Chapter 13 Text Analytics: A Start
In this chapter, I will present a quick overview of computational text analytics with R. The most important package for exploratory text analysis is quanteda. As computational text analytics itself is an interesting topic, I would recommend other more advanced courses for those who are interested in this field (e.g., ENC2036:Corpus Linguistics, ENC2045:Computational Linguistics)
This chapter only provides you a very general overview of the common procedures/tasks in text processing.
13.1 Installing quanteda
There are many packages that are made for computational text analytics in R. You may consult the CRAN Task View: Natural Language Processing for a lot more alternatives.
To start with, this tutorial will use a powerful package, quanteda, for managing and analyzing textual data in R. You may refer to the official documentation of the package for more detail.
The libraryquanteda is not included in the default base R installation. Please install the package if you haven’t done so.
install.packages("quanteda")
install.packages("quanteda.textmodels")
install.packages("quanteda.textstats")
install.packages("quanteda.textplots")
install.packages("readtext")
# remotes::install_github("quanteda/quanteda.corpora")
# remotes::install_github("kbenoit/quanteda.dictionaries")Also, as noted on the quanteda documentation, because this library compiles some C++ and Fortran source code, you need to install the appropriate compilers.
- If you are using a Windows platform, this means you will need also to install the Rtools software available from CRAN.
- If you are using macOS, you should install the macOS tools.
If you run into any installation errors, please go to the official documentation page for additional assistance.
The library quanteda contains all of the core natural language processing and textual data management functions.The following libraries work with quanteda, providing more advanced functions for computational text analytics.
quanteda.textmodels: includes the text models and supporting functions (i.e.,textmodel_*()functions).quanteda.textstats: includes statistic processing for textual data (i.e.,textstat_*()functions).quanteda.textplots: includes plotting functions for textual data (i.e.,textplot_*()functions).quanteda.corpora: Additional textual data for use with quanteda. (Install using:remotes::install_github("quanteda/quanteda.corpora")quanteda.dictionaries: Various dictionaries for use with quanteda, including the functionliwcalike(), an R implementation of the Linguistic Inquiry and Word Count approach to text analysis. (Install using:remotes::install_github("kbenoit/quanteda.dictionaries")
library(quanteda)
library(quanteda.textplots)
library(quanteda.textstats)
library(tidyverse)
packageVersion("quanteda")[1] '4.1.0'13.2 Building a corpus from character vector
To demonstrate a typical corpus analytic example with texts, I will be using a pre-loaded corpus that comes with the quanteda package, data_corpus_inaugural. This is a corpus of US Presidential Inaugural Address texts and metadata for the corpus from 1789 to present.
Corpus consisting of 59 documents and 4 docvars.
1789-Washington :
"Fellow-Citizens of the Senate and of the House of Representa..."
1793-Washington :
"Fellow citizens, I am again called upon by the voice of my c..."
1797-Adams :
"When it was first perceived, in early times, that no middle ..."
1801-Jefferson :
"Friends and Fellow Citizens: Called upon to undertake the du..."
1805-Jefferson :
"Proceeding, fellow citizens, to that qualification which the..."
1809-Madison :
"Unwilling to depart from examples of the most revered author..."
[ reached max_ndoc ... 53 more documents ][1] "corpus" "character"[1] 59 [1] "1789-Washington" "1793-Washington" "1797-Adams" "1801-Jefferson"
[5] "1805-Jefferson" "1809-Madison" "1813-Madison" "1817-Monroe"
[9] "1821-Monroe" "1825-Adams" "1829-Jackson" "1833-Jackson"
[13] "1837-VanBuren" "1841-Harrison" "1845-Polk" "1849-Taylor"
[17] "1853-Pierce" "1857-Buchanan" "1861-Lincoln" "1865-Lincoln"
[21] "1869-Grant" "1873-Grant" "1877-Hayes" "1881-Garfield"
[25] "1885-Cleveland" "1889-Harrison" "1893-Cleveland" "1897-McKinley"
[29] "1901-McKinley" "1905-Roosevelt" "1909-Taft" "1913-Wilson"
[33] "1917-Wilson" "1921-Harding" "1925-Coolidge" "1929-Hoover"
[37] "1933-Roosevelt" "1937-Roosevelt" "1941-Roosevelt" "1945-Roosevelt"
[41] "1949-Truman" "1953-Eisenhower" "1957-Eisenhower" "1961-Kennedy"
[45] "1965-Johnson" "1969-Nixon" "1973-Nixon" "1977-Carter"
[49] "1981-Reagan" "1985-Reagan" "1989-Bush" "1993-Clinton"
[53] "1997-Clinton" "2001-Bush" "2005-Bush" "2009-Obama"
[57] "2013-Obama" "2017-Trump" "2021-Biden" We create a corpus() object with the pre-loaded corpus in quanteda– data_corpus_inaugural:
After the corpus is loaded, we can use summary() to get the metadata of each text in the corpus, including word types and tokens as well. This allows us to have a quick look at the size of the addresses made by all presidents.
In quanteda, it has implemented a default tokenization method for English texts. I think it has also implemented a default tokenization method for Chinese texts as well. For more control on the word segmentation, you may need to consult other segmentation packages (e.g., jiebaR, ckiptagger etc.). More details are usually discussed in ENC2045 or ENC2036.
corp_us %>%
summary %>%
ggplot(aes(x = Year, y = Tokens, group = 1)) +
geom_line() +
geom_point() +
theme_bw()
Exercise 13.1 Could you reproduce the above line plot and add information of President to the plot as labels of the dots?
Hints: Please check ggplot2::geom_text() or more advanced one, ggrepel::geom_text_repel()
13.3 Tokenization
The first step for most textual analyses is usually tokenization, i.e., breaking each long text into word tokens for linguistic analysis.
Tokens consisting of 1 document and 4 docvars.
1789-Washington :
[1] "Fellow-Citizens" "of" "the" "Senate"
[5] "and" "of" "the" "House"
[9] "of" "Representatives" ":" "Among"
[ ... and 1,525 more ]Starting from quanteda version 4.0+, a new class of tokens object, tokens_xptr, was introduced. This object enhances the efficiency of adjusting tokens objects based on large text corpora.
13.4 Keyword-in-Context (KWIC)
Keyword-in-Context (KWIC), or concordances, are the most frequently used method in corpus analysis. The idea is very intuitive: we get to know more about the semantics of a word (or any other linguistic unit) by examining how it is being used in a wider context.
We can use kwic() to perform a search for a word and retrieve its concordances from the corpus:
kwic() returns a data frame, which can be easily exported as a CSV file for later use.
Please note that kwic() takes a tokens object as the input argument.
That is, please tokenize the corpus object with tokens() first before you perform more advanced textual analysis, e.g., kwic().
Also, with kwic(), the pattern you look for cannot be a multi-word linguistic pattern.
For Chinese, quanteda can take care of Chinese word segmentation but with rather limited capacity.
texts <- c("舞台正中間擺著一張「空著的導演椅」,影片一下全場鼻酸。",
"第58屆金馬獎頒獎典禮今(27)日在國父紀念館盛大登場,星光大道紅毯於下午5點30分登場。")
corpus_ch <- corpus(texts)
corpus_chCorpus consisting of 2 documents.
text1 :
"舞台正中間擺著一張「空著的導演椅」,影片一下全場鼻酸。"
text2 :
"第58屆金馬獎頒獎典禮今(27)日在國父紀念館盛大登場,星光大道紅毯於下午5點30分登場。" [1] "舞台" "正" "中間" "擺著" "一張" "「" "空" "著" "的" "導演"
[11] "椅" "」" "," "影片" "一下" "全" "場" "鼻酸" "。" [1] "第" "58" "屆" "金馬獎" "頒獎典禮"
[6] "今" "(" "27" ")" "日"
[11] "在" "國父紀念館" "盛大" "登場" ","
[16] "星光" "大道" "紅" "毯" "於"
[21] "下午" "5" "點" "30" "分"
[26] "登場" "。" 13.5 KWIC with Regular Expressions
For more complex searches, we can use regular expressions as well in kwic(). For example, if you want to include terror and all its other related word forms, such as terrorist, terrorism, terrors, you can do a regular expression search.
By default, the kwic() is word-based. If you like to look up a multiword combination, use phrase():
It should be noted that the output of kwic includes not only the concordances (i.e., preceding/subsequent co-texts + the keyword), but also the sources of the texts for each concordance line. This would be extremely convenient if you need to refer back to the original discourse context of the concordance line.
Exercise 13.2 Please create a bar plot, showing the number of uses of the word country in each president’s address. Please include different variants of the word, e.g., countries, Countries, Country, in your kwic() search.

13.6 Lexical Density Plot
Plotting a kwic object produces a lexical dispersion plot, which allows us to visualize the occurrences of particular terms throughout the texts.

## subset the corpus
corp_us_subset <- corp_us_tokens %>%
tokens_subset(Year > 1949)
## Plotting
textplot_xray(kwic(corp_us_subset, pattern = "american"),
kwic(corp_us_subset, pattern = "people")) +
aes(color = keyword) + scale_color_manual(values = c('lightpink', 'royalblue'))
13.7 Collocation
The textstat_collocations() function in the quanteda package is designed to identify and analyze collocations in textual data. Collocations are sequences of words that frequently appear together in a given corpus, such as “strong coffee”, “ice cream” or “New York.” This function computes lexical associations to score and rank these word combinations, helping to uncover meaningful multi-word expressions or phrases.
We can consider removing irrelevant tokens before extracting collocations or multiword sequences.
The function textstat_collocations() allows you to specify the cutoff for minimum frequency as well (to avoid idiosyncratic patterns).
## collocation (filtered)
## Remove stopwords
corp_us_tokens %>%
tokens_remove(stopwords("en"), padding = TRUE) %>%
textstat_collocations(size = 2, min_count = 2, tolower = F)## collocation (filtered)
## Remvoe stopwords, include proper names only
corp_us_tokens %>%
tokens_remove(stopwords("en"), padding = TRUE) %>%
tokens_select(pattern = "^[A-Z]\\w+", valuetype = "regex",
case_insensitive = FALSE, padding = TRUE) %>%
textstat_collocations(size = 2, min_count = 2, tolower = F)13.8 Document-Feature Matrix
An essential object class in quanteda is the dfm, which stands for Document-Feature Matrix. This matrix is a two-dimensional table where the rows represent the documents in the corpus, and the columns represent the features (e.g., words or terms) used to describe the documents. The cells in the matrix typically contain co-occurrence statistics, quantifying how often each feature appears in a given document.
The usual workflow involves first creating a tokens object from the corpus using the tokens() function. Then, the dfm() function is applied to the tokens object to generate the dfm representation.
When creating the tokens object, you can specify which tokens (e.g., words or phrases) are relevant for your analysis, ensuring that only meaningful features are included in the dfm.
In summary, it is generally recommended to use a tokens object as the input when constructing a dfm.
[1] "dfm"
attr(,"package")
[1] "quanteda"Document-feature matrix of: 59 documents, 9,437 features (91.84% sparse) and 4 docvars.
features
docs fellow-citizens of the senate and house representatives :
1789-Washington 1 71 116 1 48 2 2 1
1793-Washington 0 11 13 0 2 0 0 1
1797-Adams 3 140 163 1 130 0 2 0
1801-Jefferson 2 104 130 0 81 0 0 1
1805-Jefferson 0 101 143 0 93 0 0 0
1809-Madison 1 69 104 0 43 0 0 0
features
docs among vicissitudes
1789-Washington 1 1
1793-Washington 0 0
1797-Adams 4 0
1801-Jefferson 1 0
1805-Jefferson 7 0
1809-Madison 0 0
[ reached max_ndoc ... 53 more documents, reached max_nfeat ... 9,427 more features ]We can see that in the first document, i.e., 1789-Washington, there are 2 occurrences of representatives, 48 occurrences of and.
13.9 Feature Selection
The dfm created above may not be as informative as expected because not all words contribute meaningfully to the document’s semantics.
To better represent the semantic content of a document, several critical aspects of the dfm features should be carefully considered:
- Granularity: The level of detail captured by the features.
- Informativeness: The relevance and significance of the features for the analysis.
- Distributional Properties: How the features are distributed across the documents.
Fortunately, the dfm() function provides various parameters that allow users to customize feature selection. In addition, in quanteda, the dfm_trim() function can be applied to refine the dfm by filtering important features based on distributional properties (e.g., frequency and document frequency counts).
corp_dfm_trimmed <- corp_us %>%
tokens( remove_punct = T,
remove_numbers= T,
remove_symbols = T) %>%
dfm %>%
dfm_remove(stopwords("en")) %>%
dfm_trim(min_termfreq = 10, termfreq_type = "count",
min_docfreq = 3, max_docfreq = ndoc(corp_us)-1,
docfreq_type = "count")
dim(corp_us_dfm)[1] 59 9437[1] 59 1402
13.10 Top Features
With a dfm, we can check important features from the corpus.
people government us can must upon great
584 564 505 487 376 371 344
may states world
343 334 319 We can also extract ngram-based features from each document for analysis:
Tokens consisting of 59 documents and 4 docvars.
1789-Washington :
[1] "Fellow-Citizens_of_the" "of_the_Senate"
[3] "the_Senate_and" "Senate_and_of"
[5] "and_of_the" "of_the_House"
[7] "the_House_of" "House_of_Representatives"
[9] "of_Representatives_:" "Representatives_:_Among"
[11] ":_Among_the" "Among_the_vicissitudes"
[ ... and 1,523 more ]
1793-Washington :
[1] "Fellow_citizens_," "citizens_,_I" ",_I_am"
[4] "I_am_again" "am_again_called" "again_called_upon"
[7] "called_upon_by" "upon_by_the" "by_the_voice"
[10] "the_voice_of" "voice_of_my" "of_my_country"
[ ... and 133 more ]
1797-Adams :
[1] "When_it_was" "it_was_first" "was_first_perceived"
[4] "first_perceived_," "perceived_,_in" ",_in_early"
[7] "in_early_times" "early_times_," "times_,_that"
[10] ",_that_no" "that_no_middle" "no_middle_course"
[ ... and 2,563 more ]
1801-Jefferson :
[1] "Friends_and_Fellow" "and_Fellow_Citizens" "Fellow_Citizens_:"
[4] "Citizens_:_Called" ":_Called_upon" "Called_upon_to"
[7] "upon_to_undertake" "to_undertake_the" "undertake_the_duties"
[10] "the_duties_of" "duties_of_the" "of_the_first"
[ ... and 1,909 more ]
1805-Jefferson :
[1] "Proceeding_,_fellow" ",_fellow_citizens"
[3] "fellow_citizens_," "citizens_,_to"
[5] ",_to_that" "to_that_qualification"
[7] "that_qualification_which" "qualification_which_the"
[9] "which_the_Constitution" "the_Constitution_requires"
[11] "Constitution_requires_before" "requires_before_my"
[ ... and 2,366 more ]
1809-Madison :
[1] "Unwilling_to_depart" "to_depart_from" "depart_from_examples"
[4] "from_examples_of" "examples_of_the" "of_the_most"
[7] "the_most_revered" "most_revered_authority" "revered_authority_,"
[10] "authority_,_I" ",_I_avail" "I_avail_myself"
[ ... and 1,247 more ]
[ reached max_ndoc ... 53 more documents ]corp_us_tokens %>%
tokens_ngrams(n = 3) %>%
dfm %>%
dfm_trim(min_termfreq = 5, termfreq_type = "count",
min_docfreq = 2, max_docfreq = ndoc(corp_us)-1,
docfreq_type = "count") -> corp_dfm_trigram
topfeatures(corp_dfm_trigram) ._it_is the_united_states ,_and_the ._we_have
156 152 137 101
of_the_united of_the_people of_the_government ._we_are
99 97 79 68
of_the_world ._we_will
63 63 How to remove irrelevant trigrams? (e.g., ones that include punctuation marks?)
the_united_states of_the_united of_the_people of_the_government
152 99 97 79
of_the_world of_our_country of_the_union of_our_people
63 49 49 48
as_well_as of_the_country
47 47 13.11 Wordclouds
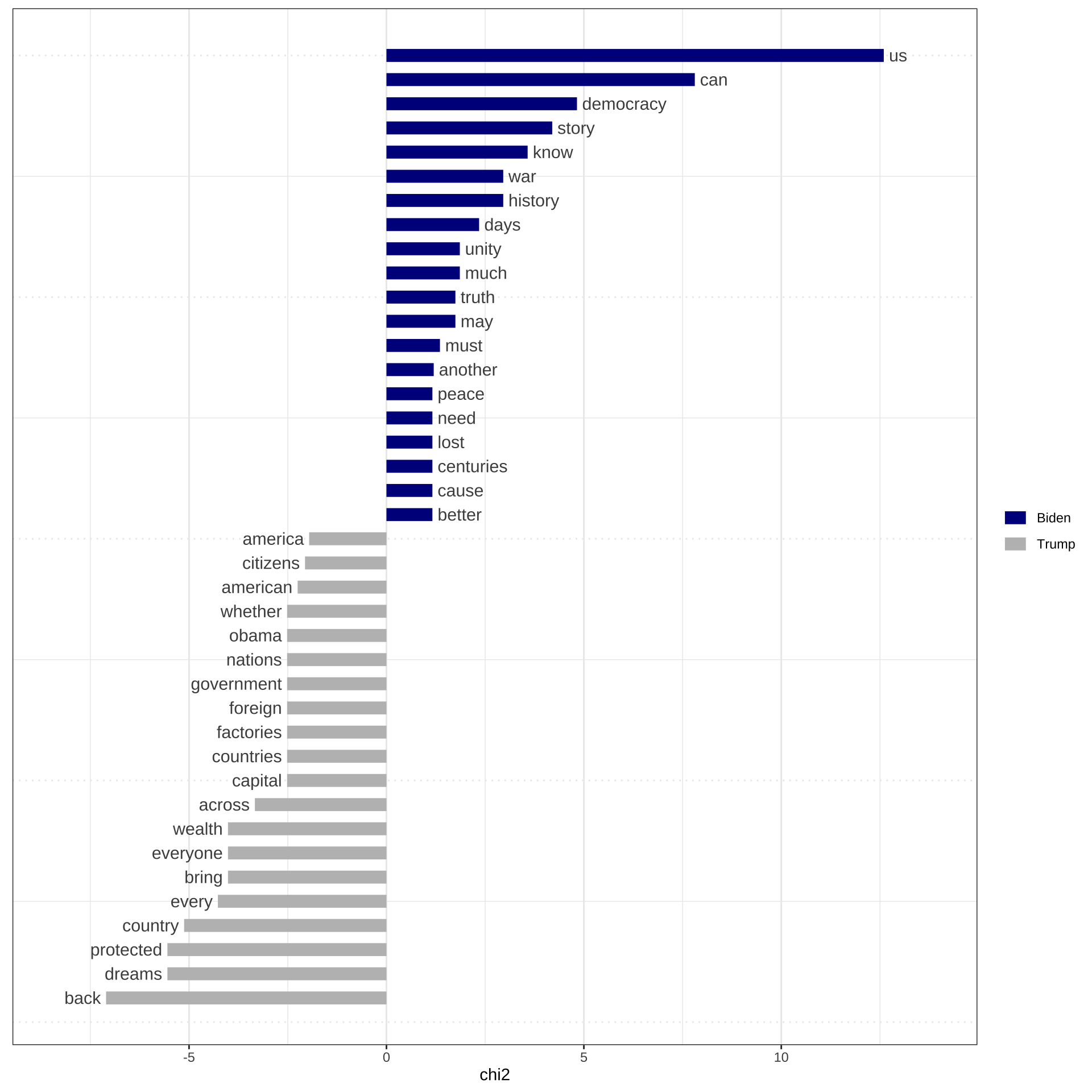
With a dfm, we can visualize important words in the corpus with a Word Cloud. It is a novel but intuitive visual representation of text data. It allows us to quickly perceive the most prominent words from a large collection of texts.
corp_dfm_trimmed %>%
textplot_wordcloud(min_count = 50, random_order = FALSE,
rotation = .25,
color = RColorBrewer::brewer.pal(10, "Paired"))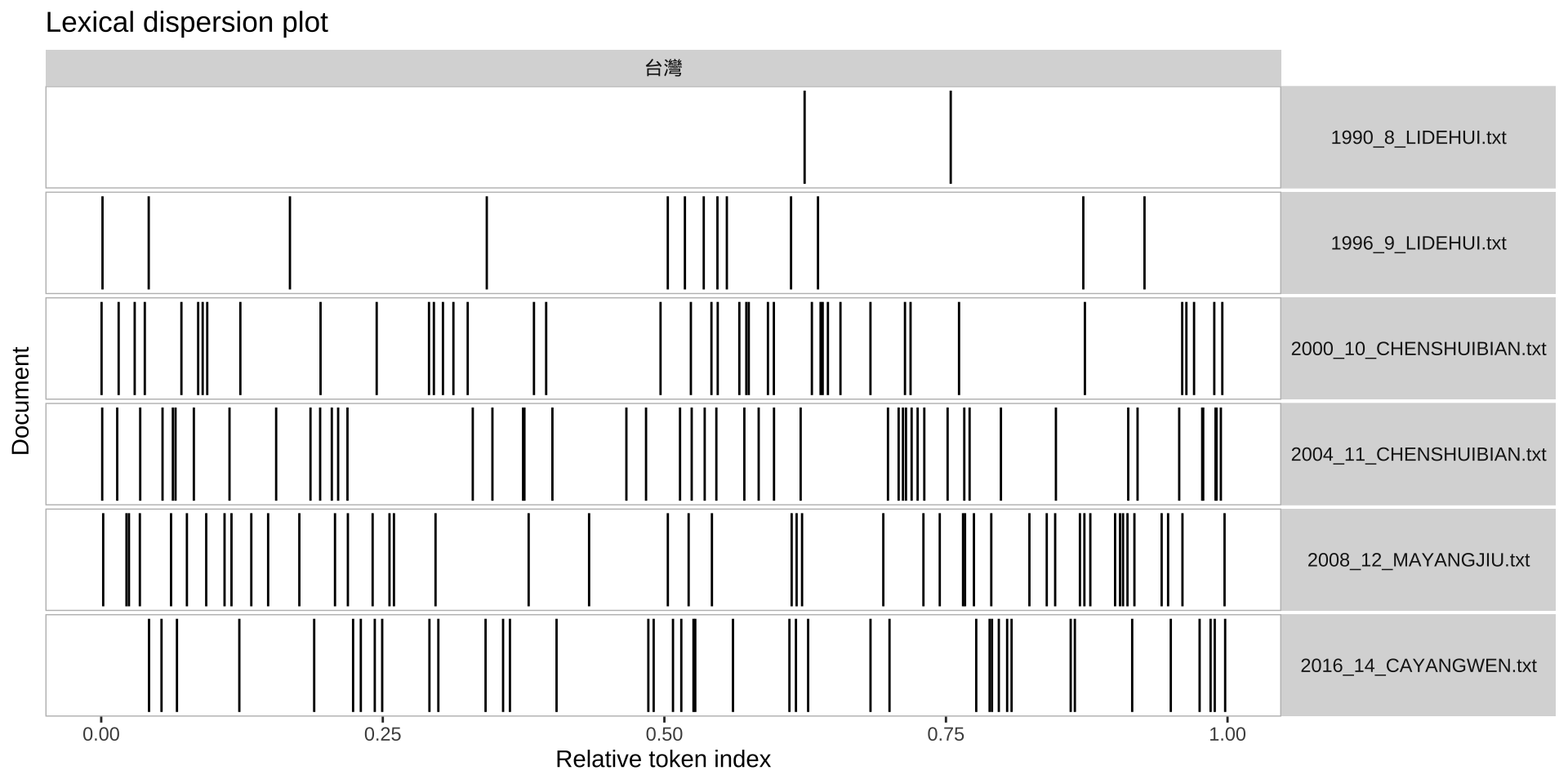
We can also compare word clouds for different subsets of the corpus. The key step is to group the documents according to a specific grouping factor using tokens_group().
corpus_subset(corp_us,
President %in% c("Obama", "Trump", "Clinton")) %>%
tokens(remove_punct = T,
remove_numbers= T,
remove_symbols = T) %>%
tokens_group(groups = President) %>%
dfm() %>%
dfm_remove(stopwords("en")) %>%
dfm_trim(min_termfreq = 5,
termfreq_type = "count") %>%
textplot_wordcloud(comparison = TRUE)
13.12 Keyness Analysis
When you have two collections of texts, we can use quantitative methods to identify which words are more strongly associated with one of the two sub-corpora. This is the idea of keyword analysis.
# Only select speeches by Obama and Trump
pres_corpus <- corpus_subset(corp_us,
President %in% c("Trump", "Biden"))
# Create a dfm grouped by president
pres_dfm <- pres_corpus %>%
tokens(remove_punct = T,
remove_numbers= T,
remove_symbols = T) %>%
tokens_remove(stopwords("en")) %>%
tokens_group(groups = President) %>%
dfm(tolower=F)
# Calculate keyness and determine Trump as target group
result_keyness <- textstat_keyness(pres_dfm,
target = "Biden",
measure = "lr")
# Plot estimated word keyness
textplot_keyness(result_keyness,
color = c("red", "blue"),
n = 30)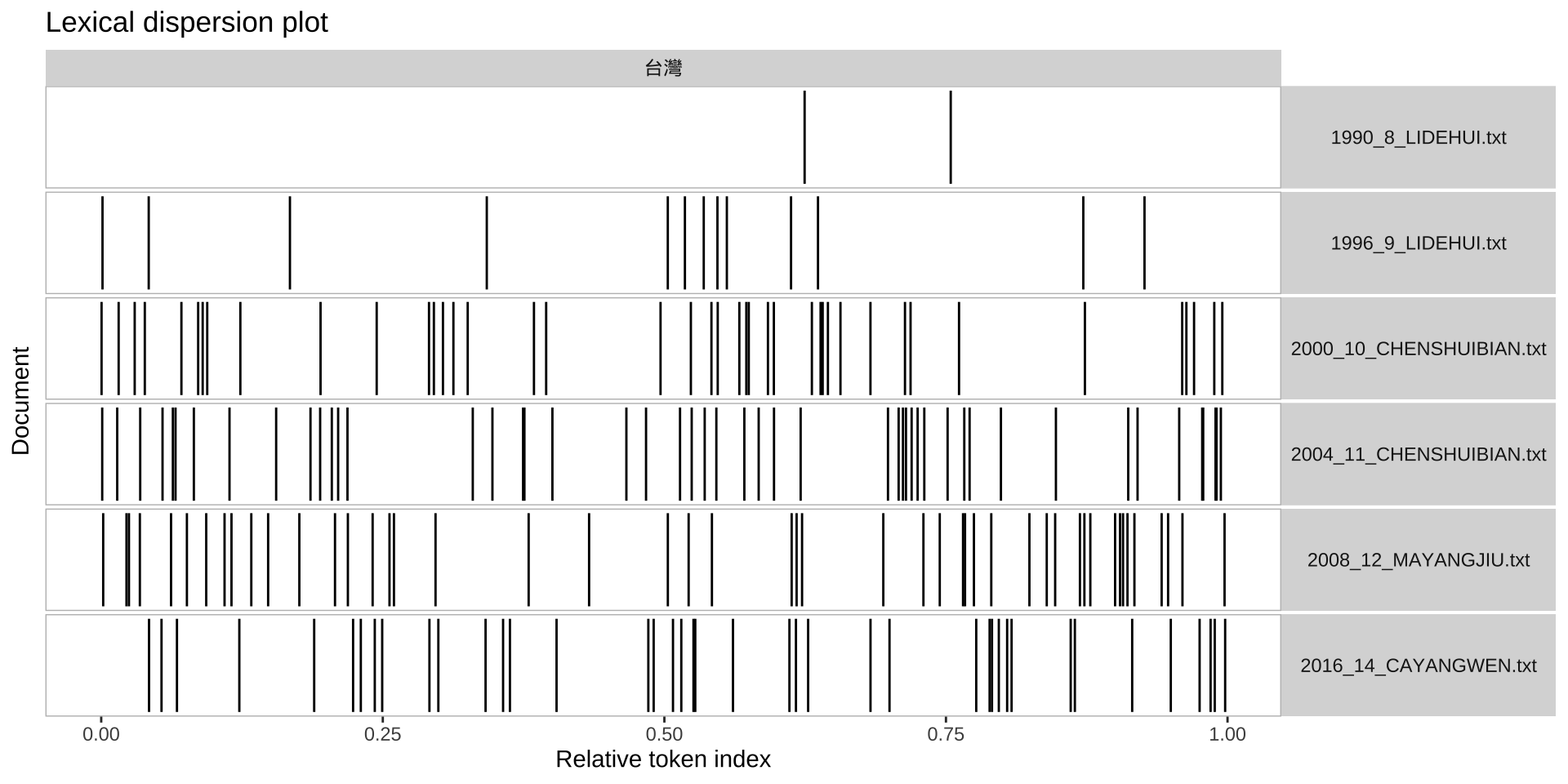
13.13 Flowchart
Finally, Figure 13.1 below provides a summary flowchart for computatutional text analytics in R.
Figure 13.1: Computational Text Processing Flowchart in R
13.14 Exercises
In the following exercise, please use the dataset demo_data/TW_President_zh.tar.gz, which is a text collection of the inaugural speeches of Taiwan Presidents (till 2024).
Corpus files often consist of a large number of documents, making it practical to compress them into a single file for efficient data exchange. One of the most common formats for this purpose is tar.gz.
A TAR, TAR.GZ, or GZ file is a widely used format for bundling and compressing data, particularly in Linux-based systems:
tarfile: A TAR (Tape Archive) file is an archive format that combines multiple files and directories into a single file without compression—like packing items into a box.
tar.gzfile: A TAR file that has been compressed using the gzip algorithm. It combines bundling (via TAR) and compression (via gzip), akin to sealing and shrinking the packed box.
gzfile: A file compressed using gzip directly, typically applied to a single file to reduce its size for easier storage or transfer.
You may load the entire text collection as a corpus object using the following code:
require(readtext)
require(quanteda)
corp_tw <- readtext("demo_data/TW_President_zh.tar.gz", verbosity = 0) %>%
corpusExercise 13.3 Please create a data frame, which includes the metadata information for each text. You may start with a data frame you get from summary(corp_tw) and then create three additional columns—Year, Term, and President, which can be extracted from the text filenames in the Text column.
Hint: tidyr::extract()
After you create the metadata DF, please assign it to the docvars(corp_tw) for later analysis.
Exercise 13.4 Please create a lexical density plot for the use of “台灣/臺灣” in all presidents’ texts.

Exercise 13.5 Please create comparative lexical density plots showing how each predisent uses “台灣/台灣” and “中國”.

Exercise 13.6 Please create a word cloud of the entire corpus corp_tw. In the word cloud, please remove punctuations, numbers, and symbols. The word cloud has to only include words whose frequency >= 15.

Exercise 13.7 Create word clouds showing the comparison of President Tsai (蔡英文), Ma (馬英九), and Shuibian Chen (陳水扁). (Same distributional critera as above.)

Exercise 13.8 Please create a keyness plot, showing the preferred words used by President Tsai (蔡英文) vs. President Ma (馬英九).

Exercise 13.9 Divide the corpus into two groups: Pan Blue (e.g., “蔣中正”, “蔣經國”, “李登輝”, “馬英九”) and Pan Green (the remaining presidents). Identify key collocations within each group and visualize them in a plot as described below.
In the plot:
- The x-axis represents the frequency count of the collocation.
- The y-axis represents the collocation’s z-score, indicating lexical association.
To determine “key collocations,” for each group, include only those that meet the following criteria:
- Remove all punctuations, numbers, and symbols.
- Consisting of no stopwords (
stopwords("zh", source="misc")). - A minimum frequency count (
min_count) of 10 for collocations.
- A z-score (z) of at least 3.29 (p < .0001).
