Chapter 3 Creating Corpus
Linguistic data are important to linguists. Data usually tell us something we don’t know, or something we are not sure of.
While there are many existing text data collections (cf. Structured Corpus and XML), chances are that sometimes you still need to collect your own data for a particular research question.
But please note that when you are creating your own corpus for specific research questions, always pay attention to the three important criteria: representativeness, authenticity, and size.
In this chapter, we will look at a quick way to extract linguistic data from web pages (i.e., web crawling), which are by now undoubtedly the largest sources of textual data.
Following the spirit of tidy , we will mainly do our tasks with the libraries of tidyverse and rvests.
If you are new to tidyverse R, please check its official webpage for learning resources.
## Uncomment the following line for installation
# install.packages(c("tidyverse", "rvest"))
library(tidyverse)
library(rvest)3.1 HTML Structure
The HyperText Markup Language, or HTML is the standard markup language for documents designed to be displayed in a web browser.
3.1.1 HTML Syntax
To illustrate the structure of the HTML, please download the sample html file from: demo_data/data-sample-html.html and first open it with your browser.
<!DOCTYPE html>
<html>
<head>
<title>My First HTML </title>
</head>
<body>
<h1> Introduction </h1>
<p> Have you ever read the source code of a html page? This is how to get back to the course page: <a href="https://alvinntnu.github.io/NTNU_ENC2036_LECTURES/", target="_blank">ENC2036</a>. </p>
<h1> Contents of the Page </h1>
<p> Anything you can say about the page.....</p>
</body>
</html>An HTML document includes several important elements (cf. Figure 3.1):
DTD: document type definition which informs the browser about the version of the HTML standard that the document adheres to (e.g.,<!DOCTYPE HTML>)element: the combination of start tag, content, and end tag (e.g,<title>My First HTML</title>)tag: named braces that enclose the content and define its structural function (e.g.,title,body,p)attribute: specific properties of the tag, which are often placed in the start end of the element (e.g.,<a href= "index.html"> Homepage </a>). They are expressed asname = "value"pairs.
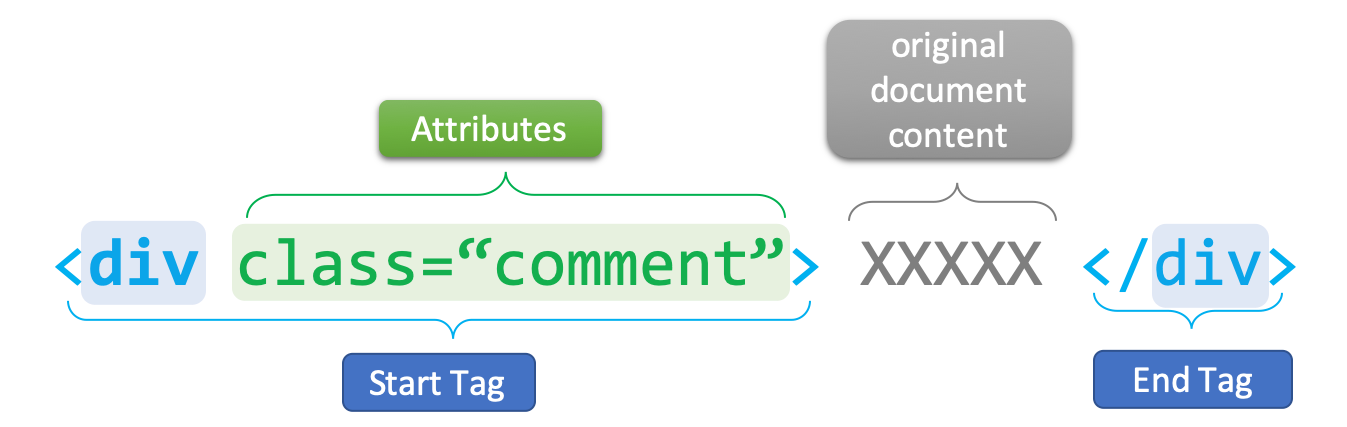
Figure 3.1: Syntax of An HTML Tag Element
An HTML document starts with the root element <html>, which splits into two branches, <head> and <body>.
- Most of the webpage textual contents would go into the
<body>part. - Most of the web-related codes and metadata (e.g., javascripts, CSS) are often included in the
<head>part.
All elements need to be strictly nested within each other in a well-formed and valid HTML file, as shown in Figure 3.2.
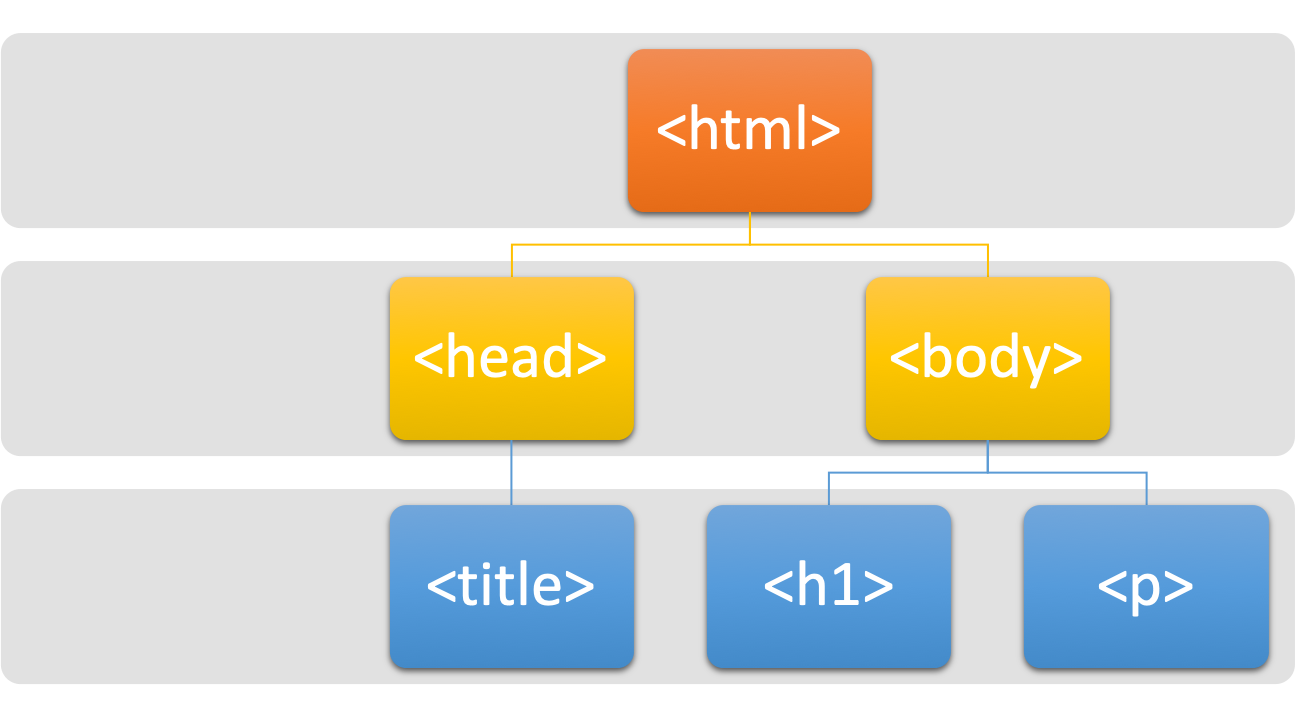
Figure 3.2: Tree Structure of An HTML Document
3.1.3 CSS
Cascading Style Sheet (CSS) is a language for describing the layout of HTML and other markup documents (e.g., XML).
HTML + CSS is by now the standard way to create and design web pages. The idea is that CSS specifies the formats/styles of the HTML elements. The following is an example of the CSS:
div.warnings {
color: pink;
font-family: "Arial"
font-size: 120%
}
h1 {
padding-top: 20px
padding-bottom: 20px
}You probably would wonder how to link a set of CSS style definitions to an HTML document. There are in general three ways: inline, internal and external. You can learn more about this in W3School.com.
Here I will show you an example of the internal method. Below is a CSS style definition for <h1>.
h1 {
color: red;
margin-bottom: 2em;
}We can embed this within a <style>...</style> element. Then you put the entire <style> element under <head> of the HTML file you would like to style.
<style>
h1 {
color: red;
margin-bottom: 1.5em;
}
</style>After you include the <style> in the HTML file, refresh the web page to see if the CSS style works.

3.2 Web Crawling
In the following demonstration, the text data scraped from the PTT forum is presented as it is without adjustment. Therefore, the language on PTT may strike some readers as profane, vulgar or even offensive.
When scraping data from PTT, it is important to manage the frequency of your requests. If the website detects an unusually high volume of automated traffic from a single source, it may temporarily or permanently block your IP address to prevent server strain.
To avoid being flagged as a bot, you should implement small delays between your requests and avoid running large-scale scraping tasks too rapidly. Ensuring your script mimics natural browsing behavior will help maintain your access to the site for future data collection.
3.2.1 Index Pages
In this tutorial, let’s assume that we like to scrape texts from PTT Forum. In particular, we will demonstrate how to scrape texts from the Gossiping board of PTT.
- First, we create an
session(). (This process is similar to opening a web browser, which can be used to navigate to a specific web page.)
## initialize the session
gossiping.session <- session(
ptt.url,
config = httr::add_headers( ## package cookies & user-agent for server
Cookie = "over18=1", ## age verification cookie
`User-Agent` = "Mozilla/5.0" ## identify the crawler as a standard browswer
)
)
gossiping.session$response$url[1] "https://www.ptt.cc/bbs/Gossiping/index.html"If you use your browser to view PTT Gossiping page, you would see that you need to go through the age verification before you can enter the content page. So, our first job is to make sure that the session is able to pass through this age verification.
Check the current url of your gossiping.session:
[1] "https://www.ptt.cc/bbs/Gossiping/index.html"If the session’s current url is NOT https://www.ptt.cc/bbs/Gossiping/index.html, we may need to get pass the age verification page before you can access the bulletin posts.
We can extract the age verification form from the current page (form is also a defined HTML element)
Then we automatically submit an yes to the age verification form in the earlier created session() and create another session.
Now our html session, i.e., gossiping.session, should be on the front page of the Gossiping board.
Most browsers come with the functionality to inspect the page source code (i.e., HTML). This is very useful for web crawling. Before we scrape data from the webpage, we often need to inspect the structure of the web page first.
Most importantly, we need to know (a) which HTML elements, or (b) which particular attributes/values of the HTML elements we are interested in .
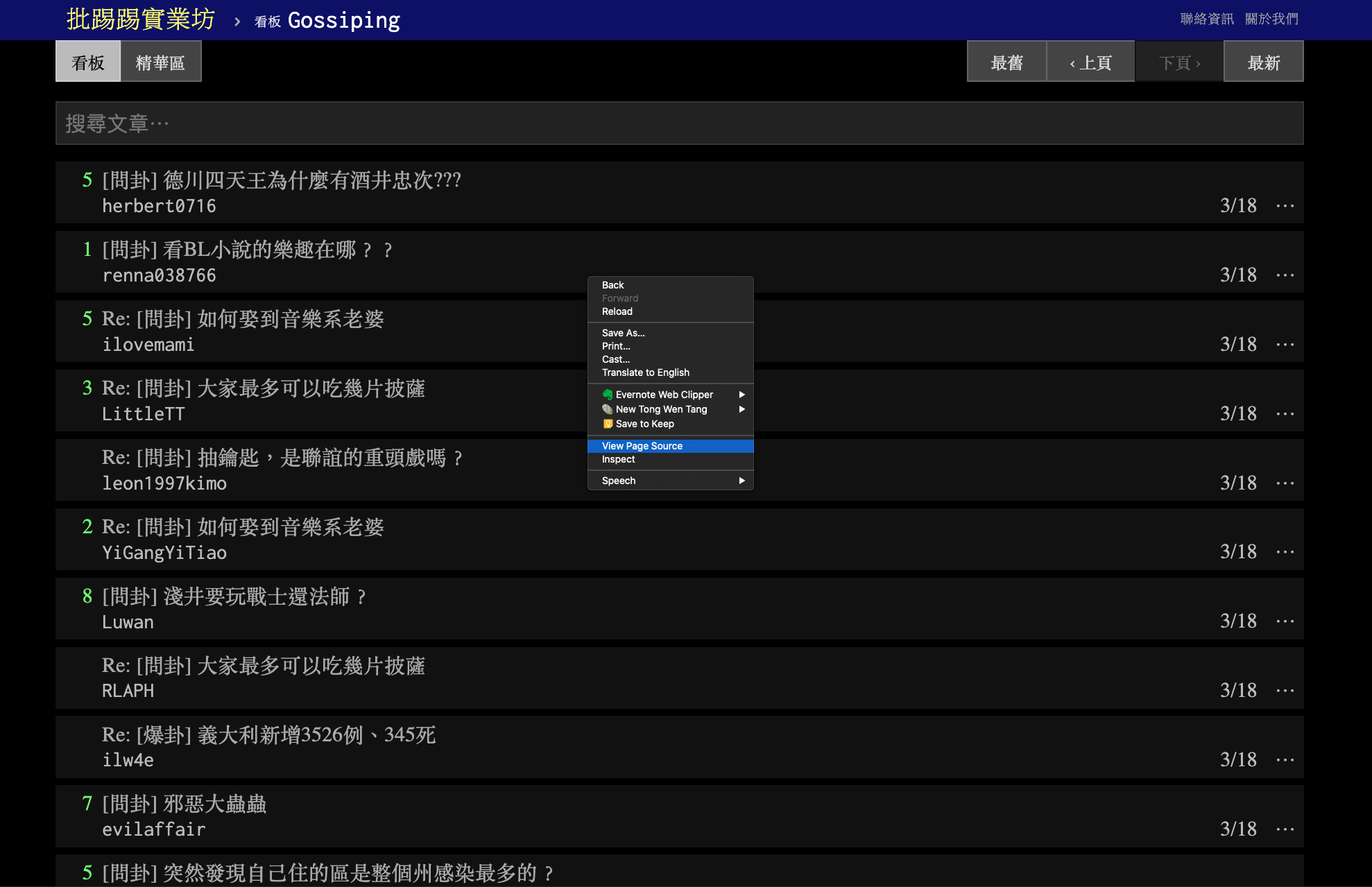
- Next we need to find the most recent index page of the board
## Decide the number of index pages ----
page.latest <- gossiping.session %>%
html_nodes("a") %>% ## extract all <a> elements
html_attr("href") %>% ## extract the attributes `href`
str_subset("index[0-9]{2,}\\.html") %>% # find the `href` with the index number
str_extract("[0-9]+") %>% ## extract the number
as.numeric()
page.latest[1] 39090- On the most recent index page, we need to extract the hyperlinks to the articles
## Retreive links
## Create the web address for the most recent index page
link <- str_c(ptt.url, "/index", page.latest, ".html")
## Visit the page and extract article links
links.article <- gossiping.session %>%
session_jump_to(link) %>% ## move the session to the most recent index web page
html_nodes("a") %>% ## extract article HTML elements <a>
html_attr("href") %>% ## extract article <a> `href` attributes
str_subset("[A-z]\\.[0-9]+\\.[A-z]\\.[A-z0-9]+\\.html") %>% ## extract article hyperlinks
str_c("https://www.ptt.cc",.) ## add domain names for article links
## inspect article links of the page
links.article [1] "https://www.ptt.cc/bbs/Gossiping/M.1779296798.A.B1E.html"
[2] "https://www.ptt.cc/bbs/Gossiping/M.1779296809.A.602.html"
[3] "https://www.ptt.cc/bbs/Gossiping/M.1779297208.A.791.html"
[4] "https://www.ptt.cc/bbs/Gossiping/M.1779297305.A.2B1.html"
[5] "https://www.ptt.cc/bbs/Gossiping/M.1779297675.A.2CF.html"
[6] "https://www.ptt.cc/bbs/Gossiping/M.1779297780.A.982.html"
[7] "https://www.ptt.cc/bbs/Gossiping/M.1779297884.A.794.html"
[8] "https://www.ptt.cc/bbs/Gossiping/M.1779297888.A.D66.html"
[9] "https://www.ptt.cc/bbs/Gossiping/M.1779297960.A.342.html"
[10] "https://www.ptt.cc/bbs/Gossiping/M.1779298036.A.13C.html"
[11] "https://www.ptt.cc/bbs/Gossiping/M.1779298164.A.B33.html"
[12] "https://www.ptt.cc/bbs/Gossiping/M.1779298501.A.E41.html"
[13] "https://www.ptt.cc/bbs/Gossiping/M.1779298688.A.E4F.html"
[14] "https://www.ptt.cc/bbs/Gossiping/M.1779298777.A.3EB.html"
[15] "https://www.ptt.cc/bbs/Gossiping/M.1779299929.A.86C.html"
[16] "https://www.ptt.cc/bbs/Gossiping/M.1779299941.A.67E.html"
[17] "https://www.ptt.cc/bbs/Gossiping/M.1779300084.A.466.html"
[18] "https://www.ptt.cc/bbs/Gossiping/M.1779300230.A.928.html"
[19] "https://www.ptt.cc/bbs/Gossiping/M.1779300241.A.7C0.html"
[20] "https://www.ptt.cc/bbs/Gossiping/M.1779300760.A.BDD.html"3.2.2 Extract Post Texts
- Next step is to scrape texts from each article hyperlink. Let’s consider one link first.
## check first article link
article.url <- links.article[1]
## move current session to the first article link
temp.html <- gossiping.session %>%
session_jump_to(article.url)- Now the
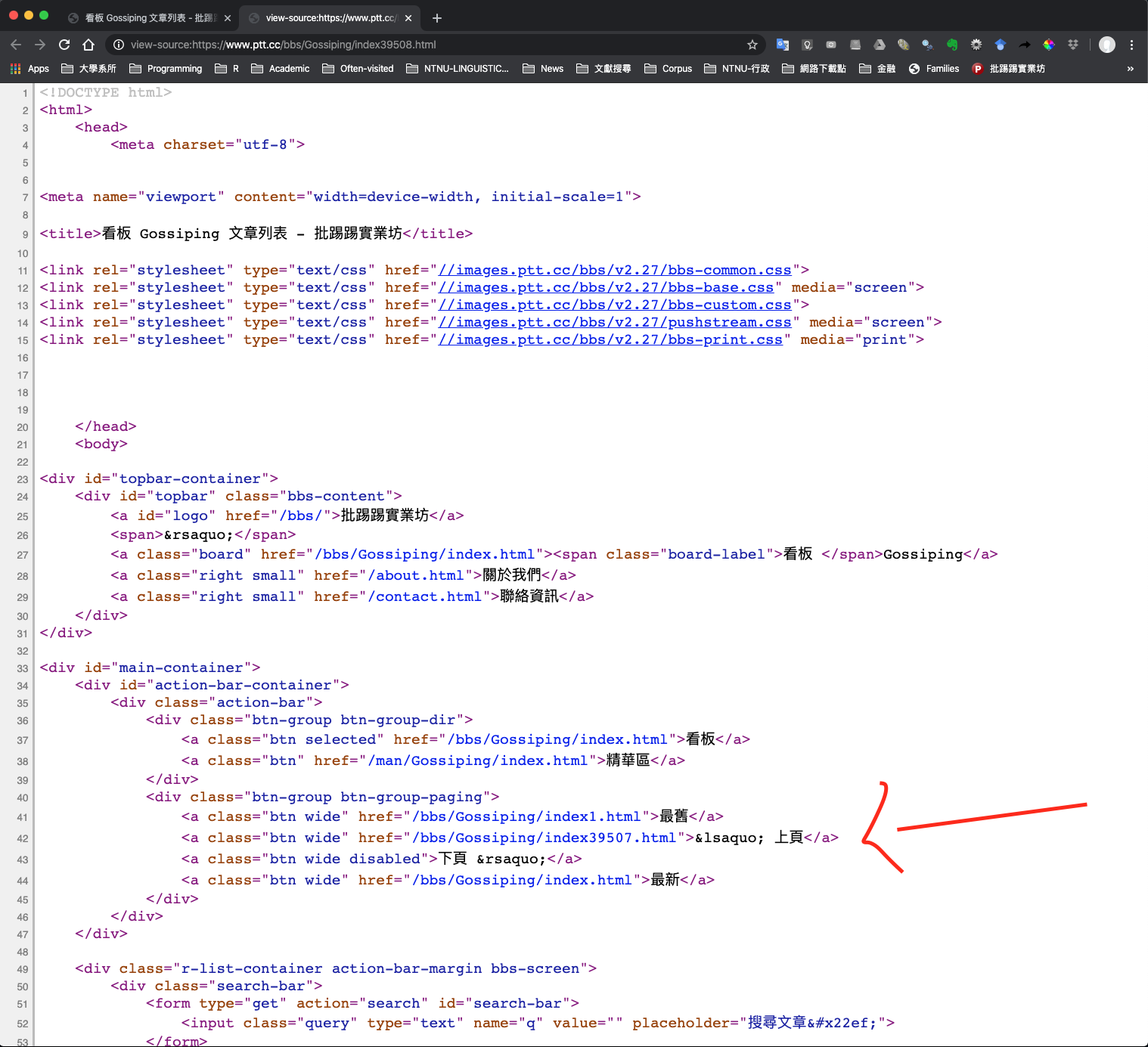
temp.htmlis a session on the article page. Because we are interested in the metadata and the contents of each article, now the question is: where are they in the HTML? We need to go back to the source page of the article HTML again:
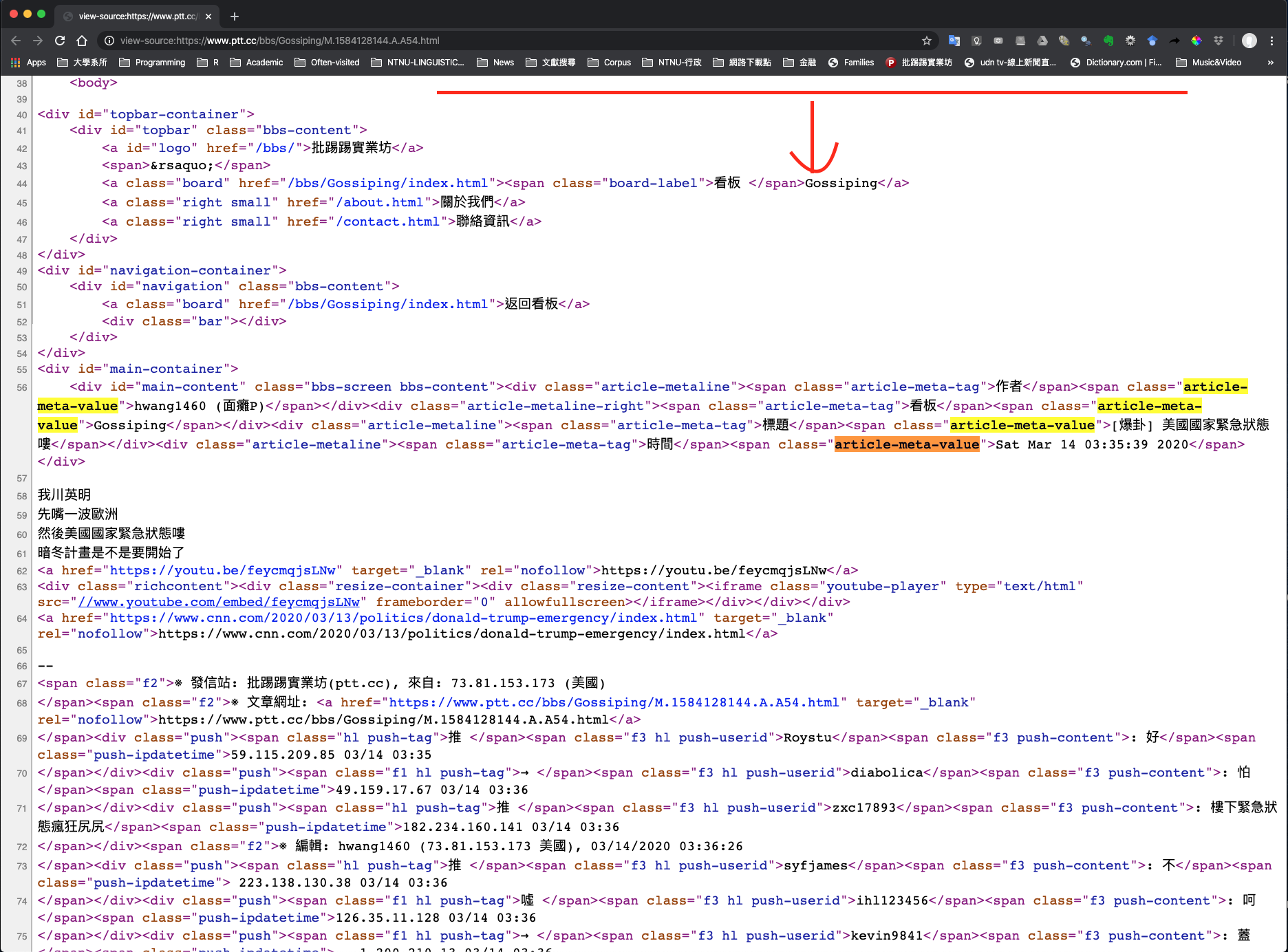
Figure 3.3: HTML of an Article Page
Inspecting the article’s HTML reveals a clear structure for the data:
- All relevant information is housed within the
<div id="main-content">container. - Inside this section, article metadata – such as the author or date – is stored specifically within
<span>tags using thearticle-meta-valueclass (e.g.,<span class="article-meta-value"> ... </span>) - The main body of the text is located directly within the
<div id="main-content">block, alongside these metadata elements.
- All relevant information is housed within the
- Now we are ready to extract the metadata of the article.
## Extract article metadata
article.header <- temp.html %>%
html_nodes("span.article-meta-value") %>% ## get <span> of a particular class
html_text()
article.header[1] "PCC9169 (PCC)" "Gossiping"
[3] "[問卦] 我們原住民還有出歌嗎?" "Thu May 21 01:06:36 2026" The metadata of each PTT article in fact includes four pieces of information: author, board name, title, post time. The above code retrieves directly the values of these metadata.
We can retrieve the tags of these metadata values as well:
temp.html %>%
html_nodes("span.article-meta-tag") %>% ## get <span> of a particular class
html_text()[1] "作者" "看板" "標題" "時間"- From the
article.header, we are able to extract theauthor,title, andtime stampof the article.
article.author <- article.header[1] %>% str_extract("^[A-z0-9_]+") ## athuor
article.title <- article.header[3] ## title
article.datetime <- article.header[4] ## time stamp
article.author[1] "PCC9169"[1] "[問卦] 我們原住民還有出歌嗎?"[1] "Thu May 21 01:06:36 2026"- Now we extract the main contents of the article
article.content <- temp.html %>%
html_nodes( ## article body
xpath = '//div[@id="main-content"]/node()[not(self::div|self::span[@class="f2"])]'
) %>%
html_text(trim = TRUE) %>% ## extract texts
str_c(collapse = "") ## combine all lines into one
article.content[1] "最近雲南德宏景頗族 挺火的\n\n目瑙縱歌 也挺好聽的 下面是同首歌https://www.youtube.com/watch?v=ukV2JfnTs_M(現場錄影 但歌詞錯很多)https://www.youtube.com/watch?v=FIZ7JBSfVkQAI影片https://v.douyin.com/5uvujcqJuwI/陸抖 服裝很有趣阿 感覺在上朝\n\n有幾個妹子挺好看的https://v.douyin.com/1HO18tu0c48/我就在想 最近幾年我們原住民是不是聲量很小了\n\n也沒有啥大的豐年祭聲音?\n\n感覺上一次火熱的時候是原住民唱奧運歌曲了?!\n\n\n救國旅這個不是是一個好方法嗎????\n\n我們原住民還有在寫歌嗎(指的不是流行歌曲)???\n\n--舅媽 怎麼是你"XPath (or XML Path Language) is a query language which is useful for addressing and extracting particular elements from XML/HTML documents. XPath allows you to exploit more features of the hierarchical tree that an HTML file represents in locating the relevant HTML elements. For more information, please see Munzert et al. (2014), Chapter 4.
The XPath '//div[@id="main-content"]/node()[not(self::div|self::span[@class="f2"])]' acts as a filter to extract the main text of an article while stripping away unwanted metadata or structural tags.
- First,
//div[@id="main-content"]locates the primary container holding the article. - The
/node()command then selects every item directly inside that container, including raw text and HTML tags. - Finally, the filter
[not(self::div|self::span[@class="f2"])]instructs thehtml_nodes()to ignore any<div>elements or<span>elements labeled with the class"f2".
In short, the XPath identifies the nodes under <div id = "main-content">, but excludes their sister nodes that are <div> or <span class="f2">.
These children elements <div> or <span class="f2"> of the <div id = "main-content"> include the push comments (推文) of the article, which are not the main content of the article.
- Now we can combine all information related to the article into a data frame
article.table <- tibble(
datetime = article.datetime,
title = article.title,
author = article.author,
content = article.content,
url = article.url
)
article.table3.2.3 Extract Post Comments
- Next we extract the push comments at the end of the article
article.push <- temp.html %>%
html_nodes(xpath = "//div[@class = 'push']")
# ## or
# article.push <- temp.html %>%
# html_nodes("div.push")
article.push{xml_nodeset (8)}
[1] <div class="push">\n<span class="hl push-tag">推 </span><span class="f3 hl ...
[2] <div class="push">\n<span class="f1 hl push-tag">噓 </span><span class="f3 ...
[3] <div class="push">\n<span class="hl push-tag">推 </span><span class="f3 hl ...
[4] <div class="push">\n<span class="f1 hl push-tag">→ </span><span class="f3 ...
[5] <div class="push">\n<span class="f1 hl push-tag">→ </span><span class="f3 ...
[6] <div class="push">\n<span class="hl push-tag">推 </span><span class="f3 hl ...
[7] <div class="push">\n<span class="f1 hl push-tag">→ </span><span class="f3 ...
[8] <div class="push">\n<span class="f1 hl push-tag">→ </span><span class="f3 ...We then extract relevant information from each push nodes
article.push.- push types
- push authors
- push contents
## push tags
push.table.tag <- article.push %>%
html_nodes("span.push-tag") %>%
html_text(trim = TRUE) ## push types (like or dislike)
push.table.tag[1] "推" "噓" "推" "→" "→" "推" "→" "→" ## push authors
push.table.author <- article.push %>%
html_nodes("span.push-userid") %>%
html_text(trim = TRUE) ## author
push.table.author[1] "woaifafewen" "tearness" "STAV72" "STAV72" "STAV72"
[6] "STAV72" "Ricey" "leterg" ## push contents
push.table.content <- article.push %>%
html_nodes("span.push-content") %>%
html_text(trim = TRUE)
push.table.content[1] ": 你長得像我uncle"
[2] ": 可不可以插一下下就好"
[3] ": 人家的檳榔是真正的檳榔,我們的檳榔是人"
[4] ": 家的丟掉的我們把它撿起來,後已壓侯嗨呀"
[5] ": !"
[6] ": https://youtu.be/KCFeO30Qnb0"
[7] ": 沒辦法 被漢人打壓"
[8] ": 對啊,現在連豐年祭都沒在推了" ## push time
push.table.datetime <- article.push %>%
html_nodes("span.push-ipdatetime") %>%
html_text(trim = TRUE) ## push time stamp
push.table.datetime[1] "49.216.89.195 05/21 01:14" "36.231.187.211 05/21 01:15"
[3] "49.216.163.9 05/21 01:25" "49.216.163.9 05/21 01:25"
[5] "49.216.163.9 05/21 01:25" "49.216.163.9 05/21 01:27"
[7] "174.0.233.252 05/21 02:33" "101.8.224.214 05/21 03:07" - Finally, we combine all into one Push data frame.
## Integrate comments into a DF
push.table <- tibble(
tag = push.table.tag,
author = push.table.author,
content = push.table.content,
datetime = push.table.datetime,
url = article.url)
push.table3.3 Functional Programming
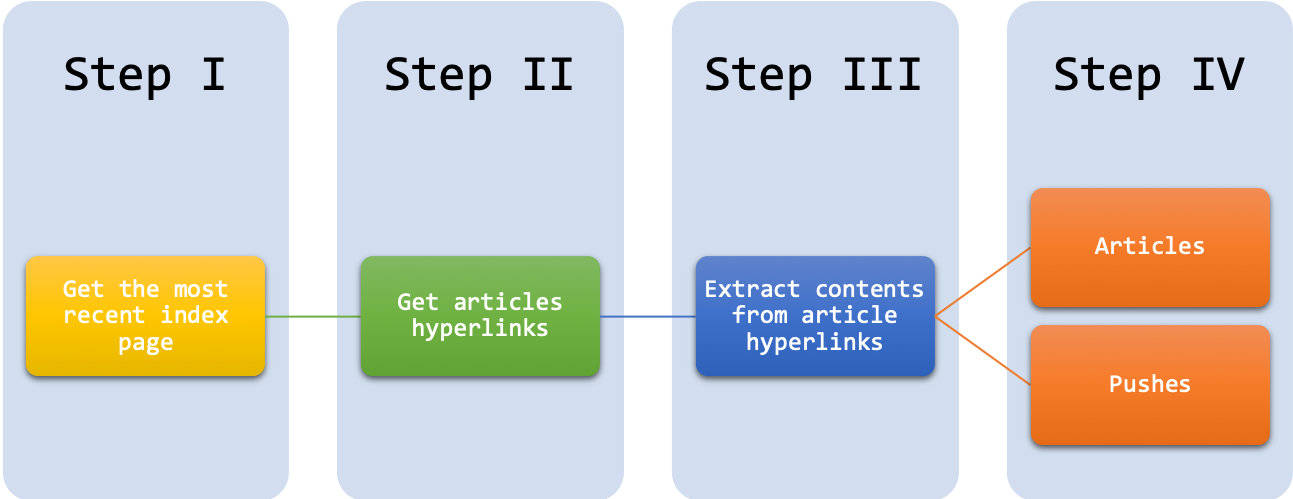
It should now be clear that there are several routines that we need to do again and again if we want to collect text data in large amounts:
- For each index page, we need to extract all the article hyperlinks of the page.
- For each article hyperlink, we need to extract the article content, metadata, and the push comments.
So, it would be great if we can wrap these two routines into two functions.
3.3.1 extract_art_links()
extract_art_links(): This function takes an HTML sessionsessionand an index page of the PTT Gossipingindex_pageas the arguments and extract all article links from the index page. It returns a vector of article links.
extract_art_links <- function(index_page, session){
links.article <- session %>%
session_jump_to(index_page) %>%
html_nodes("a") %>%
html_attr("href") %>%
str_subset("[A-z]\\.[0-9]+\\.[A-z]\\.[A-z0-9]+\\.html") %>%
str_c("https://www.ptt.cc",.)
return(links.article)
}For example, we can extract all the article links from the most recent index page:
## Get index page
cur_index_page <- str_c(ptt.url, "/index", page.latest, ".html")
## Get all article links from the most recent index page
cur_art_links <-extract_art_links(cur_index_page, gossiping.session)
cur_art_links [1] "https://www.ptt.cc/bbs/Gossiping/M.1779296798.A.B1E.html"
[2] "https://www.ptt.cc/bbs/Gossiping/M.1779296809.A.602.html"
[3] "https://www.ptt.cc/bbs/Gossiping/M.1779297208.A.791.html"
[4] "https://www.ptt.cc/bbs/Gossiping/M.1779297305.A.2B1.html"
[5] "https://www.ptt.cc/bbs/Gossiping/M.1779297675.A.2CF.html"
[6] "https://www.ptt.cc/bbs/Gossiping/M.1779297780.A.982.html"
[7] "https://www.ptt.cc/bbs/Gossiping/M.1779297884.A.794.html"
[8] "https://www.ptt.cc/bbs/Gossiping/M.1779297888.A.D66.html"
[9] "https://www.ptt.cc/bbs/Gossiping/M.1779297960.A.342.html"
[10] "https://www.ptt.cc/bbs/Gossiping/M.1779298036.A.13C.html"
[11] "https://www.ptt.cc/bbs/Gossiping/M.1779298164.A.B33.html"
[12] "https://www.ptt.cc/bbs/Gossiping/M.1779298501.A.E41.html"
[13] "https://www.ptt.cc/bbs/Gossiping/M.1779298688.A.E4F.html"
[14] "https://www.ptt.cc/bbs/Gossiping/M.1779298777.A.3EB.html"
[15] "https://www.ptt.cc/bbs/Gossiping/M.1779299929.A.86C.html"
[16] "https://www.ptt.cc/bbs/Gossiping/M.1779299941.A.67E.html"
[17] "https://www.ptt.cc/bbs/Gossiping/M.1779300084.A.466.html"
[18] "https://www.ptt.cc/bbs/Gossiping/M.1779300230.A.928.html"
[19] "https://www.ptt.cc/bbs/Gossiping/M.1779300241.A.7C0.html"
[20] "https://www.ptt.cc/bbs/Gossiping/M.1779300760.A.BDD.html"3.3.2 extract_article_push_tables()
extract_article_push_tables(): This function takes an article linklinkas the argument and extracts the metadata, textual contents, and pushes of the article. It returns a list of two elements—article and push data frames.
extract_article_push_tables <- function(link){
article.url <- link
temp.html <- gossiping.session %>% session_jump_to(article.url) ## link to the www
## article header
article.header <- temp.html %>%
html_nodes("span.article-meta-value") %>% ## meta info regarding the article
html_text()
## article meta
article.author <- article.header[1] %>% str_extract("^[A-z0-9_]+") ## athuor
article.title <- article.header[3] ## title
article.datetime <- article.header[4] ## time stamp
## article content
article.content <- temp.html %>%
html_nodes( ## article body
xpath = '//div[@id="main-content"]/node()[not(self::div|self::span[@class="f2"])]'
) %>%
html_text(trim = TRUE) %>%
str_c(collapse = "")
## Merge article table
article.table <- tibble(
datetime = article.datetime,
title = article.title,
author = article.author,
content = article.content,
url = article.url
)
## push nodes
article.push <- temp.html %>%
html_nodes(xpath = "//div[@class = 'push']") ## extracting pushes
## NOTE: If CSS is used, div.push does a lazy match (extracting div.push.... also)
## push tags
push.table.tag <- article.push %>%
html_nodes("span.push-tag") %>%
html_text(trim = TRUE) ## push types (like or dislike)
## push author id
push.table.author <- article.push %>%
html_nodes("span.push-userid") %>%
html_text(trim = TRUE) ## author
## push content
push.table.content <- article.push %>%
html_nodes("span.push-content") %>%
html_text(trim = TRUE)
## push datetime
push.table.datetime <- article.push %>%
html_nodes("span.push-ipdatetime") %>%
html_text(trim = TRUE) # push time stamp
## merge push table
push.table <- tibble(
tag = push.table.tag,
author = push.table.author,
content = push.table.content,
datetime = push.table.datetime,
url = article.url
)
## return
return(list(article.table = article.table,
push.table = push.table))
}## endfuncFor example, we can get the article and push tables from the first article link:
$article.table
# A tibble: 1 × 5
datetime title author content url
<chr> <chr> <chr> <chr> <chr>
1 Thu May 21 01:06:36 2026 [問卦] 我們原住民還有出歌嗎? PCC9169 "最近雲南德宏景頗… http…
$push.table
# A tibble: 8 × 5
tag author content datetime url
<chr> <chr> <chr> <chr> <chr>
1 推 woaifafewen : 你長得像我uncle 49.216.89.19… http…
2 噓 tearness : 可不可以插一下下就好 36.231.187.2… http…
3 推 STAV72 : 人家的檳榔是真正的檳榔,我們的檳榔是人 49.216.163.9… http…
4 → STAV72 : 家的丟掉的我們把它撿起來,後已壓侯嗨呀 49.216.163.9… http…
5 → STAV72 : ! 49.216.163.9… http…
6 推 STAV72 : https://youtu.be/KCFeO30Qnb0 49.216.163.9… http…
7 → Ricey : 沒辦法 被漢人打壓 174.0.233.25… http…
8 → leterg : 對啊,現在連豐年祭都沒在推了 101.8.224.21… http…3.3.3 Streamline the Codes
Now we can simplify our codes quite a bit:
## Get index page
cur_index_page <- str_c(ptt.url, "/index", page.latest, ".html")
## Scrape all article.tables and push.tables from each article hyperlink
cur_index_page %>% ## from this index page
extract_art_links(session = gossiping.session) %>% ## extract all article hyperlinks
map(extract_article_push_tables) -> ptt_data ## for each art hyperlin, extract data[1] 20- Finally, the last thing we can do is to combine all article tables from each index page into one; and all push tables into one for later analysis.
## Merge all article.tables into one
article.table.all <- ptt_data %>%
map(function(x) x$article.table) %>% ## subset each article's text content df
bind_rows
## Merge all push.tables into one
push.table.all <- ptt_data %>%
map(function(x) x$push.table) %>% ## subset each article's push df
bind_rows
article.table.allThere is still one problem with the Push data frame. Right now it is still not very clear how we can match the pushes to the articles from which they were extracted. The only shared index is the url. It would be better if all the articles in the data frame have their own unique indices and in the Push data frame each push comment corresponds to a particular article index.
The following graph summarizes our work flowchart for PTT Gossipping Scraping:
3.5 Additional Resources
Collecting texts and digitizing them into machine-readable files is only the initial step for corpus construction. There are many other things that need to be considered to ensure the effectiveness and the sustainability of the corpus data. In particular, I would like to point you to a very useful resource, Developing Linguistic Corpora: A Guide to Good Practice, compiled by Martin Wynne. Other important issues in corpus creation include:
- Adding linguistic annotations to the corpus data (cf. Leech’s Chapter 2)
- Metadata representation of the documents (cf. Burnard’s Chapter 4)
- Spoken corpora (cf. Thompson’s Chapter 5)
- Technical parts for corpus creation (cf. Sinclair’s Appendix)
3.6 Final Remarks
- Please pay attention to the ethical aspects involved in the process of web crawling (esp. with personal private matters).
- If the website has their own API built specifically for one to gather data, use it instead of scraping.
- Always read the terms and conditions provided by the website regarding data gathering.
- Always be gentle with the data scraping (e.g., off-peak hours, spacing out the requests)
- Value the data you gather and treat the data with respect.
Exercise 3.1 Can you modify the R codes so that the script can automatically scrape more than one index page?
Exercise 3.2 Please utilize the code from Exercise 3.1 and collect all texts on PTT/Gossipings from 3 index pages. Please have the articles saved in PTT_GOSSIPING_ARTICLE.csv and the pushes saved in PTT_GOSSIPING_PUSH.csv under your working directory.
Also, at the end of your code, please also output in the Console the corpus size, including both the articles and the pushes. Please provide the total number of characters of all your PTT text data collected (Note: You DO NOT have to do the word segmentation yet. Please use the characters as the base unit for corpus size.)
Hint: nchar()
Your script may look something like:
## I define my own `scrapePTT()` function:
## ptt_url: specify the board to scrape texts from
## num_index_page: specify the number of index pages to be scraped
## return: list(article, push)
PTT_data <-scrapePTT(ptt_url = "https://www.ptt.cc/bbs/Gossiping", num_index_page = 3)
PTT_data$article %>% head[1] 21106Exercise 3.3 Please choose a website (other than PTT) you are interested in and demonstrate how you can use R to retrieve textual data from the site. The final scraped text collection could be from only one static web page. The purpose of this exercise is to show that you know how to parse the HTML structure of the web page and retrieve the data you need from the website.