Corpus-based Distributional Data for Linguistic Generalization:
Frequency and more?
Alvin Cheng-Hsien Chen 陳正賢
National Taiwan Normal University
Alvin Cheng-Hsien Chen 陳正賢
National Taiwan Normal University
Feb. 17, 2023
Corpus-based Apporach to Linguistic Analysis
- Frequency counts have been one of the central distributional properties extensively used in corpus linguistic analysis.
- These include the frequency counts of words, multiword combinations, constructions/structures, or some other linguistic structures/phenomena.
Corpus-based Distributional Properties
- Two types of distributional properties are most
often extracted from corpus data:
- occurrences
- cooccurrences
- Gries, Stefan Th. 2017. Quantitative Corpus Linguistics with R: A Practical Introduction. Second Edition. New York and London: Routledge.
- The occurrences of a particular linguistic unit
- e.g., morphemes, words, grammatical patterns
- The cooccurrences as the conditional
distribution of linguistic units/phenomena
- How often does a morpheme cooccur with a particular word?
- How often does a word cooccur with a particular construction?
- How often does a word/construction cooccur with a particular register/genre?
- These occurrences and cooccurrences data often serve as empirical support for linguistic hypotheses。
- Stefanowitsch (2019) defines Corpus Linguistics as “the investigation of linguistic research questions that have been framed in terms of the conditional distribution of linguistic phenomena in a linguistic corpus”.
In addition to frequency, what else?
- Studies have shown that speakers are sensitive to more subtle distributional/statistical properties in language use.
- Frequency counts may only capture one aspect of our native intuition (i.e., Which linguistic structure is more frequently used?)
- Ellis, Nick C, Matthew Brook O’Donnel & Ute Römer. 2014. The processing of verb-argument constructions is sensitive to form, function, frequency, contingency, and prototypicality. Cognitive Linguistics 25(1). 55–98.
- Usage-based studies have highlighted a few important aspects of our statistical native
intuition:
- Exclusivity
- Dispersion
- Directionality
- We will illustrate these ideas with the examples of two-word collocations.
- Gablasova, D., Brezina, V., & McEnery, T. (2017). Collocations in corpus-based language learning research: Identifying, comparing, and interpreting the evidence. Language Learning, 67, 155–179.
A Quick Example
- Data Source:
- English: Corpus of Contemporary American English (COCA)
- Chinese: Academia Sinica Balanced Corpus of Mandarin Chinese (Sinica Corpus)
- Target: Two-word combinations (Contiguous Bigrams)
- Research Question: Representative Collocations
A Naive Start
- Create a frequency list of two-word combinations based on the native corpus


While the frequency list may reflect our intuition, they may contribute little to the research question.
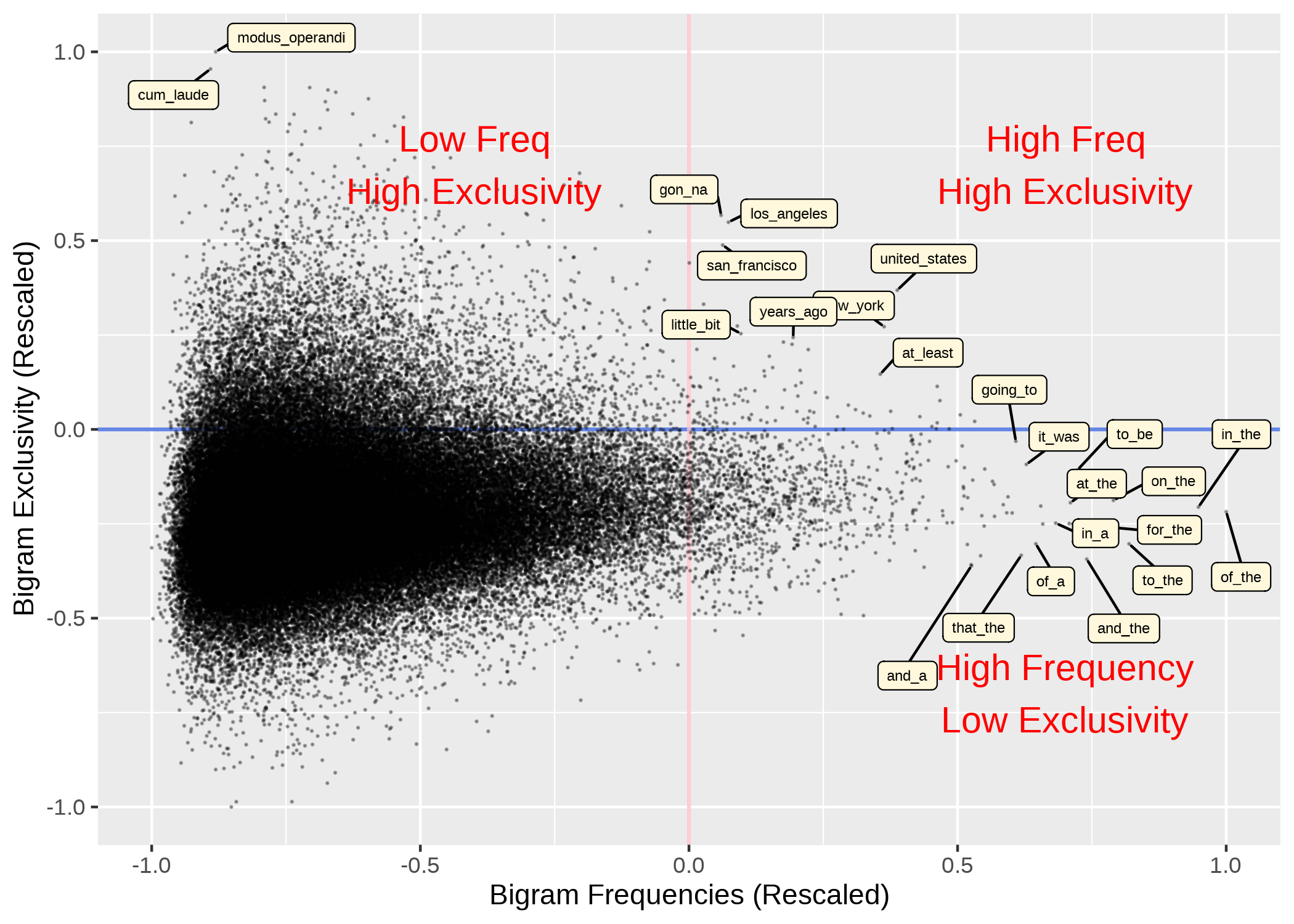
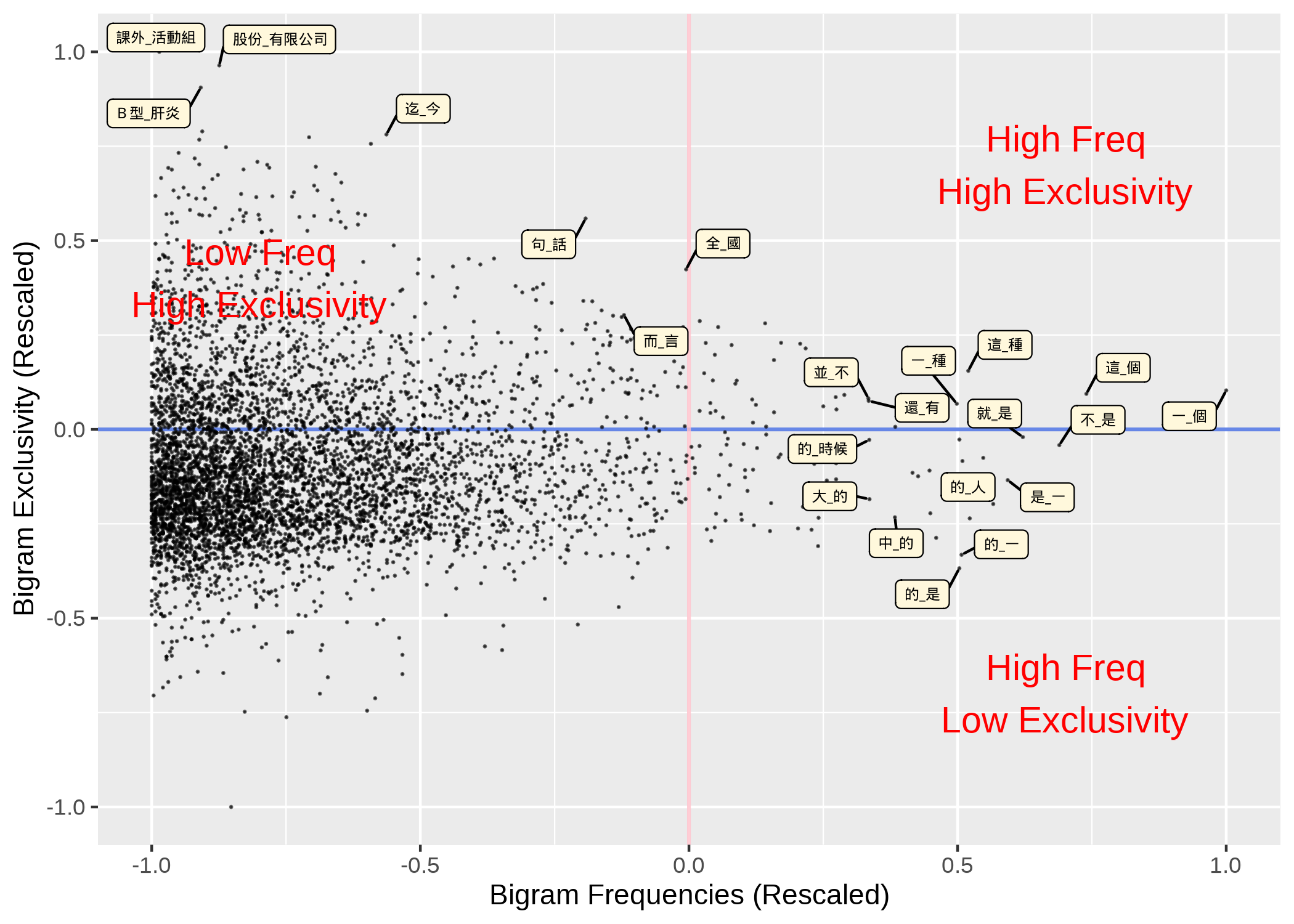
Exclusivity
- High-frequency of the two-word combinations may not necessarily reflect the strong lexical associations.
- It is indeed a statistical evaluation. Many statistical metrics can be used, e.g., MI and LLR.
Now what if we add exclusivity to the analysis:
Dispersion
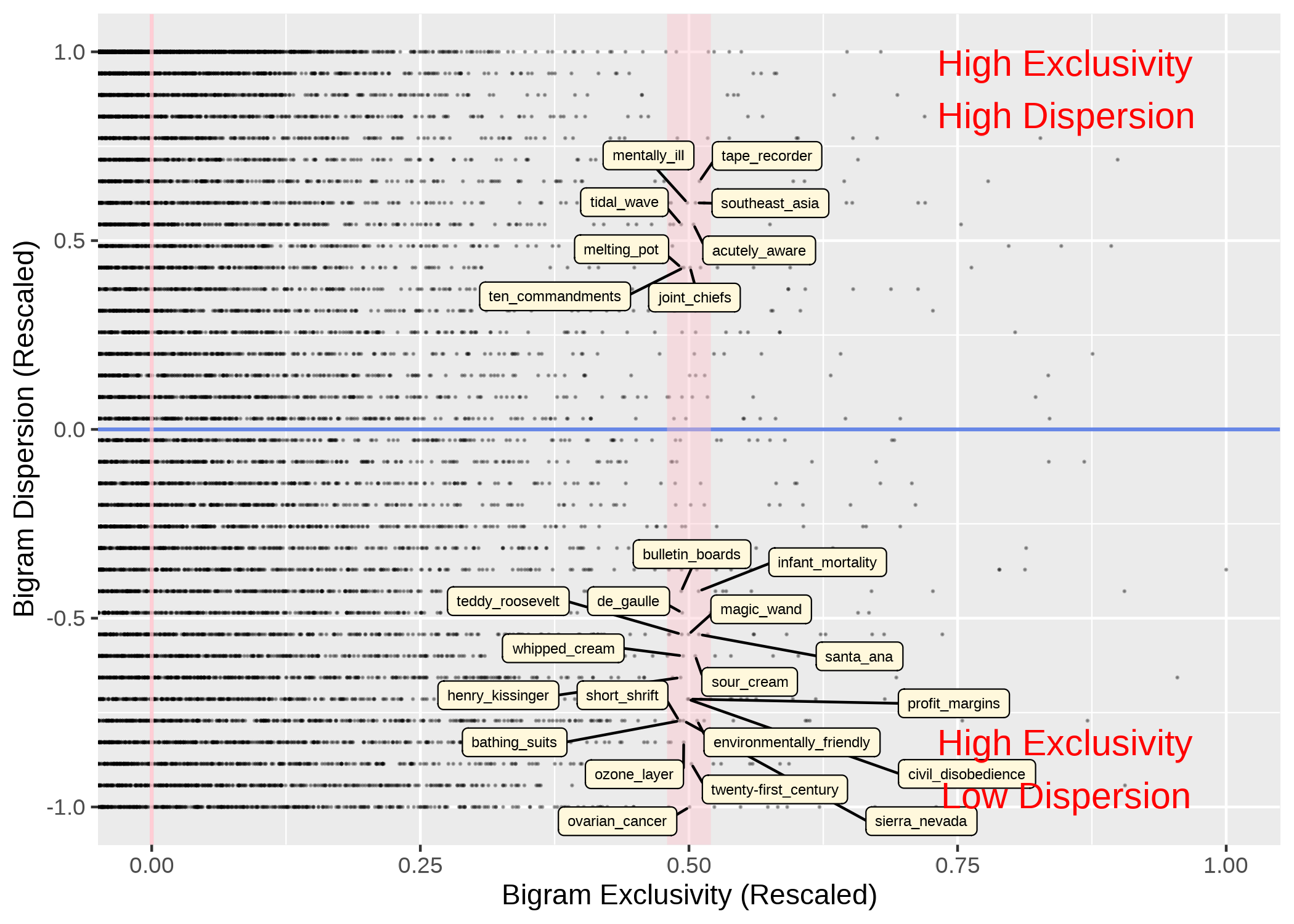
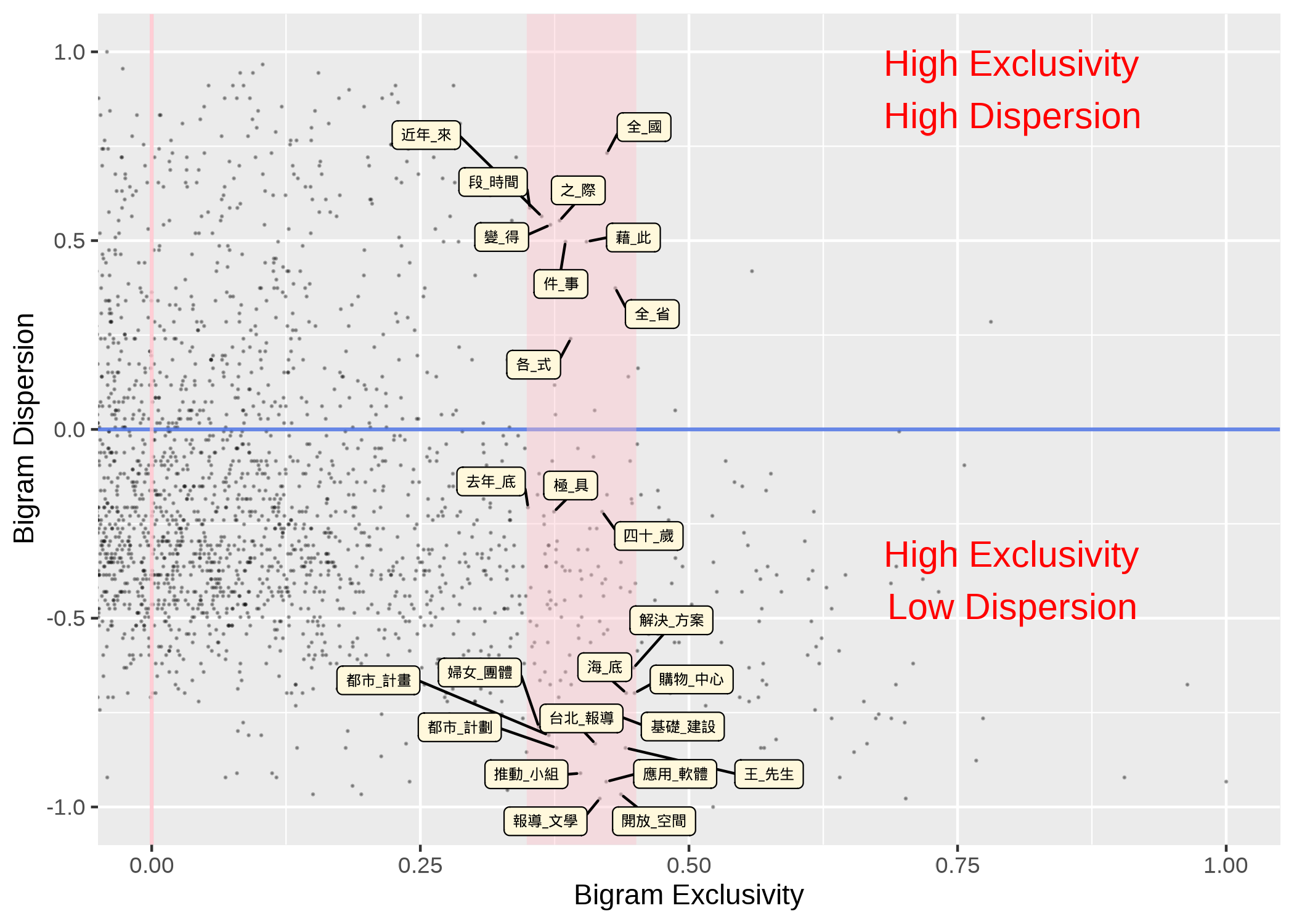
- A linguistic structure can be evenly distributed across the documents of the corpus or specific to only a few documents/authors/registers etc.
- Domain-general vs. Domain-specific?
- Many quantitative metrics can be used, e.g., range, inverse document frequency, delta P.
Now if we add dispersion to our analysis:
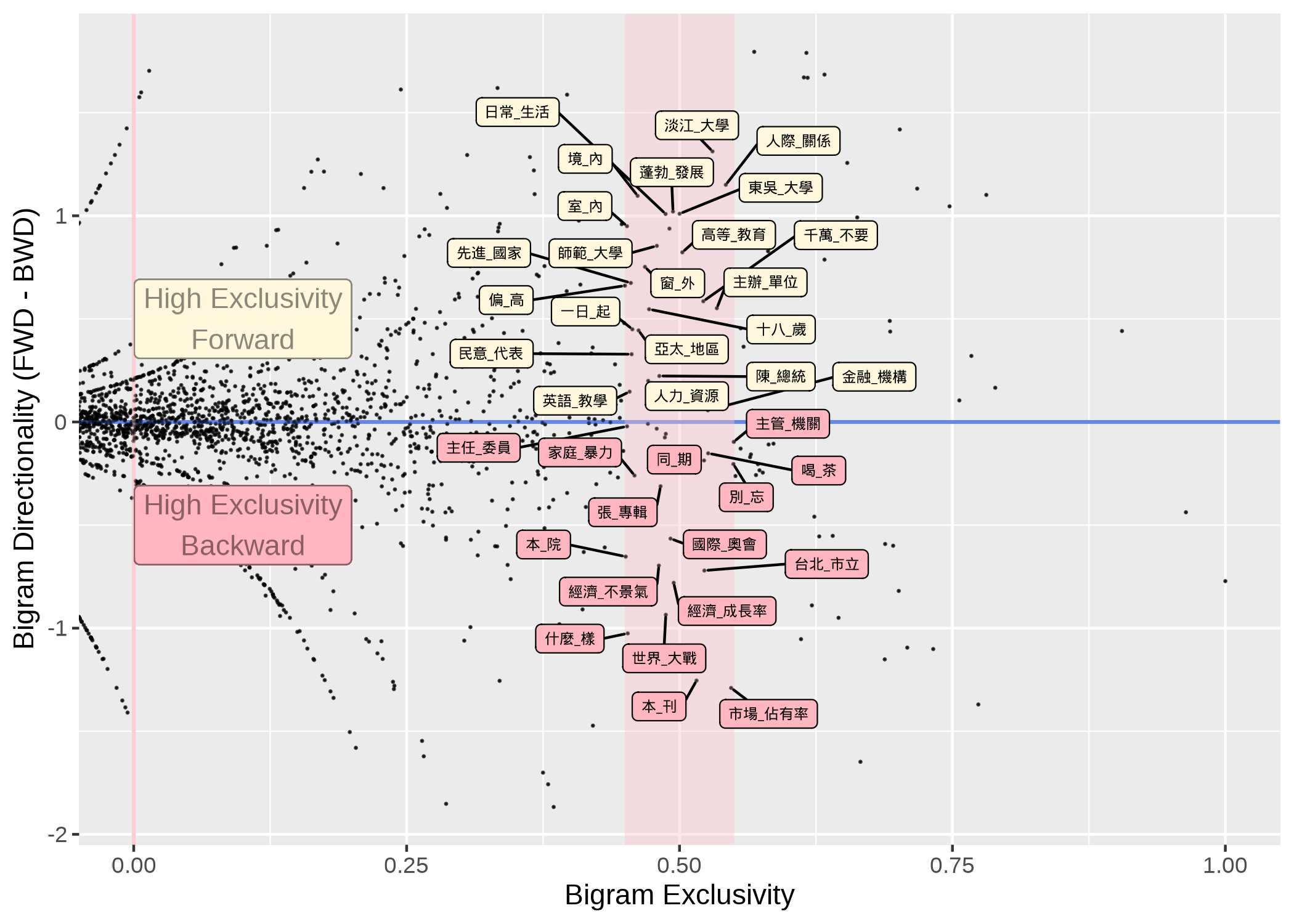
Directionality
- When two words are attracted to each other (i.e., high exclusivity), their lexical association may be asymmetrical (e.g., apply for vs. at home)
- Many metrics can be used: delta P, surprisal, transitional probability.
If we add directionality to our analysis:
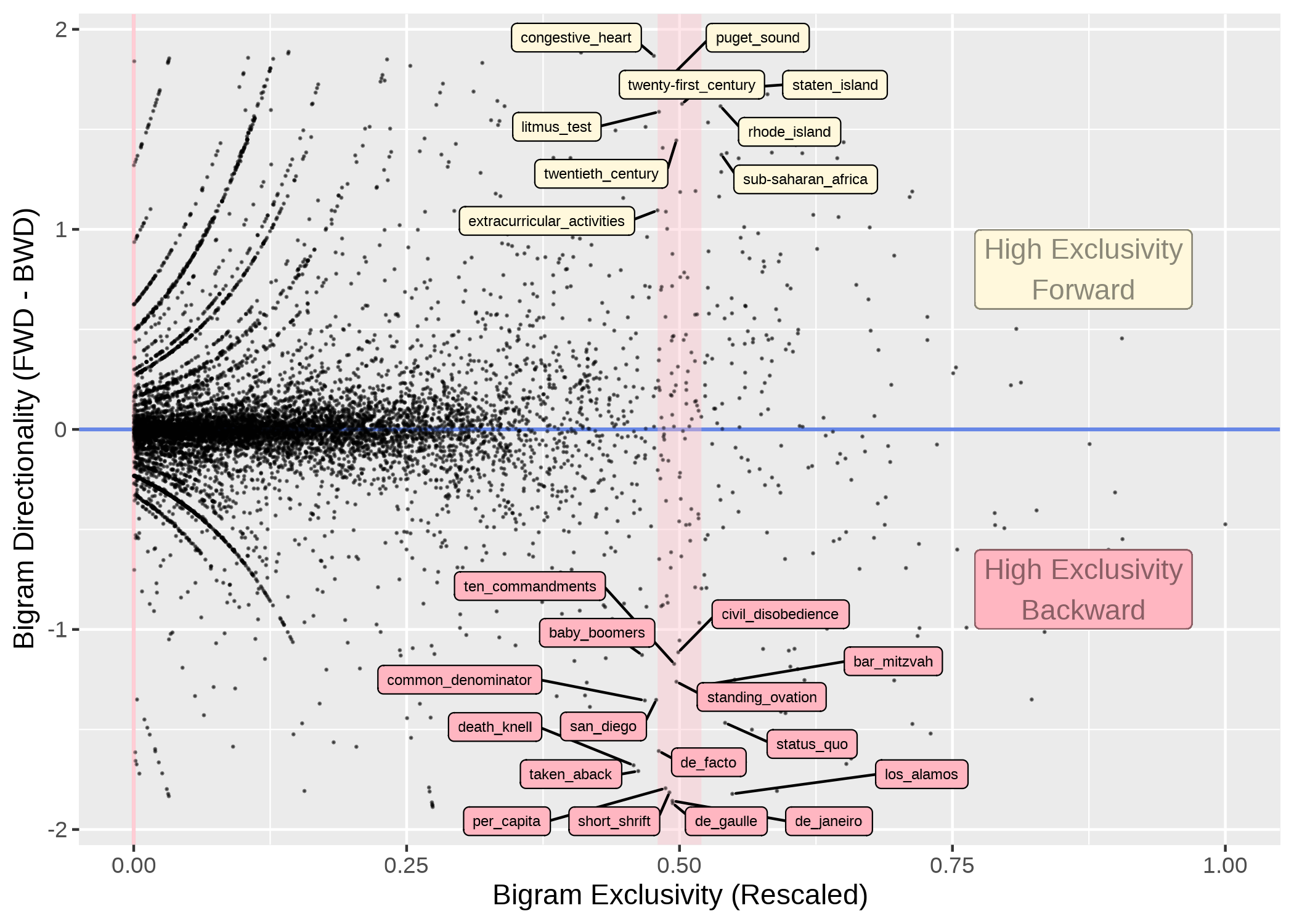
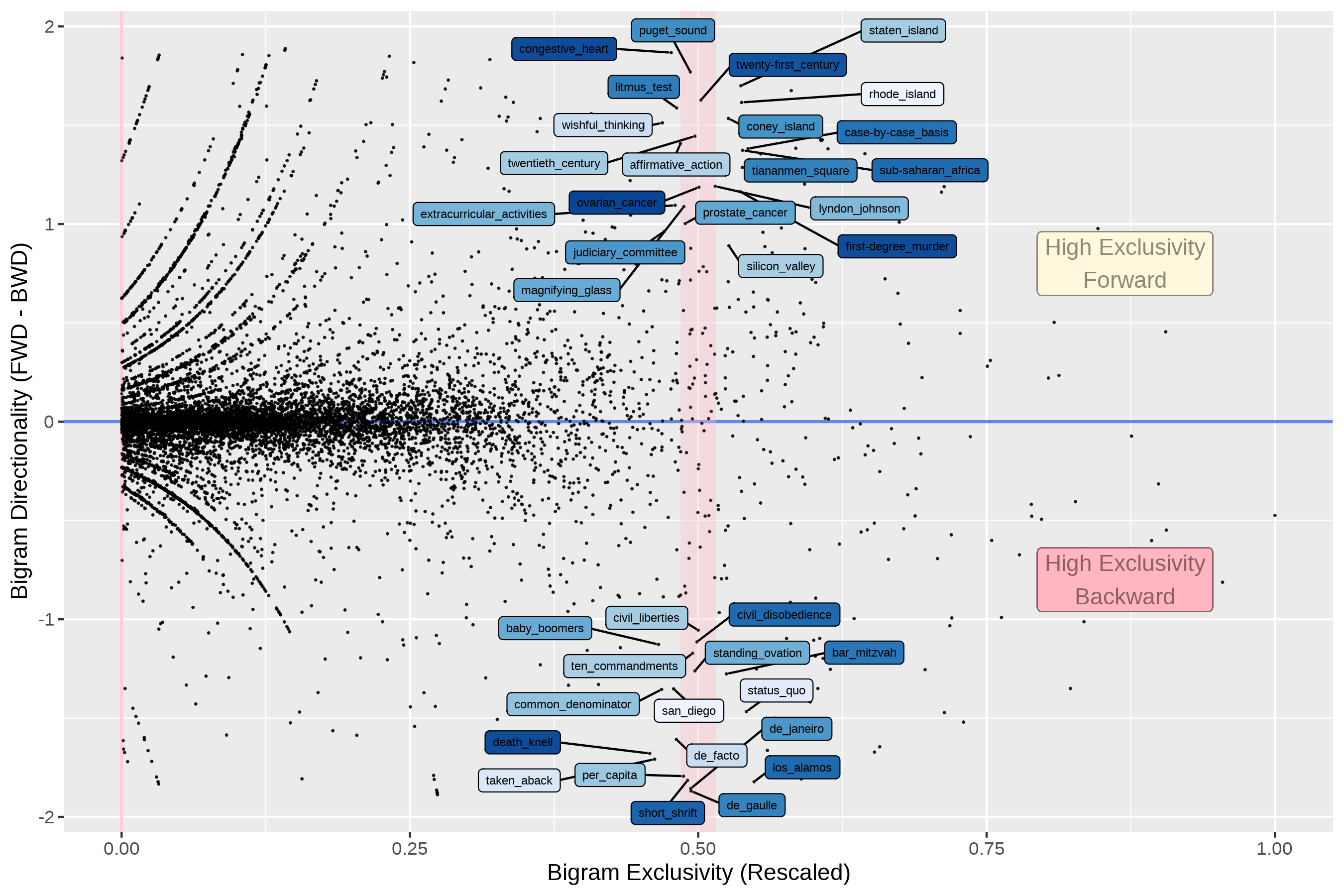
An Integrated Analysis
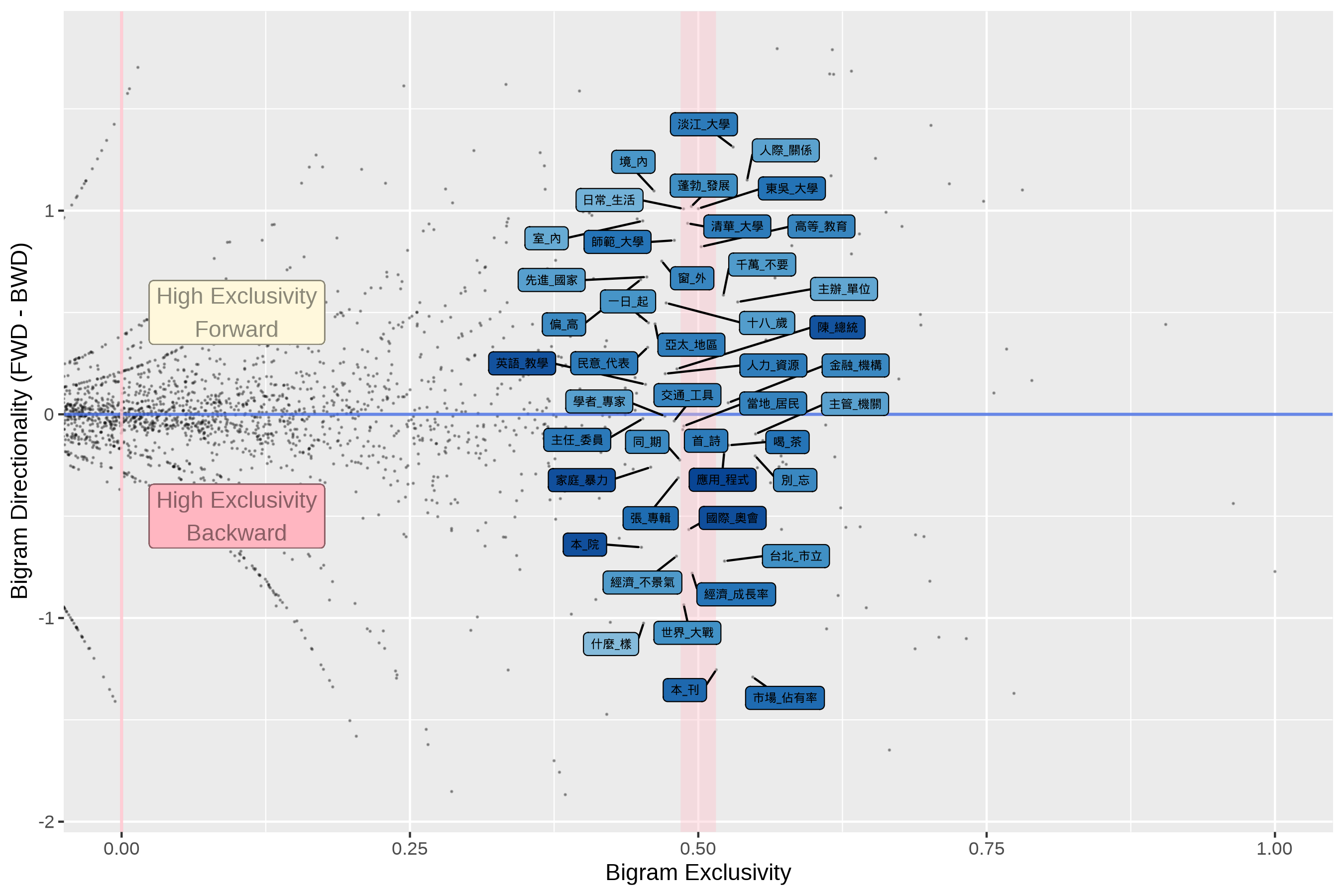
Frequency and more?
- To identify representative two-word combinations, one may need to consider distributional properties at multiple dimensions.
- A representative combination may need to demonstrate considerably high frequency and exclusivity with wide dispersion.
- The directionality of combination’s lexical association may lead to more diverse representative sets of combinations as well.
L2 Acquisition of Multifaceted Native Intuition
- We have observed a similar development in L2 data as well.
- L2 learners demonstrate increasing sensitivity to the multifaceted statistical distributional properties in their L2 production (written essays).
- Chen, A. C.-H. (2022).Assessing L2 learner’s multifaceted collocation competence: A comparative analysis of Chinese and English L2 learners’ essays. EUROCALL2022, Reykjavik,16–19 August 2022.
- Chen, A. C.-H. (2021). Acquisition of L2 collocation competence: A corpus analysis of exclusivity, directionality, dispersion and novel usage. Taiwan Journal of TESOL,18(1),29–61.
L1 vs. L2 Comparative Study
- English Data
- Learner: International Corpus Network of Asian Learners of English (ICNALE)
- Native: Corpus of Contemporary American English
- Chinese Data
- Learner: The Test of Chinese as a Foreign Language (TOCFL)
- Native: Academia Sinica Balanced Corpus of Mandarin Chinese (Sinica Corpus)
Structure of Analysis
- All two-word combinations in L2 argumentative essays across different proficiency levels (CEFR)
- L1 Corpus as the proxy for native intuition (Exclusivity, Dispersion, Directionality)
- Evaluate the sophistication of L2 two-word combinations at different proficiency levels
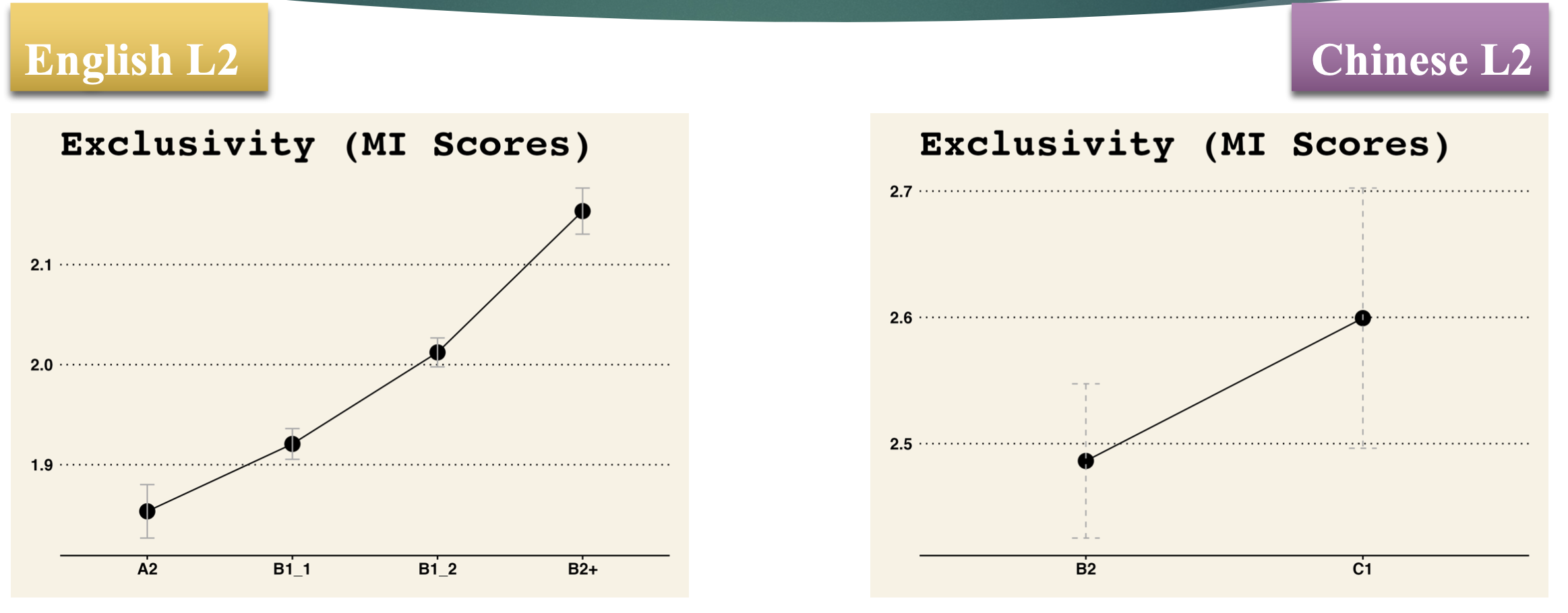
- As L2 proficiency level grows, the exclusivity of their two-word combinations grows as well.
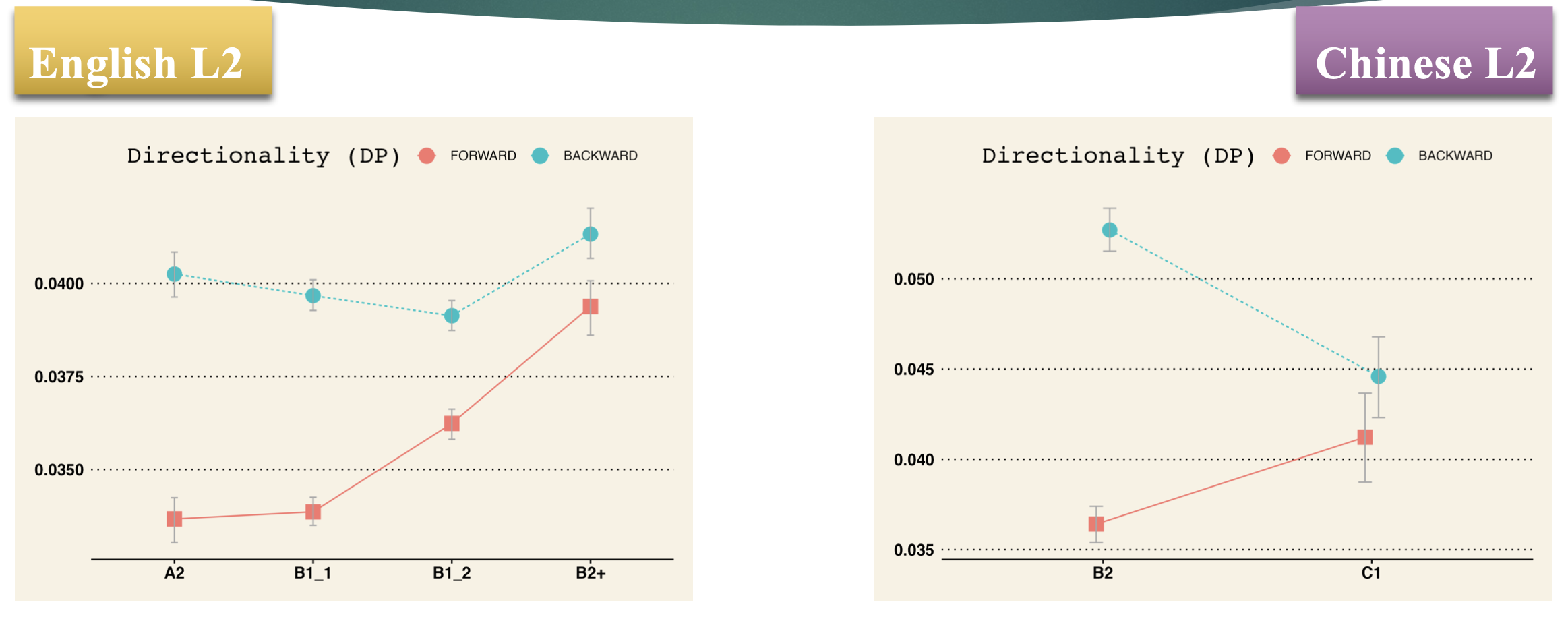
- Learners’ two-word combinations also become more and more sophisticated when their lexical associations are examined in bi-directional order (Forward-directed sophistication is more prominent.)
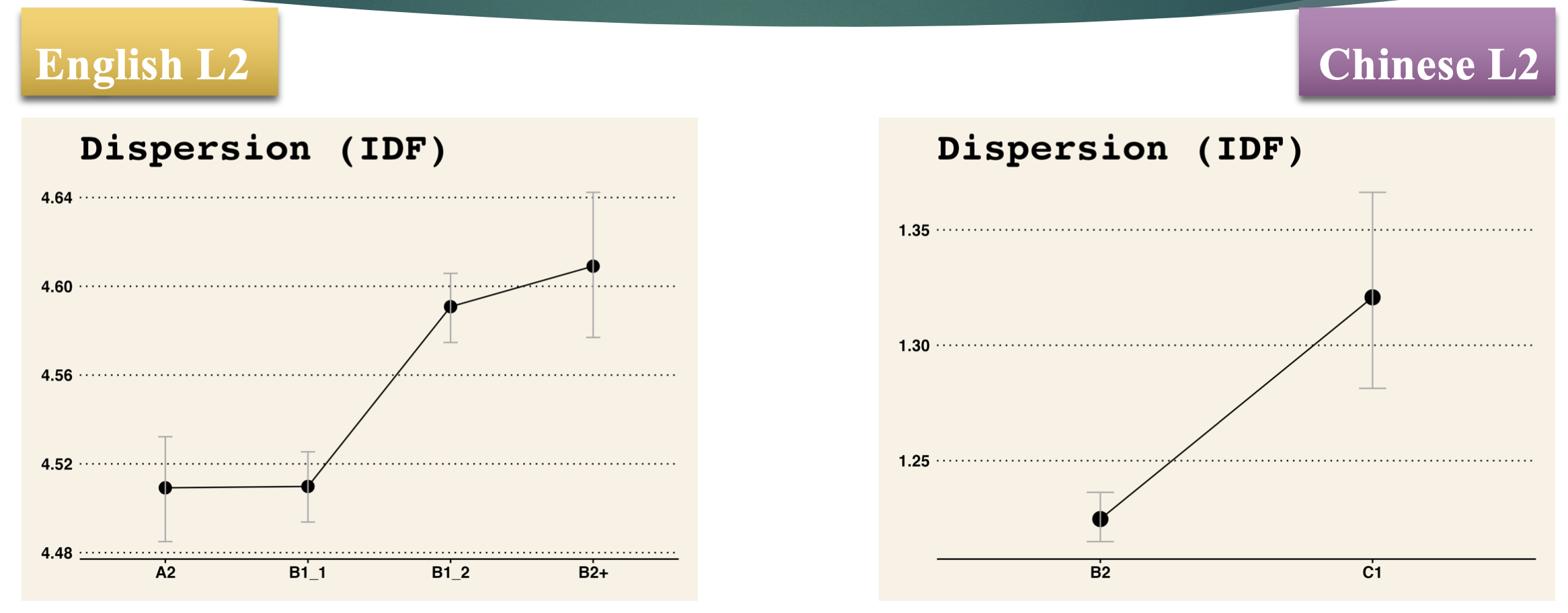
- As L2 proficiency level grows, the dispersion of their two-word combination develops as well.
- Advanced learners demonstrate greater capacity of domain-specific combinations.
Conclusions
- We cannot ignore the multifaceted nature of the corpus-based distributional properties.
- In particular, common corpus-based analyses (e.g., collocations, collexemes, keywords, lexical bundles/chunks) may need to consider dispersion and directionality in more comprehensive ways.
- The choice of a proper metric is always a non-trivial issue in CL.