
6. Assignment VI: Topic Modeling#
6.1. Question 1#
Perform an analysis of Topic Modeling on the corpus, nltk.corpus.movive_reviews, and provide the topic distributions of the movie reviews. Please report your topic distributions of positive and negative reviews respectively. (But please note that the topic modeling analysis should take the entire corpus as the input.)
Some heuristics for data preprocessing/vectorization:
Include in the bag-of-words representation only words whose lengths are >= 3
Include in the bag-of-words representation only words that are nouns (
NNorNNS) or verbs (VB.)Lemmatize all words in the bag-of-words representation using WordNet
Remove words on the stopwords list in
nltk.corpus.stopwords.words('english')Play with the
min_dfandmax_dfto find a better structure of CountVectorizer for the topic modeling
Warning
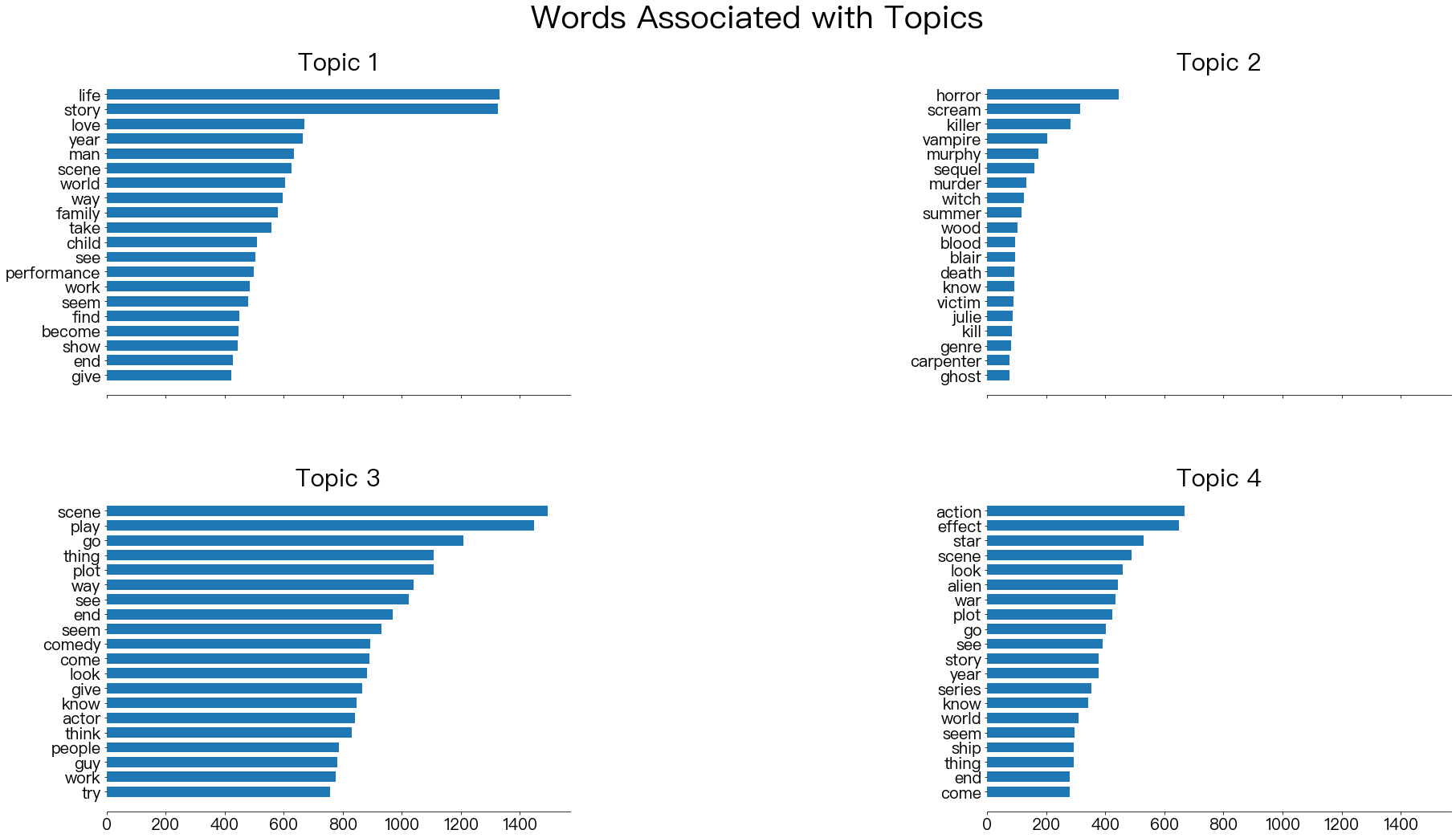
As this is an unsupervised learning, it is ok if you get different results. Please base your interpretations of the topics by examining closely their respective associated words in your LDA model.
Show code cell source
plot_top_words(lda, vocab, 20, "Words Associated with Topics", fig_grid=[2,2])
Show code cell source
g
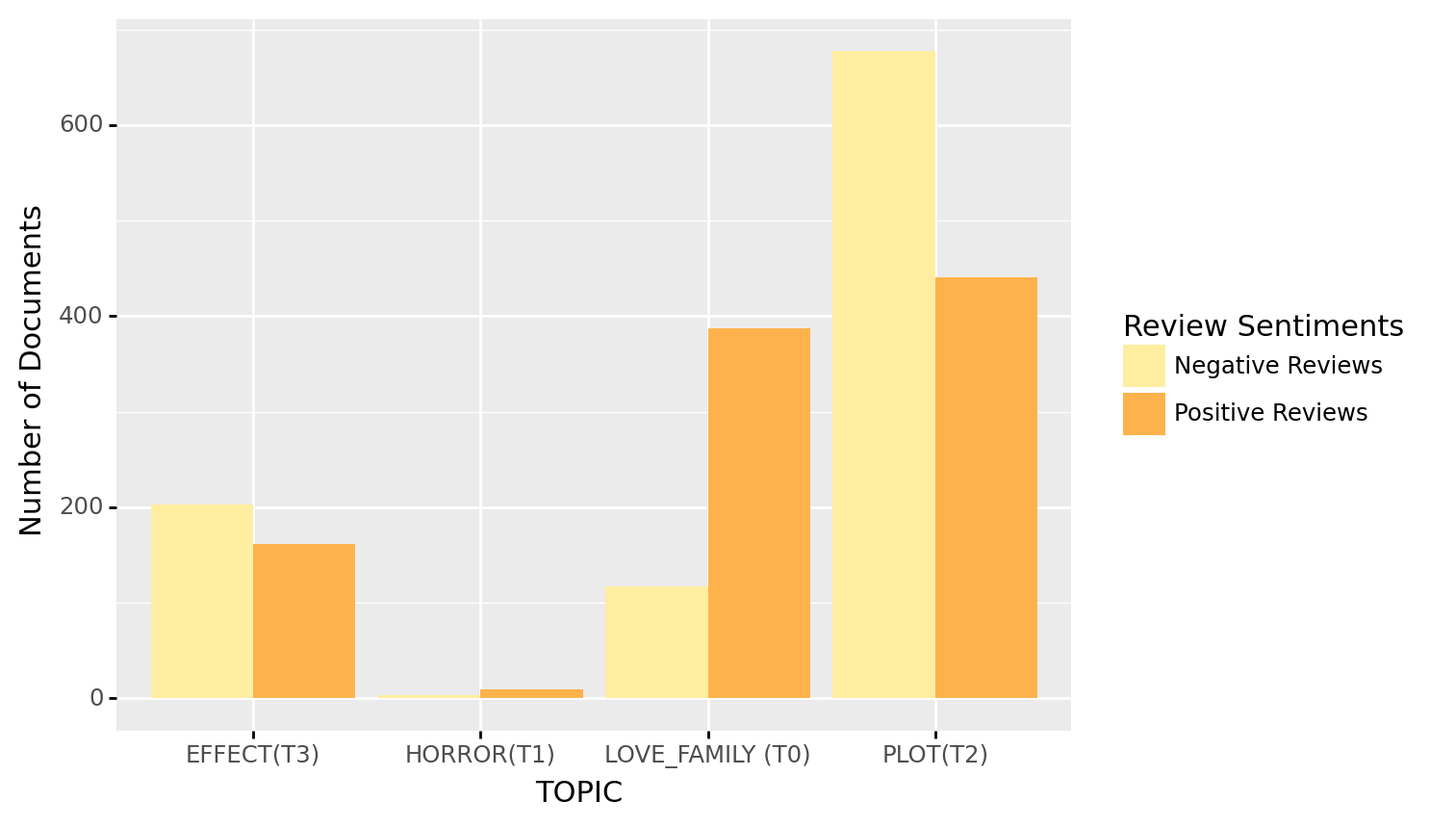
<ggplot: (8790600018531)>
6.2. Question 2#
Use the demo_data/dcard-top100.csv dataset (the same one used in the previous Assignment) and perform topic modeling on the dataset to explore the main topics of this small corpus.
To increase the interpretability of the topic modeling results, please word-segment the corpus data using ckip-transformers and then include word tokens whose POS indicate they are either nouns or verbs. However, please exclude pronouns and numerals. Also, before word segmentation, please preprocess the texts by removing alphabets, digits, and symbols first.
Please report (a) the meanings of the topics and their associated top 20 words in the corpus, and (b) the distribution of the topics in the entire corpus.