
5. Assignment V: Machine Learning#
5.1. Question 1#
Please use the nltk.corpus.names dataset discussed in class, and train a better classifier to determine the gender of the English names. In this assignment, please use sklearn to build your classifier (not nltk.classifier).
In particular, please consider the following two important aspects of when building the classifiers.
Improve the feature engineering by creating more relevant features that are gender-specific. You may do some literature review if necessary about the phonological characteristics and preferences for names of different genders.
Compare the performances of the classifiers based on different ML algorithms and determine the best-performing algorithm using k-fold cross validation.
Naive Bayes
Logistic Regression
SVM
Maximum Entropy
Use Grid Search Cross Validation from
sklearnto find the optimal hyperparameters of the model.
In your results, please report:
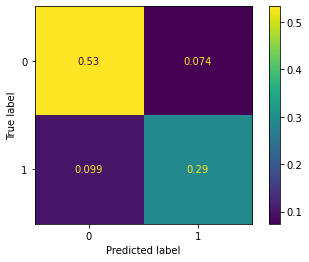
Model performance on the testing data (e.g., precision, recall, and confusion matrix)
Post-hoc analysis of the feature importance (which features contribute the most to the name gender prediction?)
Provide a LIME-based analysis of particular names (see below).
Show code cell source
plot_confusion_matrix(clf, X_test_bow, y_test, normalize='all')
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7fdd28f22a20>
Show code cell source
explanation1.show_in_notebook(text=True)
Show code cell source
explanation2.show_in_notebook(text=True)
Show code cell source
explanation3.show_in_notebook(text=True)