred)
Whether the values of each dimension of the vectors co-vary (cosine referred)
Pairwise Similarity Computation#
The
cosine_similarityautomatically computes the pairwise similarities between the rows of the input matrix.
similarity_doc_matrix = cosine_similarity(tv_matrix)
similarity_doc_df = pd.DataFrame(similarity_doc_matrix)
similarity_doc_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 0.820599 | 0.000000 | 0.000000 | 0.000000 | 0.192353 | 0.817246 | 0.000000 |
| 1 | 0.820599 | 1.000000 | 0.000000 | 0.000000 | 0.225489 | 0.157845 | 0.670631 | 0.000000 |
| 2 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.791821 | 0.000000 | 0.850516 |
| 3 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.506866 | 0.000000 | 0.000000 | 0.000000 |
| 4 | 0.000000 | 0.225489 | 0.000000 | 0.506866 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 5 | 0.192353 | 0.157845 | 0.791821 | 0.000000 | 0.000000 | 1.000000 | 0.115488 | 0.930989 |
| 6 | 0.817246 | 0.670631 | 0.000000 | 0.000000 | 0.000000 | 0.115488 | 1.000000 | 0.000000 |
| 7 | 0.000000 | 0.000000 | 0.850516 | 0.000000 | 0.000000 | 0.930989 | 0.000000 | 1.000000 |
Clustering Documents Using Similarity Features#
from scipy.cluster.hierarchy import dendrogram, linkage
Z = linkage(similarity_doc_matrix, 'ward')
# pd.DataFrame(Z,
# columns=[
# 'Document\Cluster 1', 'Document\Cluster 2', 'Distance',
# 'Cluster Size'
# ],
# dtype='object')
plt.figure(figsize=(5, 3))
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
dendrogram(Z)
plt.axhline(y=1.0, c='k', ls='--', lw=0.5)
<matplotlib.lines.Line2D at 0x177c963d0>
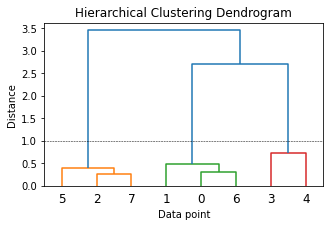
## Convert hierarchical cluster into a flat cluster structure
from scipy.cluster.hierarchy import fcluster
max_dist = 1.0
cluster_labels = fcluster(Z, max_dist, criterion='distance')
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
| Document | Category | ClusterLabel | |
|---|---|---|---|
| 0 | The sky is blue and beautiful. | weather | 2 |
| 1 | Love this blue and beautiful sky! | weather | 2 |
| 2 | The quick brown fox jumps over the lazy dog. | animals | 1 |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food | 3 |
| 4 | I love green eggs, ham, sausages and bacon! | food | 3 |
| 5 | The brown fox is quick and the blue dog is lazy! | animals | 1 |
| 6 | The sky is very blue and the sky is very beautiful today | weather | 2 |
| 7 | The dog is lazy but the brown fox is quick! | animals | 1 |
Clustering Words Using Similarity Features#
We can also transpose the
tv_matrixto get a Word-Document matrix.Each word can be represented as vectors based on their document distributions.
Words that are semantically similar tend to show similar distributions.
similarity_term_matrix = cosine_similarity(np.transpose(tv_matrix))
similarity_term_df = pd.DataFrame(similarity_term_matrix,
columns=feature_names,
index=feature_names)
similarity_term_df
| sky | blue | beautiful | jumps | dog | today | lazy | kings | breakfast | sausages | brown | love | beans | eggs | fox | toast | green | quick | ham | bacon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sky | 1.000000 | 0.63129 | 0.000000 | 0.000000 | 0.63129 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.775547 | 1.000000 | 0.000000 | 0.63129 | 0.000000 | 0.440615 | 0.000000 | 1.000000 | 0.000000 | 0.63129 | 0.000000 |
| blue | 0.631290 | 1.00000 | 0.000000 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 |
| beautiful | 0.000000 | 0.00000 | 1.000000 | 0.899485 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.473517 | 0.000000 | 0.000000 | 0.951208 | 0.00000 | 0.420997 |
| jumps | 0.000000 | 0.00000 | 0.899485 | 1.000000 | 0.00000 | 0.252766 | 0.252766 | 0.000000 | 0.252766 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.252766 | 0.425922 | 0.252766 | 0.000000 | 0.855597 | 0.00000 | 0.378680 |
| dog | 0.631290 | 1.00000 | 0.000000 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 |
| today | 0.000000 | 0.00000 | 0.000000 | 0.252766 | 0.00000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.528473 | 0.00000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| lazy | 0.000000 | 0.00000 | 0.000000 | 0.252766 | 0.00000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.528473 | 0.00000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| kings | 1.000000 | 0.63129 | 0.000000 | 0.000000 | 0.63129 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.775547 | 1.000000 | 0.000000 | 0.63129 | 0.000000 | 0.440615 | 0.000000 | 1.000000 | 0.000000 | 0.63129 | 0.000000 |
| breakfast | 0.000000 | 0.00000 | 0.000000 | 0.252766 | 0.00000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.528473 | 0.00000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| sausages | 0.775547 | 0.00000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.775547 | 0.000000 | 1.000000 | 0.775547 | 0.000000 | 0.00000 | 0.000000 | 0.568135 | 0.000000 | 0.775547 | 0.000000 | 0.00000 | 0.000000 |
| brown | 1.000000 | 0.63129 | 0.000000 | 0.000000 | 0.63129 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.775547 | 1.000000 | 0.000000 | 0.63129 | 0.000000 | 0.440615 | 0.000000 | 1.000000 | 0.000000 | 0.63129 | 0.000000 |
| love | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.00000 | 0.528473 | 0.528473 | 0.000000 | 0.528473 | 0.000000 | 0.000000 | 1.000000 | 0.00000 | 0.528473 | 0.000000 | 0.528473 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| beans | 0.631290 | 1.00000 | 0.000000 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 |
| eggs | 0.000000 | 0.00000 | 0.000000 | 0.252766 | 0.00000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.528473 | 0.00000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| fox | 0.440615 | 0.00000 | 0.473517 | 0.425922 | 0.00000 | 0.000000 | 0.000000 | 0.440615 | 0.000000 | 0.568135 | 0.440615 | 0.000000 | 0.00000 | 0.000000 | 1.000000 | 0.000000 | 0.440615 | 0.382602 | 0.00000 | 0.000000 |
| toast | 0.000000 | 0.00000 | 0.000000 | 0.252766 | 0.00000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.528473 | 0.00000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 |
| green | 1.000000 | 0.63129 | 0.000000 | 0.000000 | 0.63129 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.775547 | 1.000000 | 0.000000 | 0.63129 | 0.000000 | 0.440615 | 0.000000 | 1.000000 | 0.000000 | 0.63129 | 0.000000 |
| quick | 0.000000 | 0.00000 | 0.951208 | 0.855597 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.382602 | 0.000000 | 0.000000 | 1.000000 | 0.00000 | 0.680330 |
| ham | 0.631290 | 1.00000 | 0.000000 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 | 0.000000 | 0.000000 | 0.631290 | 0.000000 | 1.00000 | 0.000000 |
| bacon | 0.000000 | 0.00000 | 0.420997 | 0.378680 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.680330 | 0.00000 | 1.000000 |
Z2 = linkage(similarity_term_matrix, 'ward')
# pd.DataFrame(Z2,
# columns=[
# 'Document\Cluster 1', 'Document\Cluster 2', 'Distance',
# 'Cluster Size'
# ],
# dtype='object')
plt.figure(figsize=(7, 4))
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
dendrogram(Z2, labels=feature_names, leaf_rotation=90)
plt.axhline(y=1.0, c='k', ls='--', lw=0.5)
<matplotlib.lines.Line2D at 0x177da9040>
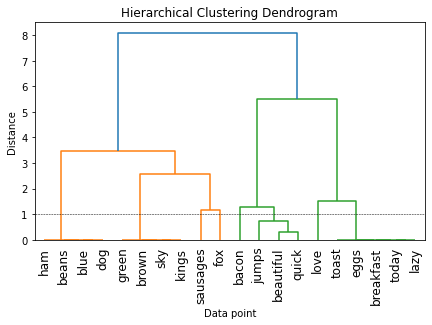
Notes on Word Vectors#
In the previous section, we talk about how we can utilize the Word-Document Matrix to create vectorized representations of words for a corpus.
This initial effort of representing words using their frequency distributions is referred to as a traditional count-based approach to word representations.
This count-based feature engineering strategy can be further sophisticated in several ways:
We can further limit the Word-Document Matrix to a Word-Word Co-occurrence Matrix, where the counts refer to the number of times when the two words co-occur within a specific window frame.
We can transform the sparse word vectors in the Word-Document Matrix or Word-Word Co-occurrence Matrix using statistical methods (e.g., Latent Semantic Analysis) and build the dense word vectors.
It should be noted that the count-based approach relies on the creation of the word distribution for the entire corpus in the first place. This can be difficult when we deal with a large corpus.
In contrast to the traditional count-based approach, predicative methods like neural network based language models try to predict words from their neighboring words by looking at word sequences in the corpus in a piecemeal fashion. Through this process the model learns the distributed representations of words, i.e, word embeddings.
We will come back to “word embeddings” when we work on the deep learning NLP.
Recommended Reading: Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors by Baroni et al.
Tip
Latent Semantic Analysis (aka. Latent Semantic Indexing) learns latent topics by performing a matrix decomposition on the document-term matrix using Singular value decomposition. LSA is typically used as a dimension reduction or noise reducing technique.
References#
Based on Sarkar (2020), Ch 4 Feature Engineering and Text Representation