
Transfer Learning Using BERT#
What is transfer learning?#
Transfer learning is a machine learning technique where a model trained on one task is adapted or fine-tuned to work on a different but related task. It’s a way to leverage the knowledge acquired from one problem to solve another, potentially saving a lot of time and resources in training a new model from scratch.
Transfer learning, in particular, often involves the utilization of existing pre-trained large language models. In traditional statistical approaches to Natural Language Processing (NLP), like text classification, we typically create custom features and then use machine learning models such as logistic regression or support vector machines to learn how to classify text based on those features.
In contrast, deep learning, which is the basis for most Large Language Models (LLMs), not only learns how to classify but also discovers underlying, hidden features through a deep neural network.
As a result, a task-specific classifier can gain significant advantages from a pre-trained language model by directly using its output as input for downstream tasks within the classifier.
In this unit, we will illustrate how to make use of the pre-trained BERT language model and adapt it to our specific task, which is detecting emotions. Specifically, we wil talk about two methods:
Using the BERT as a generic pretrained embeddings model
Using the BERT as a base architecture for a classification task
Preparation#
# !wget https://raw.githubusercontent.com/yogawicaksana/helper_prabowo/main/helper_prabowo_ml.py
# from helper_prabowo_ml import clean_html, remove_links, non_ascii, lower, email_address, removeStopWords, punct, remove_
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#from google.colab import drive
import re
Mount Googe Drive#
Download the dataset Emotion Dataset for NLP from Kaggle and save the directory on your Google Drive.
Mount your Google Drive in Google Colab and specify the path to the data directory on your Drive.
## Colab Only
from google.colab import drive
drive.mount('/content/drive')
## Specify the path to the dataset
data_source_dir = '../../../RepositoryData/data/kaggle_emotion_dataset_for_NLP/'
## Load the data
train_path = data_source_dir + 'train.txt'
test_path = data_source_dir + 'test.txt'
val_path = data_source_dir + 'val.txt'
train_data = pd.read_csv(train_path, header=None, sep=';', names=['Input', 'Sentiment'], encoding='utf-8')
test_data = pd.read_csv(test_path, header=None, sep=';', names=['Input', 'Sentiment'], encoding='utf-8')
val_data = pd.read_csv(val_path, header=None, sep=';', names=['Input', 'Sentiment'], encoding='utf-8')
df = pd.concat([train_data, test_data, val_data], axis=0)
df = df.reset_index()
df.head(5)
| index | Input | Sentiment | |
|---|---|---|---|
| 0 | 0 | i didnt feel humiliated | sadness |
| 1 | 1 | i can go from feeling so hopeless to so damned... | sadness |
| 2 | 2 | im grabbing a minute to post i feel greedy wrong | anger |
| 3 | 3 | i am ever feeling nostalgic about the fireplac... | love |
| 4 | 4 | i am feeling grouchy | anger |
Text Preprocessing#
Prabowo Yoga Wicaksana created a few useful functions for text preprocessing. We utilize them to clean up the texts.
In particular, we remove the following ireelevant tokens from our texts:
html
web addresses
non-ascii tokens
email addresses
punctuations
Also, all texts are normalized into low-casing letters.
For more detail, please refer to the original code.
## text preprocessing
def normalize_document(doc):
"""
Normalize the document.
Parameters:
- doc (list): A list of documents
Returns:
list: a list of preprocessed documents
"""
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I | re.A)
doc = re.sub(r'http\S+','', doc ) ## romove links
doc = re.sub(r'bit.ly/\S+','', doc) ## remove bitly links
doc = re.sub(r'<.*?>','', doc) ## clean html
doc = re.sub(r'[\w\.-]+@[\w\.-]+', '', doc) ## remove email
doc = doc.lower() ## lower
doc = doc.strip()
return doc
normalize_corpus = np.vectorize(normalize_document)
# # PREPROCESS THE DATA
# def preproc(df, colname):
# df[colname] = df[colname].apply(func=clean_html)
# df[colname] = df[colname].apply(func=remove_links)
# df[colname] = df[colname].apply(func=non_ascii)
# df[colname] = df[colname].apply(func=lower)
# df[colname] = df[colname].apply(func=email_address)
# # df[colname] = df[colname].apply(func=removeStopWords)
# df[colname] = df[colname].apply(func=punct)
# df[colname] = df[colname].apply(func=remove_)
# return(df)
# df_clean = preproc(df, 'Input')
df_clean = df
df_clean['Input'] = df['Input'].apply(normalize_corpus)
df_clean.head()
| index | Input | Sentiment | |
|---|---|---|---|
| 0 | 0 | i didnt feel humiliated | sadness |
| 1 | 1 | i can go from feeling so hopeless to so damned... | sadness |
| 2 | 2 | im grabbing a minute to post i feel greedy wrong | anger |
| 3 | 3 | i am ever feeling nostalgic about the fireplac... | love |
| 4 | 4 | i am feeling grouchy | anger |
df_clean.drop('index', axis=1, inplace=True)
df_clean['num_words'] = df_clean['Input'].apply(lambda x: len(x.split()))
df_clean['num_chars'] = df_clean['Input'].apply(lambda x: len(x))
df_clean['Sentiment'] = df_clean['Sentiment'].astype('category') # ChagGpt corrected this error!
df_clean['Sentiment'] = df_clean['Sentiment'].cat.codes
encoded_dict = {'anger':0, 'fear':1, 'joy':2, 'love':3, 'sadness':4, 'surprise':5}
df_clean.head(5)
| Input | Sentiment | num_words | num_chars | |
|---|---|---|---|---|
| 0 | i didnt feel humiliated | 4 | 4 | 23 |
| 1 | i can go from feeling so hopeless to so damned... | 4 | 21 | 108 |
| 2 | im grabbing a minute to post i feel greedy wrong | 0 | 10 | 48 |
| 3 | i am ever feeling nostalgic about the fireplac... | 3 | 18 | 92 |
| 4 | i am feeling grouchy | 0 | 4 | 20 |
## char range
print(df_clean['num_chars'].max())
print(df_clean['num_chars'].min())
print(df_clean['num_words'].max())
## word range
print(df_clean['num_words'].min())
300
7
66
2
Loading Tokenizer#
Each pre-trained language model has its own tokenizer.
# Load model and tokenizer
# %%capture
# ! pip install transformers
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
from transformers import AutoTokenizer, TFBertModel
BERT Tokenization#
## Load tokenizer and the pre-trained bert model
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
sent = ["Don't like it!", "I'll send it!"]
tokenizer(sent[0], sent[1]) ## feed a pair of sentences
{'input_ids': [101, 1790, 112, 189, 1176, 1122, 106, 102, 146, 112, 1325, 3952, 1122, 106, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
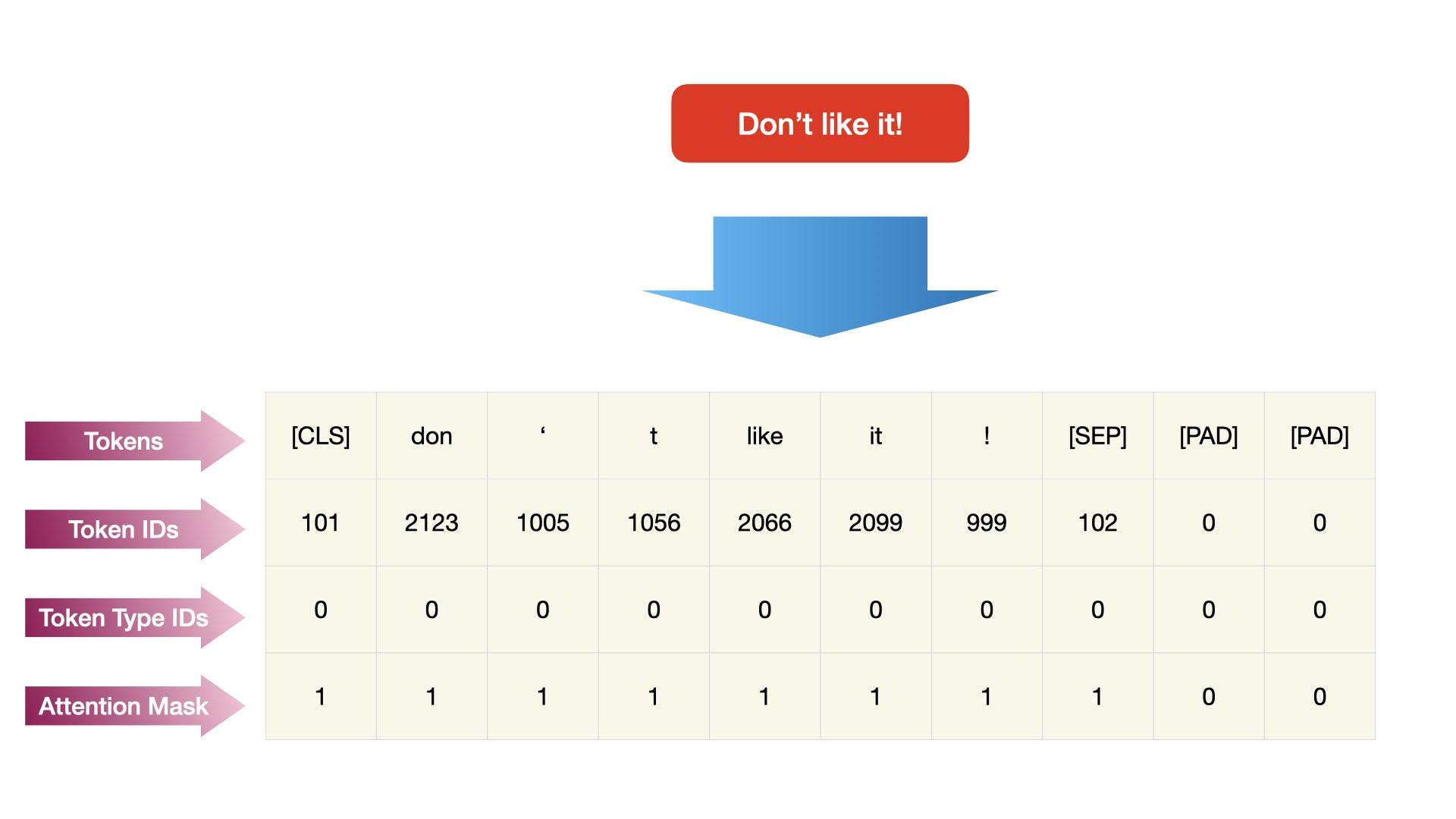
The output of the BERT tokenizer consists of three main components: input_ids, token_type_ids, and attention_mask.
Input IDs (
input_ids):These are sequences of integers representing the tokens in the input text.
Each token is mapped to a unique integer ID, which is specific to the BERT tokenizer’s vocabulary.
The input IDs are similar to the output of
text_to_sequences()in Keras when converting text data into sequences of integers.
Token Type IDs (
token_type_ids):These IDs indicate which sentence each token belongs to.
BERT models can accept two sequences simultaneously, so this parameter distinguishes tokens from the first sentence (sequence) and tokens from the second sentence.
For single-sentence inputs, all token type IDs are typically set to the same value.
Attention Mask (
attention_mask):The attention mask indicates which tokens are actual tokens and which are padding tokens.
Padding tokens are added to ensure that all input sequences have the same length.
The attention mechanism in BERT calculates attention scores based on this mask, ignoring padding tokens during the calculation.
In summary, the output of the BERT tokenizer provides the necessary input formats for feeding data into BERT-based models, including the tokenized integer sequences (input_ids), token type IDs (token_type_ids), and attention mask (attention_mask). These components ensure that the input data is properly formatted and processed by BERT models for tasks such as classification, tagging, or translation.
Tip
The special tokens in BERT tokenizer play crucial roles in BERT-based models. Here’s an explanation based on the provided text:
[SEP]Token:The
[SEP]token is a special separator token added by theBertTokenizer.It is used to separate two sequences when the task requires processing two sequences simultaneously, such as in BERT training.
The presence of
[SEP]token indicates the boundary between two sequences and helps the model understand the separation between segments of input data.
[CLS]Token:The
[CLS]token is another special token added by theBertTokenizer.It is added at the beginning of the input sequence and stands for the classifier token.
The embedding of the
[CLS]token serves as a summary of the inputs and is ready for downstream classification tasks.The pooled output of the
[CLS]token represents a high-level representation of the entire input sequence, which can be used as the input for additional layers on top of the BERT model.Essentially, the
[CLS]token’s embedding serves as document embeddings, capturing the overall semantic content of the input text, making it suitable for classification tasks and other downstream tasks.
Note
In Jupyter notebooks, the %%capture magic command is used to capture and control the output of code cells. It’s a convenient way to suppress or store the output produced by code within a cell.
Here’s how %%capture works:
Suppressing Output: When you use
%%captureat the beginning of a code cell, it captures all the output produced by the code within that cell and prevents it from being displayed in the notebook. This is helpful when you have a cell that generates a lot of output, and you want to keep your notebook clean.%%capture # Your code producing output
Storing Output: You can also use
%%captureto store the captured output in a variable for later use. This is particularly useful if you want to analyze or process the output in some way.%%capture captured_output # Your code producing output
After running the cell, you can access the captured output using the
captured_outputvariable.
## Train-test splitting
df_train, df_test = train_test_split(df_clean, test_size=0.3, random_state=42,stratify=df_clean['Sentiment'])
## Load tokenizer and the pre-trained bert model
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
bert = TFBertModel.from_pretrained('bert-base-cased')
max_len = 70 # Know the max length of the sentences in your dataset.
## Tokenizers
X_train = tokenizer(
text=df_train['Input'].tolist(),
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=True,
return_tensors='tf',
return_token_type_ids=False,
return_attention_mask=True,
verbose=True
)
X_test = tokenizer(
text=df_test['Input'].tolist(),
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=True,
return_tensors='tf',
return_token_type_ids=False,
return_attention_mask=True,
verbose=True
)
2024-03-12 19:34:36.456395: I metal_plugin/src/device/metal_device.cc:1154] Metal device set to: Apple M2 Max
2024-03-12 19:34:36.456444: I metal_plugin/src/device/metal_device.cc:296] systemMemory: 32.00 GB
2024-03-12 19:34:36.456457: I metal_plugin/src/device/metal_device.cc:313] maxCacheSize: 10.67 GB
2024-03-12 19:34:36.456526: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:306] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2024-03-12 19:34:36.456560: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:272] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFBertModel: ['cls.predictions.transform.LayerNorm.weight', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing TFBertModel from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFBertModel from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFBertModel were initialized from the PyTorch model.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFBertModel for predictions without further training.
Note
In the Transformers library, which is commonly used for working with pre-trained transformer models like BERT, TFBertModel and AutoModelForSequenceClassification serve different purposes.
TFBertModel:
TFBertModelis a generic class for loading the BERT model architecture in TensorFlow. It provides the base BERT model that can be used for various tasks, but it doesn’t have task-specific heads attached to it. This means it doesn’t have a built-in mechanism for tasks like sequence classification. It is mainly used when you want to use BERT as a feature extractor or when you want to build a custom model on top of BERT for a specific task.
AutoModelForSequenceClassification:
AutoModelForSequenceClassificationis a class specifically designed for sequence classification tasks using transformer models. It includes the BERT model architecture along with a classification head tailored for tasks like text classification. When you use this class, you don’t need to add a separate classification head; it’s already integrated into the model.
Use
TFBertModelwhen you need the base BERT model for tasks other than sequence classification or when you want to build a custom model architecture on top of BERT.Use
AutoModelForSequenceClassificationwhen your task is sequence classification (e.g., sentiment analysis, text categorization). It includes a classification head and is ready to be used for training or inference on classification tasks.
Choose the appropriate class based on your specific task requirements and whether you need a generic BERT model or a model tailored for sequence classification.
Model Training#
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.initializers import TruncatedNormal
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import CategoricalAccuracy
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.layers import Input, Dense
## checking GPU on the machine
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
Num GPUs Available: 1
# Input layer
input_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_ids")
input_mask = Input(shape=(max_len,), dtype=tf.int32, name="attention_mask")
# Hidden layer
embeddings = bert(input_ids, attention_mask = input_mask)[0] # 0 = last hidden state, 1 = poller_output
out = tf.keras.layers.GlobalMaxPool1D()(embeddings)
out = Dense(128, activation='relu')(out)
out = tf.keras.layers.Dropout(0.1)(out)
out = Dense(32, activation='relu')(out)
# Output layer
y = Dense(6, activation='softmax')(out) # 6 means 6 sentiments
# Model
model = tf.keras.Model(inputs=[input_ids, input_mask], outputs=y)
model.layers[2].trainable = True # Make sure being updated by backpropagation
# Optimizer
optimizer = tf.keras.optimizers.legacy.Adam( # tf.keras.optimizers.legacy.Adam (new)
learning_rate=5e-05, # HF recommendation
epsilon=1e-08,
decay=0.01,
clipnorm=1.0
)
# Loss function
loss = CategoricalCrossentropy(from_logits=True)
# Evaluation
metric = CategoricalAccuracy('balanced_accuracy') # Data is unbalanced.
# Compile
model.compile(
optimizer=optimizer,
loss=loss,
metrics=metric
)
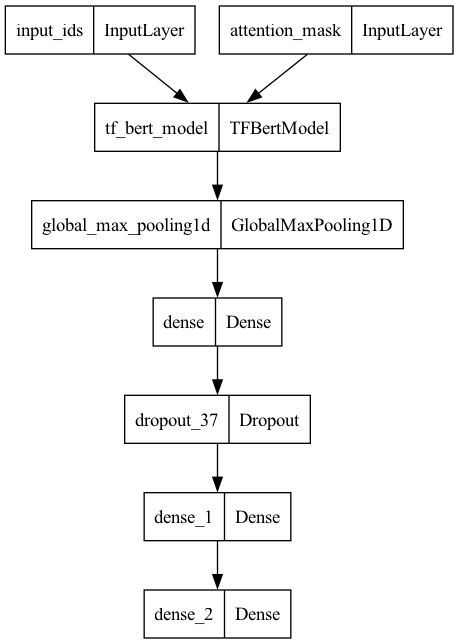
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_ids (InputLayer) [(None, 70)] 0 []
attention_mask (InputLayer [(None, 70)] 0 []
)
tf_bert_model (TFBertModel TFBaseModelOutputWithPooli 1083102 ['input_ids[0][0]',
) ngAndCrossAttentions(last_ 72 'attention_mask[0][0]']
hidden_state=(None, 70, 76
8),
pooler_output=(None, 768)
, past_key_values=None, hi
dden_states=None, attentio
ns=None, cross_attentions=
None)
global_max_pooling1d (Glob (None, 768) 0 ['tf_bert_model[0][0]']
alMaxPooling1D)
dense (Dense) (None, 128) 98432 ['global_max_pooling1d[0][0]']
dropout_37 (Dropout) (None, 128) 0 ['dense[0][0]']
dense_1 (Dense) (None, 32) 4128 ['dropout_37[0][0]']
dense_2 (Dense) (None, 6) 198 ['dense_1[0][0]']
==================================================================================================
Total params: 108413030 (413.56 MB)
Trainable params: 108413030 (413.56 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
plot_model(model)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
model.layers
[<keras.src.engine.input_layer.InputLayer at 0x2c549b460>,
<keras.src.engine.input_layer.InputLayer at 0x2c549b4f0>,
<transformers.models.bert.modeling_tf_bert.TFBertModel at 0x2b914e760>,
<keras.src.layers.pooling.global_max_pooling1d.GlobalMaxPooling1D at 0x2c27e0430>,
<keras.src.layers.core.dense.Dense at 0x2b9372640>,
<keras.src.layers.regularization.dropout.Dropout at 0x2bcf92e50>,
<keras.src.layers.core.dense.Dense at 0x2bcfdca00>,
<keras.src.layers.core.dense.Dense at 0x2c31d32e0>]
Model Fitting#
history = model.fit(
x = {'input_ids':X_train['input_ids'], 'attention_mask':X_train['attention_mask']},
y = to_categorical(df_train['Sentiment']), ## convert y labels into one-hot encoding
validation_data = ({'input_ids':X_test['input_ids'], 'attention_mask':X_test['attention_mask']},
to_categorical(df_test['Sentiment'])),
epochs=1,
batch_size=32
)
/Users/alvinchen/anaconda3/envs/tensorflowgpu/lib/python3.9/site-packages/keras/src/backend.py:5577: UserWarning: "`categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a Softmax activation and thus does not represent logits. Was this intended?
output, from_logits = _get_logits(
WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
2024-03-12 19:35:12.263400: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:117] Plugin optimizer for device_type GPU is enabled.
438/438 [==============================] - 245s 487ms/step - loss: 0.8080 - balanced_accuracy: 0.7212 - val_loss: 0.2528 - val_balanced_accuracy: 0.9165
history.history
{'loss': [0.8080430626869202],
'balanced_accuracy': [0.7212142944335938],
'val_loss': [0.2527957558631897],
'val_balanced_accuracy': [0.9164999723434448]}
Evaluation#
# Evaluation
from sklearn.metrics import classification_report
predicted = model.predict({'input_ids': X_test['input_ids'], 'attention_mask': X_test['attention_mask']})
y_predicted = np.argmax(predicted, axis=1)
print(classification_report(df_test['Sentiment'], y_predicted))
188/188 [==============================] - 38s 169ms/step
precision recall f1-score support
0 0.88 0.96 0.92 813
1 0.87 0.88 0.87 712
2 0.96 0.93 0.94 2028
3 0.81 0.85 0.83 492
4 0.95 0.94 0.95 1739
5 0.77 0.76 0.77 216
accuracy 0.92 6000
macro avg 0.88 0.89 0.88 6000
weighted avg 0.92 0.92 0.92 6000
Using Transformer-based Classifiers Directly#
In our previous example, we built the classifier from the generic Bert model (TFBertModel). We can also use the AutoModelForSequenceClassification from Transformer to build a classifier, which features a BERT architecture.
# Fine-tune DistilBERT classifier
from transformers import TFAutoModelForSequenceClassification
bert_model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=6)
All PyTorch model weights were used when initializing TFBertForSequenceClassification.
Some weights or buffers of the TF 2.0 model TFBertForSequenceClassification were not initialized from the PyTorch model and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
y_train = np.array(df_train['Sentiment'])
y_train
array([2, 1, 4, ..., 0, 4, 5], dtype=int8)
Tip
When using the generic BERT model, the
tokenizer()should specifyreturn_tensor='tf'for model building in tensforflow.When using the
TFAutoModelForSequenceClassification model, thetokenizer()should specifyreturn_tensor='np'for model building in Transformer. Also, the output oftokenizer()needs to be converted into adict(Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras) )
## Tokenizers
X_train = tokenizer(
text=df_train['Input'].tolist(),
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=True,
return_tensors='np',
return_token_type_ids=False,
return_attention_mask=True,
verbose=True
)
X_train = dict(X_train)
from tensorflow.keras.optimizers import Adam
bert_model.compile(optimizer=Adam(3e-5), metrics=['accuracy']) # No loss argument!
WARNING:absl:At this time, the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at `tf.keras.optimizers.legacy.Adam`.
2023-11-13 14:46:05.988958: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:961] model_pruner failed: INVALID_ARGUMENT: Graph does not contain terminal node Adam/AssignAddVariableOp_10.
438/438 [==============================] - 176s 359ms/step - loss: 0.5256 - accuracy: 0.8253
<keras.src.callbacks.History at 0x30d5bf310>
bert_model.fit(X_train, y_train)
# Evaluation
from sklearn.metrics import classification_report
X_test= tokenizer(
text=df_test['Input'].tolist(),
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=True,
return_tensors='np',
return_token_type_ids=False,
return_attention_mask=True,
verbose=True
)
X_test = dict(X_test)
y_test = np.array(df_test['Sentiment'])
predicted = bert_model.predict(X_test)
y_predicted = np.argmax(predicted.logits, axis=1)
print(classification_report(y_test, y_predicted))
188/188 [==============================] - 40s 176ms/step
precision recall f1-score support
0 0.89 0.96 0.92 813
1 0.86 0.92 0.89 712
2 0.97 0.92 0.94 2028
3 0.79 0.92 0.85 492
4 0.96 0.95 0.95 1739
5 0.98 0.68 0.80 216
accuracy 0.92 6000
macro avg 0.91 0.89 0.89 6000
weighted avg 0.93 0.92 0.93 6000
References#
This tutorial is based on this article.
Hugging Face Documentation: Fine-tune a pretrained model
[Dropout layer] (https://datasciocean.tech/deep-learning-core-concept/understand-dropout-in-deep-learning/)
Other Fine-tuning Methods (Self-Study)#
Fine-tune with Tensorflow Keras#
# data frame to dataset
from datasets import Dataset, DatasetDict
X_train_ds = Dataset.from_pandas(df_train[['Input','Sentiment']].rename(columns={'Input': 'text', 'Sentiment': 'label'}), preserve_index= False)
X_test_ds = Dataset.from_pandas(df_test[['Input','Sentiment']].rename(columns={'Input': 'text', 'Sentiment': 'label'}), preserve_index= False)
ds = DatasetDict()
ds['train'] = X_train_ds
ds['test'] = X_test_ds
ds
def preprocess(examples):
return tokenizer(
text= examples["text"],
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=True,
# return_tensors='np',
# return_token_type_ids=False,
# return_attention_mask=True,
verbose=True)
# return tokenizer(examples["text"], max_length=200, padding=True, truncation=True)
ds_tokenized = ds.map(preprocess, batched=True)
ds_tokenized
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# Load and compile our model
# PRETRAINED_MODEL = 'distilbert-base-uncased'
PRETRAINED_MODEL = 'bert-base-cased'
model = TFAutoModelForSequenceClassification.from_pretrained(PRETRAINED_MODEL, num_labels=6)
tf_dataset_train_my = model.prepare_tf_dataset(ds_tokenized['train'], batch_size=100, shuffle=True, tokenizer=tokenizer)
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5), metrics=["accuracy"]) # No loss argument!
from tensorflow.keras.utils import plot_model
plot_model(model, show_shapes =True)
history = model.fit(tf_dataset_train_my, epochs=2)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
All PyTorch model weights were used when initializing TFBertForSequenceClassification.
Some weights or buffers of the TF 2.0 model TFBertForSequenceClassification were not initialized from the PyTorch model and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
You're using a BertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
WARNING:absl:At this time, the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at `tf.keras.optimizers.legacy.Adam`.
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Epoch 1/2
2024-03-12 20:37:25.651485: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:961] model_pruner failed: INVALID_ARGUMENT: Graph does not contain terminal node Adam/AssignAddVariableOp_10.
140/140 [==============================] - 154s 939ms/step - loss: 1.2556 - accuracy: 0.5116
Epoch 2/2
140/140 [==============================] - 112s 801ms/step - loss: 0.2717 - accuracy: 0.9050
tf_dataset_test_my = model.prepare_tf_dataset(ds_tokenized["test"], batch_size=100, shuffle=True, tokenizer=tokenizer)
model.evaluate(tf_dataset_test_my)
60/60 [==============================] - 22s 303ms/step - loss: 0.1622 - accuracy: 0.9323
[0.16222473978996277, 0.9323333501815796]
=========
Check GPU Availability#
## Check GPU support in tensorflow
import sys
import tensorflow.keras
import pandas as pd
import sklearn as sk
import scipy as sp
import tensorflow as tf
import platform
print(f"Python Platform: {platform.platform()}")
print(f"Tensor Flow Version: {tf.__version__}")
#print(f"Keras Version: {tensorflow.keras.__version__}")
print()
print(f"Python {sys.version}")
print(f"Pandas {pd.__version__}")
print(f"Scikit-Learn {sk.__version__}")
print(f"SciPy {sp.__version__}")
gpu = len(tf.config.list_physical_devices('GPU'))>0
print("GPU is", "available" if gpu else "NOT AVAILABLE")
Python Platform: macOS-14.3.1-arm64-arm-64bit
Tensor Flow Version: 2.14.0
Python 3.9.18 (main, Sep 11 2023, 08:25:10)
[Clang 14.0.6 ]
Pandas 2.1.3
Scikit-Learn 1.3.2
SciPy 1.11.3
GPU is available
## Check GPU support in Pytorch
import sys
import platform
import torch
import pandas as pd
import sklearn as sk
print(torch.backends.mps.is_available()) #the MacOS is higher than 12.3+
print(torch.backends.mps.is_built()) #MPS is activated
True
True
## checking
has_gpu = torch.cuda.is_available()
has_mps = torch.backends.mps.is_built()
device = "mps" if torch.backends.mps.is_built() \
else "gpu" if torch.cuda.is_available() else "cpu"
print(f"Python Platform: {platform.platform()}")
print(f"PyTorch Version: {torch.__version__}")
print()
print(f"Python {sys.version}")
print(f"Pandas {pd.__version__}")
print(f"Scikit-Learn {sk.__version__}")
print("GPU is", "available" if has_gpu else "NOT AVAILABLE")
print("MPS (Apple Metal) is", "AVAILABLE" if has_mps else "NOT AVAILABLE")
print(f"Target device is {device}")
Python Platform: macOS-14.3.1-arm64-arm-64bit
PyTorch Version: 2.2.0.dev20231112
Python 3.9.18 (main, Sep 11 2023, 08:25:10)
[Clang 14.0.6 ]
Pandas 2.1.3
Scikit-Learn 1.3.2
GPU is NOT AVAILABLE
MPS (Apple Metal) is AVAILABLE
Target device is mps
Fine-tune with PyTorch Trainer (Not working with Mac M2)#
# import os
# os.environ['PYTORCH_ENABLE_MPS_FALLBACK'] = '0'
# import torch
# import torch
# device = torch.device('cpu')
# # model.to(device)
# device = torch.device('cpu')
# import torch
# if torch.backends.mps.is_available():
# mps_device = torch.device("mps")
# G.to(mps_device)
# D.to(mps_device)
# !pip install transformers datasets
# !pip install accelerate -U
import torch
if torch.backends.mps.is_available():
mps_device = torch.device("mps")
x = torch.ones(1, device=mps_device)
print (x)
else:
print ("MPS device not found.")
# # import torch
# device = torch.device('mps')
tensor([1.], device='mps:0')
# Load IMDB dataset
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
# Preprocess data
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
imdb_dataset
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
len(tokenizer(imdb_dataset["train"]["text"][1], max_length=100)['input_ids'])
Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
100
# len(preprocess(imdb_dataset["train"][1])['input_ids'])
def preprocess(examples):
return tokenizer(examples["text"], max_length=200, padding=True, truncation=True)
tokenized_datasets = imdb_dataset.map(preprocess, batched=True)
len(tokenized_datasets["test"]["input_ids"][1])
200
# Prepare datasets
train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
type(train_dataset)
datasets.arrow_dataset.Dataset
mps_device = torch.device("mps")
torch.device(“mps”)
# Fine-tune DistilBERT classifier
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
# model = model.to('mps')
# device_map={"":"mps"}
model.to(mps_device)
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.weight', 'pre_classifier.weight', 'classifier.bias', 'pre_classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
DistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0-5): 6 x TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(activation): GELUActivation()
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir="test_trainer")#, use_mps_device= True, no_cuda = True)
## Transformers still does not support m2 for GPU computing
## mps not working with m2 chip
# device = 'mps'
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
# Evaluate
model.eval()
outputs = model(**eval_dataset[0])
predictions = outputs.logits.argmax(-1)
{'train_runtime': 58.4428, 'train_samples_per_second': 51.332, 'train_steps_per_second': 6.417, 'train_loss': 0.28378061930338544, 'epoch': 3.0}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[66], line 19
17 # Evaluate
18 model.eval()
---> 19 outputs = model(**eval_dataset[0])
20 predictions = outputs.logits.argmax(-1)
File ~/anaconda3/envs/tensorflowgpu/lib/python3.9/site-packages/torch/nn/modules/module.py:1510, in Module._wrapped_call_impl(self, *args, **kwargs)
1508 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1509 else:
-> 1510 return self._call_impl(*args, **kwargs)
File ~/anaconda3/envs/tensorflowgpu/lib/python3.9/site-packages/torch/nn/modules/module.py:1519, in Module._call_impl(self, *args, **kwargs)
1514 # If we don't have any hooks, we want to skip the rest of the logic in
1515 # this function, and just call forward.
1516 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1517 or _global_backward_pre_hooks or _global_backward_hooks
1518 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1519 return forward_call(*args, **kwargs)
1521 try:
1522 result = None
TypeError: forward() got an unexpected keyword argument 'text'